







实战解析Spark运行原理和Rdd解密
分布式 基于内存(在一些情况下也会基于硬盘) 特别适合于迭代运算的运算框架
大数据计算问题:
交互式查询:shell,sql
流处理:
批处理:基于spark RDD直接编程,
机器学习、图计算,
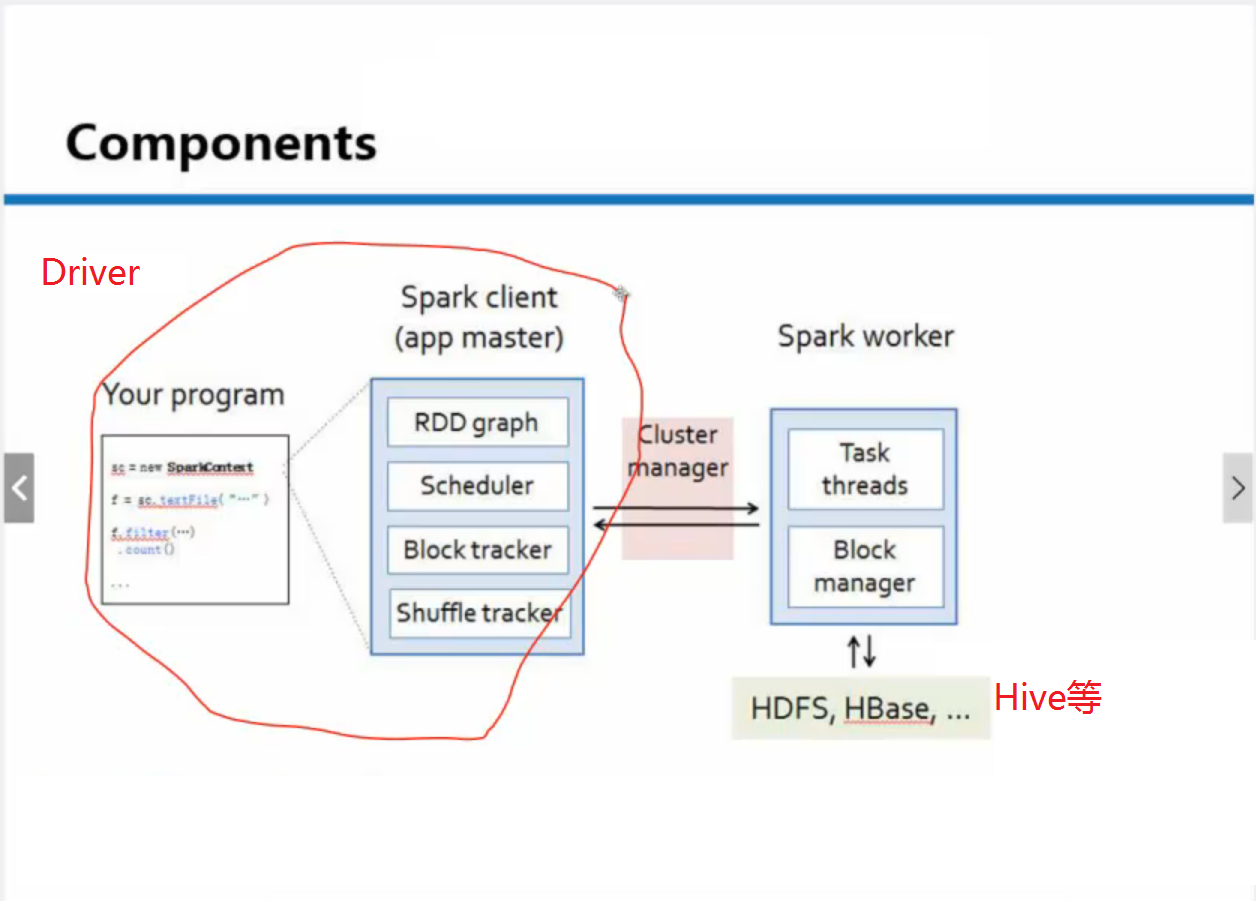
理解spark:
1、分布式
Driver端(客户端)提交给集群
2、主要基于内存
3、迭代式计算(精髓)
Driver、Worker
Hadoop每次读写
Spark优先从内存中找
DAGScheduler 调度器
Scala/Java都可以
容易容易
容易维护
处理数据来源:HDFS, HBASE, HIVE, DB
处理数据输出:HDFS, HBASE, HIVE, DB, Spark Driver
s3等
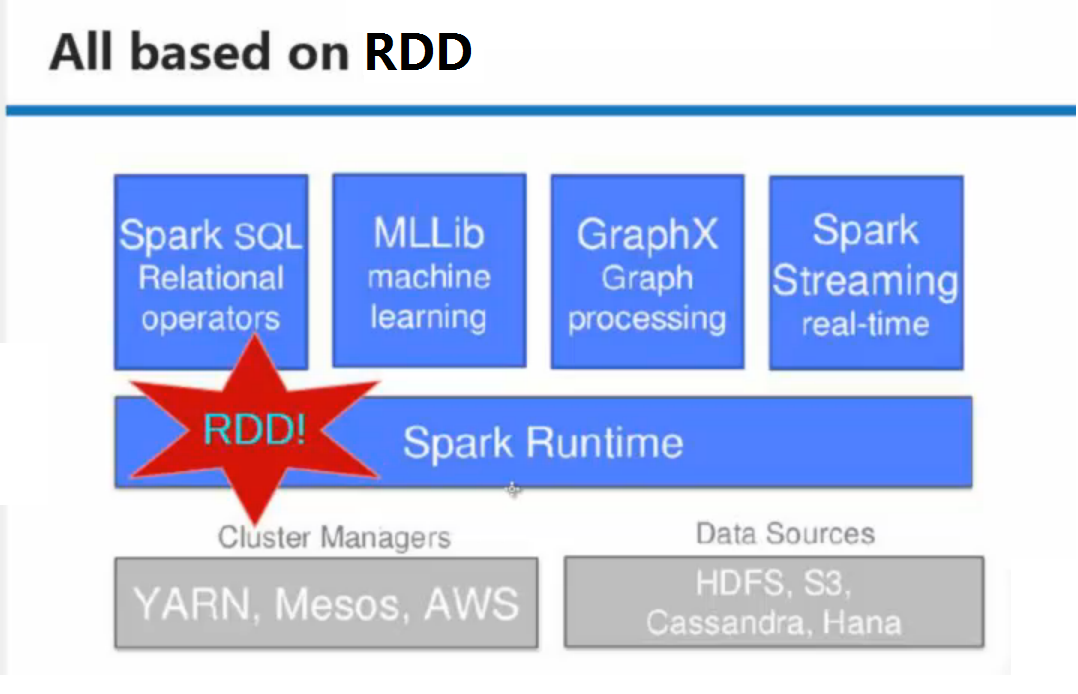
RDD 弹性分布式数据集 XXX Distributed Datasets
弹性之一:自动进行磁盘和内存数据存储的切换
弹性之二:基于lineage的高效容错,不需要从头开始计算
弹性之三:Task如果失败会自动进行特定次数的重试
弹性之四:Stage如果失败会自动进行特定次数的重试,且只计算失败的分片
缓存时机:
1、特别耗时
2、计算链条很长
3、shuffle之后
4、checkpoint之前
一个RDD分区会放在Spark不同机器的节点上
>val data = sc.textFile("/library/wordcount/input/Data")
data.toDebugString一些列分片的数据分配在不同的节点
data.count
val flatted = data.flatMap(_.split(" "))
flatted.toDebugString
val mapped = flatted.map(word => (word, 1))
mapped.toDebugString
val reduced = mapped.reduceByKey(_+_)
reduced.toDebugString
reduced.saveAsTextFile














 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









