







RDD持久化、广播、累加器
action操作:
常用action:reduce, count, take, collect, countByKey, saveAsTextFile
凡是actoin级别的操作都会触发sc.runjob
一个spark应用程序可以有很多个job,hadoop中只有一个
val numbers = sc.parallelize(1 to 100)
numbers.reduce(_ + _)
val result = numbers.map(2*_)
val data = result.collect
numbers.count()
val topN = numbers.take(5)
val scores = Array(Tuple2(1, 100), Tuple2(1, 100), Tuple2(2, 100), Tuple2(2, 100), Tuple(3,100))
val data = sc.parallelize(scores)
val content = data.countByKey
countByKey,有collect,所以是action,是用来数key的个数最有用的是saveAsTextFile
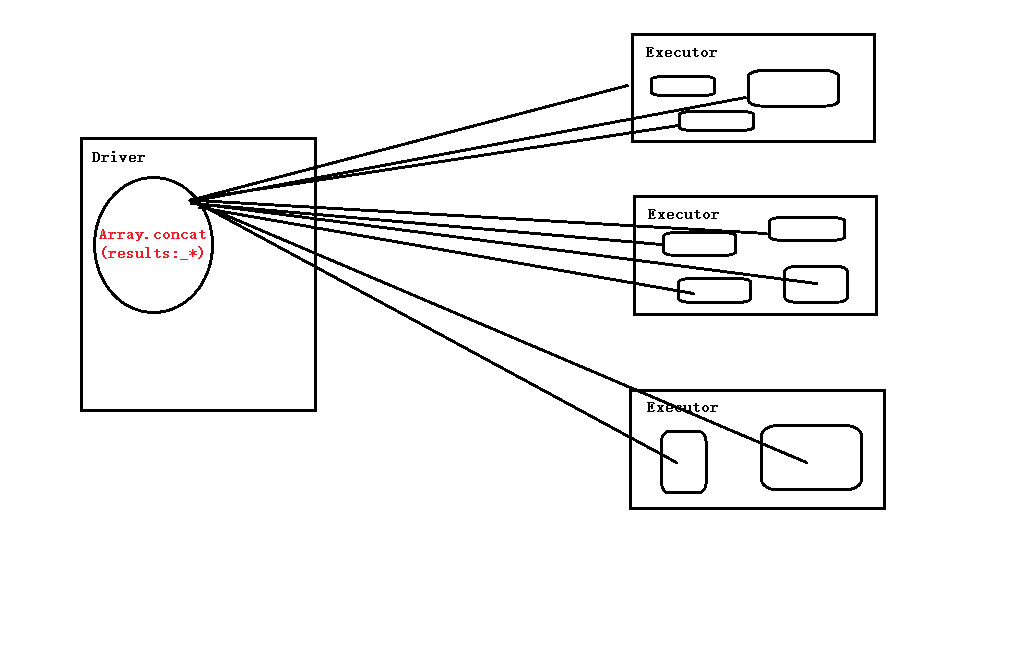
持久化:
分布式出错非常多,需要容错。在必要步骤需要persist和cache
persist的使用情况
1、在某个步骤十分耗时的情况
2、计算链条特别长的情况
3、checkpoint所在的RDD也一定要持久化数据
4、shuffle之后,因为shuffle要进行网络传输,容易出错
5、shuffle之前(框架默认帮助我们把数据持久化到本地磁盘)
checkpoint会触发一个新的job。
序列化:减少数据体积,节省空间。
缺点:反序列化耗cpu
STORAGE_LEVEL:
MEMORY_ONLY 只放在内存,容易内存溢出(OOM)
MEMORY_AND_DISK 优先考虑内存,内存不够放硬盘
cache之后一定不能立即有其他算子
cache不是action。因为运行后没有执行作业
persist是lazy级别的,unpersist是eager级别(立即)
序列化性,google kyoro?
persist可以指定级别:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false)广播:
为什么进行广播?同步、减少通信、冗余、大变量、join等原因
默认情况下task运行时要拷贝一份变量的副本,因为函数式编程数据不变。
广播过去的内容不可修改
广播给executor的内存中。减少网络传输,节省内存,减少OOM的可能
广播是由Driver发给当前Application分配的所有Executor内存级别的全局只读变量,Executor中的线程池中的线程共享该全局变量,极大的减少了网络传输(否则的话每个Task都要传输一次该变量)并极大的节省了内存,当然也隐性的提高了cpu的有效工作
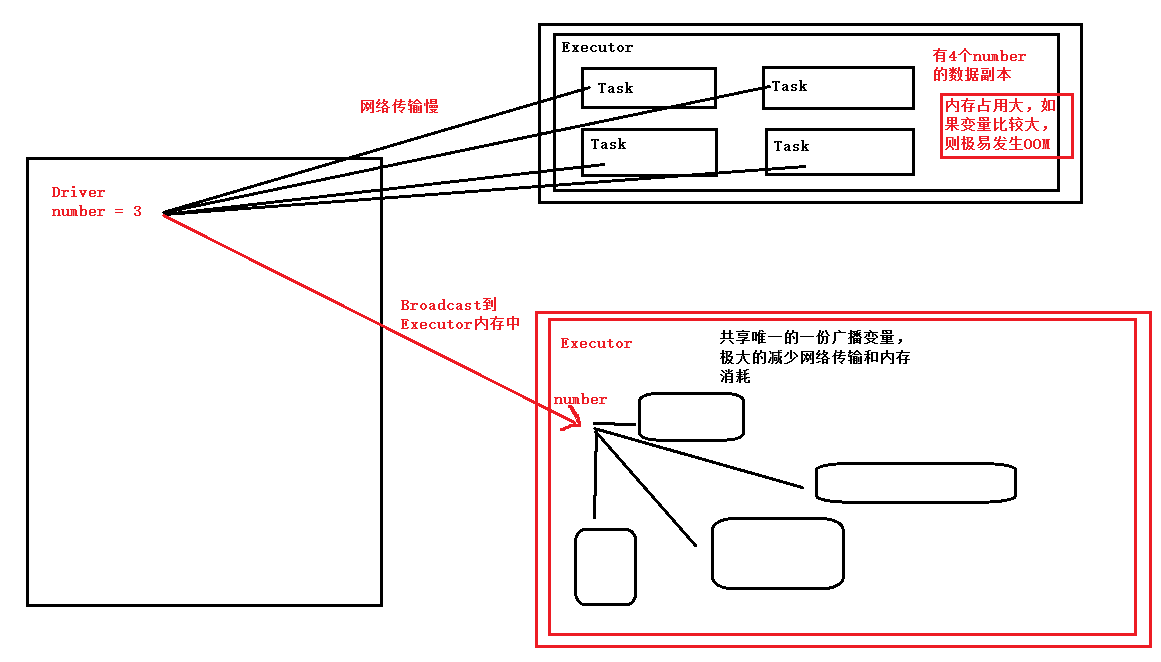
Executor共享数据通过HDFS或Tachyon,
Executor是一个进程,资源独立不能共享
val number = 10
val broadcastNumber = sc.broadcast(number) //声明广播变量
val data = sc.parallelize(1 to 10000)
val bn = data.map(_ * broadcastNumber.value)累加器Accumulator:
task拥有副本运行起来
accumulator通过SparkContext创建,内部有锁
累加器全局唯一,每次操作只增不减。Executor只能增加,Driver能读取
val sum = sc.accumulator(0)
val data = sc.parallelize(1 to 5)
val result = data.foreach(item => sum += item)
println(sum)














 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









