






大数据架构现在已经泛滥了,有时候我也在想到底什么是架构? 架构到底是什么? 我更习惯用数据流来代替架构,大数据不就是采集,处理数据的一个系统吗? 哪来那么多架构?
我们先来介绍一下Hadoop系统大致干什么?
1. 数据采集
数据采集根据系统而定,没有固定应该怎么采集,互联网和工业的采集方式完全不同,互联网通常采集日志,主要用来给作为用户行为分析,改善网站提高点击量, API数据采集,用来监控系统的可用性等等,不管怎么采,不管你是什么内容,不管你是什么行业,整体也就分为4种形式: 结构化文件,半结构化文件,消息(就是流式处理),数据库。
针对文本数据采集有很多工具,各个公司使用也不一样,有人偏好ELK,有人喜欢Flume,对于流式采集不过就是 storm,spark streaming, flink, 对于数据库 Sqoop占据半壁江山,有人可能会再使用kettle之类的工具,半结构化通常来说会通过SQL来处理,把半结构化的数据直接作为一个字段存储到HIVE,然后使用SQL正规来处理。
2. 数据存储和处理
既然采集了数据,那么接下来就是存储和处理了。存储整体分为4种:HDFS文件,kafka/MQ消息, HIVE,HBASE; 处理分为离线和实时,那么离线又分为定时处理,调用式处理。 所谓定时处理,就是你通过JOB调度器,比如oozie定好时间自动跑JOB,这种HIVE/impala,mapreduce用的比较多,实时处理开始提过了,就是流式处理了,通过spark streaming, storm等组件来处理,调用式可能提及较少,这种就是你需要的时候就调用一下JOB,然后跑起来。怎么处理和怎么存储是有相关性的?具体根据你的业务需求,这个是没有固定的,有些要实时展现的,比如监控系统,这肯定不可能离线处理,如果采集的数据还需要处理,一般扔到 kafka,再使用storm,spark streaming肯定没问题,一般不会直接扔到HBASE里,毕竟通过kafka还有一个缓冲。如果是做数仓的,那么实时性要求并不那么高,主流方式就是SQL,spark, mapreduce。
3. 数据更新
有时候我们希望更新数据仓库数据,这一点HADOOP支持相对较弱,HIVE不支持更新(我忘记是哪个版本号称可以更新,我试了一下,那也叫支持?),目前适合更新的是impala+kudu,所以目前覆盖式更新较多,但是对于数据量很大的公司,这个地方确实要好好思考一下怎么做。 如果的确有这种需求,那么前期数据库必须设计好,通过时间来增量导入,这样就不需要每天全量覆盖式。
HADOOP处理完的数据最终还是要落地应用,因此又出现了一批中间层的组件,比如kylin, presto, zeeplin 等,这些东西的出现都不过是为了更好解决应用的问题。
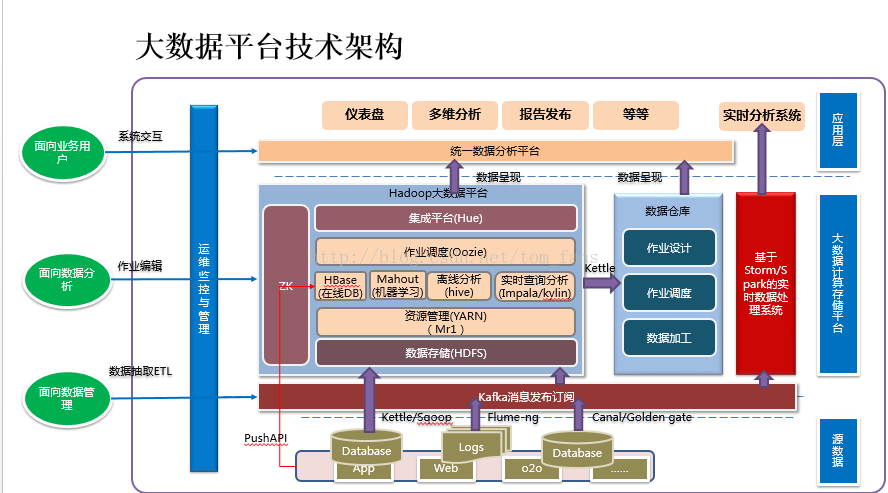
在实际运用过程中会有很多问题,通常有以下几个问题:
1)处理好的数据到底是放到HBASE还是HDFS, HIVE ? 这些依赖前端的访问,如果要实时展示,那么impala比较合适,HBASE也合适。 但是实际生产环境会有一些问题,比如我通过HIVE处理的数据默认是只在HIVE, 如果我希望通过HBASE来做实时展示怎么办? 我们需要同步数据到HBASE,这样HIVE,HBASE有同一份数据,如果业务很大,
磁盘浪费先不说,同步数据也是个麻烦事,因此很多中间层出现诸如kylin, persto等组件。
2)抽取数据的时候因为数据库很多,如果每一个IP配置一个链接,可能会疯掉,通常会用大磁盘机器做一个数据中心,需要SQOOP的库同步到数据中心,这样链接只有一个。
3)有些数据是时间序列的,严重依赖时间顺序, 使用HBASE存储没有问题,但是要设计好主键,如果可能,使用时间序列数据库更加合适,比如opentsdb本身也是用HBASE存储的。 目前我这边也有大部分是时间序列,而且通过算法来分析,数据必须根据时间排序,因此我简单的方案是ROWKEY就是用时间做后缀,但是这么做的缺点大家知道,region分配在一台机器,存在热点问题。
4) 中间是否需要把数据导回MySQL或者oracle , 这部分看业务,如果需要使用sqoop/kettle 都可以。 kettle可能会更加方便,毕竟kettle可以转换数据。
5) SQOOP从数据库抽取数据,如果不能做到增量,实际要实现增量非常麻烦,那么全库导入消耗时间随数据库越大就越长,这个地方目前我还没有看到好的方案,如果考虑使用数据库日志解析,然后增量更新是一个较好的方案,但是HIVE不支持更新,impala+kudu或者HBASE支持,因此整个数据分析的主打工具到底是什么,需要提前确认。否者后期会很麻烦。 看过小米的一些架构,他们是impala+kudu的坚定使用者。
















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











