






文章摘要:统计语言模型通过学习来得到语言中某个序列联合概率分布,但是由于一个序列可能看上去和训练集中其他所有的语言序列都不相同,而且这种现象可能大量存在,这样的话就会存在一个维度爆炸(curse of dimensionality)的问题,也就是语言模型过于稀疏。传统的N-gram模型在语言模型中取得了一定的成功,但也无法避免稀疏性的问题。本文旨在提出一种稠密低维度的词的表达方式,使得输入每一个测试的语句,都让模型得到大量的语义相关的语句。对于从未出现过的句子,只要这些词是相似的那么这样的词序列也能得到很高的概率。文章使用神经网络来拟合概率函数(百万个参数),结果表明比任何N-gram模型都有明显的性能的提升。
提出的背景:
对于海量大小的词集,如果我们仅仅做词与词之间的硬匹配的话,那么就会带来维度爆炸的问题,仅仅是连续的10个词语就会
1050−1
大小的自由参数需要去估计,这显然是稀疏的也是高维的。而且词向量连续型的表示也更加容易建模,对于词向量离散编码的情况则会对任何变化都十分敏感。当词向量的离散型取值范围一旦变大就会使得对于任意观察到的两个词向量的hamming distance都十分大,这样也就难有区分度。
N-gram模型特性:由于一搬我们设N=3,而对于长序列的估计使用的是胶水效应的生成模型,这样由一个问题就是可能对于语言的学习视角过于狭窄,因此性能上有所局限;其次就是这个模型没有考虑词与词之间的相似性,这样对于一些最简单句子中的相近主谓宾的替换未必能够达到很好的识别。e.g. “The cat is walking in the bedroom.”和 “A dog was running in a room.”意思上是相近的,为“dog”和“cat”是相似的,“the”与“a”等等都是相似的。
大致流程:
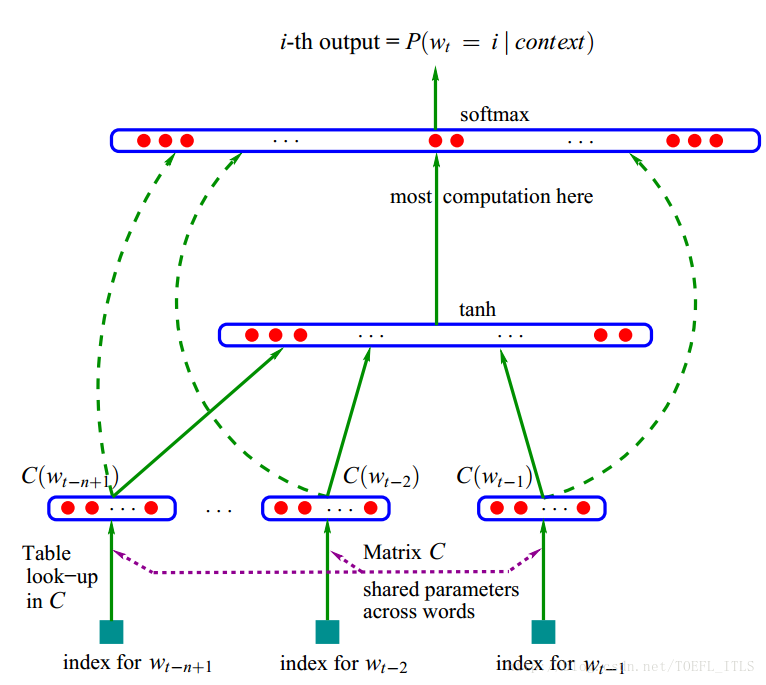
Step 1:先将每一个词和一个实数稠密向量(文章中用了30,60和100维)关联起来
Step 2:对各个词的向量表示通过串联形成的序列来求一个联合概率密度(链式法则,乘积形式)分布
Step 3:最后同时更新学习词向量的表达形式和概率函数的参数
模型好处在于:相似的词的距离会相对较小,而且某种程度上可以通过向量运算来表达词与词之间的关系,例如“queen”-“woman”+“man”=“king”;
文章主要观察的是词序列的分布,而不是学习词在句子中所代表的成分。
训练集:词序列
w1,w2,...,wT
,
wt∈V
,
V
是词集。
目标是学习一个好的模型使得
分成两部分来进行计算:
1.
C∈R|V|×m
代表了一个词库矩阵,每一行对应了一个词向量,因此第一步先将每一个词转化为一个词向量
2.将n-1个词向量按顺序形成一个序列,因此原问题转化为,在已知序列(
Cwt−n+1,...,Cwt−1
)的情况下,下一个词向量为
Cwt
的概率
f(i,wt−1,..,wt−n+1)=g(i,Cwt−n+1,..,Cwt−1)
这样我们就实现了将概率密度函数
f
用一个共享词库矩阵和一个神经网络来表示了
这里的
本文采用了一个三层的神经网络去做这件事情
网络的第一层(输入层)是将
Cwt−n+1,...,Cwt−1
这 n−1 个向量首尾相接拼起来,形成一个 (n−1)m 维的向量,下面记为 x。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用
d+Hx
计算得到。
d
是一个偏置项。在此之后,使用
tanh
作为激活函数。
网络的第三层(输出层)一共有
|V|
个节点,每个节点
yi
表示 下一个词为
i
的未归一化 log 概率。最后使用 softmax 激活函数将输出值 y 归一化成概率。最终,y 的计算公式为:

其中
模型至此已经建立完毕了!那该如何去训练这个模型呢?
首先我们得给出训练的损失函数
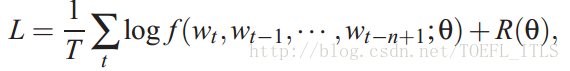
R(θ)
为正则项,用于防止过拟合
b∈R1×m
: the vector of biases
W∈R|V|×(n−1)m
:the word features to output weights
U∈R|V|×h
:the hidden-to-output weights
d∈R1×h
:the vector of hidden units biases
H∈Rh×(n−1)m
:the hidden layer weight matrix
迭代更新:
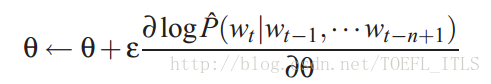
前向过程:

反向传播:


模型训练
数据并行:each processor works on a different subset of the data.
参数并行:所有数据各自对参数进行更新,然后上传到中央服务器上,最终完成参数的并行更新。
能量函数:输入一个词序列,当词序列的合理时候就会使得E变得很小,反之就会很大。
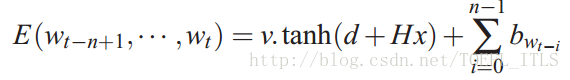














 1644
1644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









