









60分钟从零起步驾驭Hive实战
1、Hive本质解析
2、Hive安装实战
3、使用Hive操作搜索引擎数据实战
一、Hive的本质是什么?
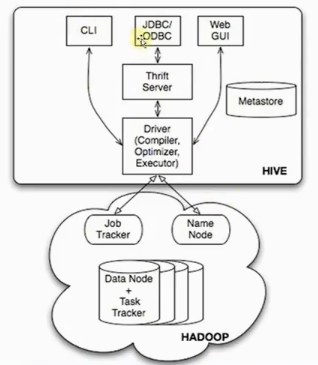
1、Hive是分布式数据仓库,同时又是查询引擎,所以SparkSQL取代的只是Hive查询引擎,在企业实际生产环境下Hive+Spark SQL是目前最为经典的数据分析组合;
2、Hive本身就是一个简单单机版本的软件,主要负责:
a)把HQL翻译成Mapper(s)-Reducer-Mapper(s)的代码;并且可能产生很多MapReduce的Job;
b)把生成的MapReduce代码及相关资源打包成为Jar并发布到Hadoop集群中且进行运行(这一切都是自动的)。
二、Hive安装和配置实战
1、我们使用的是Hive1.2.1版本
2、安装:
a)配置./.bashrc
export HIVE_HOME=
export HIVE_CONF_DIR=
PATH追加${HIVE_HOME}/bin
b)配置conf/hive-env.sh
export HADOOP_HOME HIVE_HOME HIVE_CONF_DIR
c)hive-default.xml.template 变成hive-site.xml
Hive默认情况下存放元数据的是Derby,遗憾的是Derby是单用户的,所以在生产环境下一般会采用支持多用户的数据库来进行Meta Store,且进行Master-Slaves主从读写分离和备份;我们最常使用MySQL。
hive.metastore.sarehouse.dir
默认/user/hive/warehouse(HDFS)L的安装和配置
4、Hive的表有两种基本类型:一种内部表(这种表数据属于Hive本身,言外之意是如果原来的数据在HDFS的其它地方,此时数据会通过HDFS移动到Hive数据仓库所在的目录,如果删除Hive中的该表的话,数据和元素据均会被删除),另外一种是外部表(这种表数据不属于Hive数据仓库,元数据中会表达具体数据在哪里,使用的时候和内部表的使用是一样的,只是如果通过Hive去删除的话,此时删除的只是元数据,并没有删除数据本身)。
三、使用Hive分析搜索数据















 2446
2446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









