







Spark性能优化第十季之Spark统一内存管理
1、传统的Spark内存管理的问题
2、Spark统一内存管理
3、展望
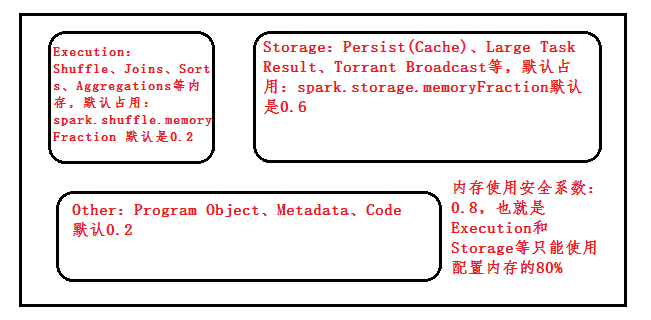
Spark内存分为三部分:Execution、Sotrage、Other;
Shuffle,当内存不够的时候下,磁盘IO很大负担
10个Task并行,则会把内存分为10份,实际运行时Task可能会沾满整个空间,其他任务分配不到空间。
即使一个Task不会把内存用完,另外一个Task申请内存,它有一个算法,如果申请的内存不够,Task不会自动Spill到disk,默认放一部分数据到内存中,有个百分比,这样不断重复,既消耗CPU又消耗内存。
这时就要Spill到磁盘
1、分布式系统的性能杀手是Shuffle,join、aggregation可能需要用很大内存,但是给他分配的很少,这不是有效的内存使用方法
2、假设需要Spill,计算时还要从磁盘读到内存,这时磁盘IO是不能承受的
3、Storage空间不够,计算结果丢失可能需要重新计算
4、假设Task占满内存,其他Cores都在空闲状态
5、即使Spill数据到磁盘,它还是要申请一部分百分比的空间放一部分数据的
Execution分配内存:
ShuffleMemoryManager、TaskMemoryManager、ExecutorMemoryManager
最安全、廉价的STORAGE_LEVEL是MEMORY_AND_DISK_SER
Iterator一条一条读取数据叫Unroll,无法一次性把所有的数据放进去,因为可能OOM。Unroll的内存空间是从Storage空间中获得的,Unroll过程中会放尽量多的数据放入Storage中,Spark给了它一个参数,spark.storage.unroll.fraction默认也是0.2;unroll失败的话则直接放到硬盘。
UnifiedMemoryManagement:
Execution Memory可以直接访问Storage Memory,Storage Memory可以访问Execution Memory,这两个可以互相借内存。
默认两部分加在一起为总堆大小-300MB,300MB可配置:spark.testing.reserveMemory RESERVED_SYSTEM_MOMORY_BYTES = 3 * 1024 * 1024是保留的内存大小。
spark.memory.storageFraction 默认为0.5,所以其最大空间为0.75 * 0.5 = 0.375倍的,且可以找execution memory借。如果借的还不够的话,则有不同的处理方式
Storage可以向execution借内存,当execution需要内存时,则会将Storage的内存drop掉,知道足够的空间够自己使用。
相反execution也可以向Storage借内存,当Storage的Memory不够的时候不会将Execution的内存drop掉,这是因为计算的时候牵扯很多东西,drop后太过于复杂。















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









