







信息的提取有多种方法。
一、完整解析信息的标记形式,再提取关键信息
顾名思义,首先解析信息的标记形式,再提取需要的信息。
这种方法需要标记解析器,例如前面用到的BeautifulSoup库提供的标签树遍历。
优点:信息解析准确
缺点:提取信息繁琐,速度慢,也要求对信息的组织形式有一定的认识和了解。
二、无视标记形式,直接搜索关键信息
对信息的文本查找函数即可。
优点:提取过程简介,速度较快。
缺点:对提取结果缺乏准确性的定义,提取结果的准确性与讯息内容直接相关。
三、融合方法
1、概述
上述的方法各有优劣,一般情况下我们采用二者相融合的方法,即结合形式解析与搜索方法,提取关键信息。
既要用到标记解析器,也要用到文本查找函数。
2、引例
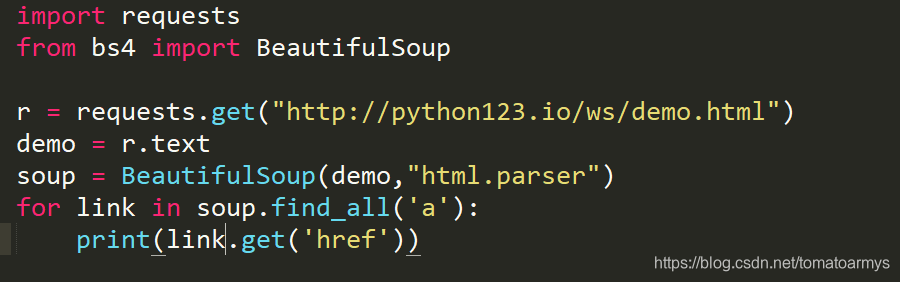
下面要实现这样一个功能,提取一个HTML文件中所有的URL链接。
思路:
- 搜索到所有的<a>标签(HTML中用于存储URL链接的标签)
- 解析<a>标签格式,提取href后的链接内容
实现代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









