









题目:输入n个整数,输出其中最小的k个
思路一、快速排序+遍历
先对n个整数快速排序,平均所费的时间为nlogn,之后再遍历序列中前k个元素的输出
(总的时间复杂度为O(nlogn+k) = O(nlogn))
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
思路二、选择排序+遍历
1、遍历n个数,把最先遍历到的k个数存入到大小为k的数组中,假设它们即使最小的k个数;
2、对这k个数利用交换排序找出这k个元素中的最大值kmax,时间复杂度为O(k);
3、继续遍历n-k个数,假设每一次遍历到的新的元素的值为x,把x与kmax比较:如果 x < kmax ,用x替换kmax,并回到第二步重新找出k个元素的数组中最大元素kmax‘;如果 x >= kmax ,则继续遍历不更新数组。每次遍历更新或不更新数组所用的时间为O(k),故整趟下来,时间复杂度为nO(k)=O(nk)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
思路三、维护容量为k的最大堆
1、用容量为k的最大堆存储最先遍历到的k个数,同样假设它们即是最小的k个数;
2、堆中元素是有序的,令k1<k2<...<kmax(kmax设为最大堆中的最大元素)
3、遍历剩余n-k个数。假设每一次遍历到的新的元素的值为x,把x与堆顶元素kmax比较:如果 x < kmax ,用x替换kmax,然后更新堆(用时logk);否则不更新堆。总的时间复杂度为O(nlogk)
与思路二的区别在于堆中进行查找和更新的时间复杂度均为O(logk),但是在数组中找出最大元素,时间复杂度为O(k).
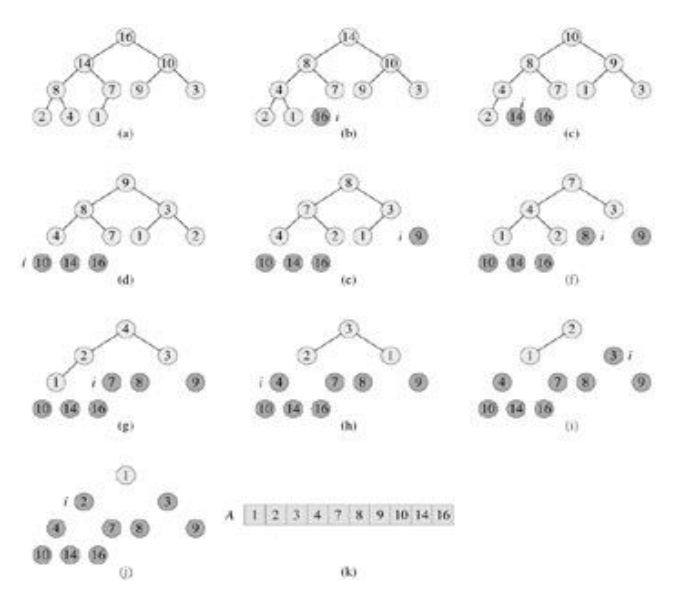
注意一个误区:并不是取出堆顶元素之后,把原来堆顶元素的儿子送到堆顶,而是如图所示,16被删除之后,堆中的最后一个元素1代替16成为了根结点,之后1下沉,14上移到堆顶(这个是算法导论中的分析,不一样的是这里是最大堆的堆排序过程)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
参考代码:
//找出最小k个数.cpp
#include <iostream>
const int MAXLEN = 8;
const int K = 4;
using namespace std;
//建立k个元素最大堆
void HeapAdjust(int array[], int i, int Length)
{
int child,temp;
for(temp = array[i]; 2*i+1 < Length; i = child)
{
child = 2 * i + 1;
if(child < Length - 1 && array[child + 1] < array[child])
child ++;
if(temp > array[child])
array[i] = array[child];
else
break;
array[child] = temp;
}
}
//交换
void Swap(int *a, int *b)
{
*a = *a ^ *b;
*b = *a ^ *b;
*a = *a ^ *b;
}
//得到最小
int GetMin(int array[], int Length, int k)
{
int min = array[0];
Swap(&array[0], &array[Length - 1]);
int child,temp;
int i = 0,j = k-1;
for(temp = array[0]; j > 0 && 2*i+1 < Length; --j,i = child)
{
child = 2*i+1;
if(child < Length - 1 && array[child + 1] < array[child])
child++;
if(temp > array[child])
array[i] = array[child];
else
break;
array[child] = temp;
}
return min;
}
void Kmin(int array[], int Length, int k)
{
for(int i = Length/2 - 1; i >= 0; --i)
//初始建堆,时间复杂度为O(n)
HeapAdjust(array, i, Length);
int j = Length;
for(int i = k; i > 0; --i,--j)
//k次循环,每次循环的复杂度最多为k次交换,复杂度为O(k^2)
{
int min = GetMin(array,j,i);
cout << min << endl;
}
}
int main()
{
int array[MAXLEN] = {13, 38, 49, 76, 97, 27, 65, 49};
//for(int i = MAXLEN; i > 0; --i)
// array[MAXLEN - i] = i;
Kmin(array, MAXLEN, K);
return 0;
}
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
思路四、类似快速排序的partition过程的分治算法
——《数据结构与算法分析--c语言描述》一书,第7章第7.7.6节中快速选择算法
1)类似快速排序的划分方法N个数存储在数组S中,再从数组中随机选取一个数X作为枢纽元,2)把剩下的数组划分为Sa和Sb两个部分,Sa<=X<=Sb,
3)如果要查找的k个元素小于等于Sa的元素个数,那么第k个最小元肯定在Sa中则返回Sa中较小的k个元素
4)否则第k个最小元在Sb中,返回Sa中所有元素+Sb中小的k-|Sa|个元素
参考代码:
//采用类似快速排序的partition过程的分治算法.cpp
void q_select(int a[], int k, int left, int right)
{
int i,j;
int pivot;
if(left + CUTOFF <= right)
{
pivot = median3(a,left,right);//取三个中值作为枢纽元
i = left;
j = right - 1;
for(; ;)
{
while(a[++i] < pivot);
while(a[--j] > pivot);
if(i < j)
swap(&a[i], &a[j]);
else
break;
}
//重置枢纽元
swap(&a[i], &a[right-1]);
if(k <= i)
q_select(a, k, left, i - 1);
else if(k > i+1)
q_select(a, k, i+1, right);
}
else
insert_sort(a + left, right - left + 1);
}
注意:快速排序与快速选择一样,如果枢纽元选择不当,以至于S1或S2中有一个序列是空的,则依然会有最坏的运行时间O(N^2)的情况发生,上述使用三数中值作为枢纽元的方法可以避免这个情况发生,可以做到O(N)的复杂度
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
思路五、随机选取数列中的一个元素作为主元+遍历输出k个小的元素
——《算法导论》
每次都是随机选取数列中的一个元素作为主元,在O(n)的时间内找到第k小的元素,之后遍历输出前面的K个小的元素,比较一下熟知的快速排序,是以固定的第一个或最后一个元素作为主元,每次递归划分都是不均等的,最后的平均时间复杂度是O(nlogn)
思路六、五分化中项的中项法
——《算法导论》
像RANDOMIZED-SELECT一样,SELECTT通过输入数组的递归划分来找出所求元素,但是,该算法的基本思想是要保证对数组的划分是个好的划分。SECLECT采用了取自快速排序的确定性划分算法partition,并做了修改,把划分主元元素作为其参数
具体思路:
1)将输入数组的n个元素划分成n/5组,每组5个元素,且最后一个组存放n%5个元素。
2)寻找n/5个组中每一组的中位数,首先对每组中的元素(至多为5个)进行插入排序,之后选出中位数
3)对第2)步中找出的n/5个中位数,递归调用SELECT以找到其中位数x
4)按中位数的中位数x对输入数组进行划分,让k比划分低区的元素多1,所以x是第k小的元素,并且有n-k个元素在划分的高区
5)如果i = k,则返回x,否则如果i<k,在低区递归调用SELECT以找出第i小的元素;如果i>k,则在高区找第i-k个最小的元素。















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









