






1. HDFS 配置
HDFS(Hadoop Distributed File System)是Hadoop的核心存储组件,需正确配置才能运行。
(1)配置 hadoop-env.sh
-
进入Hadoop配置目录,修改
hadoop-env.sh文件,明确指定JAVA_HOME路径。 -
Hadoop 不使用系统的
JAVA_HOME,需单独设置,确保其能正确调用JDK。


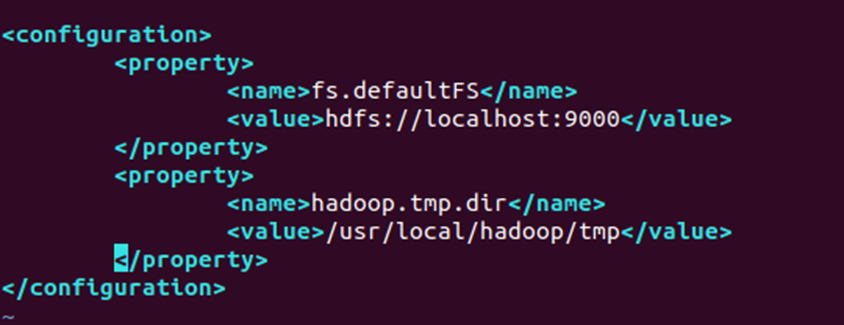
(2)修改 core-site.xml(核心配置文件)

-
设置HDFS的访问地址(
hdfs://localhost:9000)。 -
指定临时工作目录(
hadoop.tmp.dir),用于存储Hadoop运行时产生的临时数据。
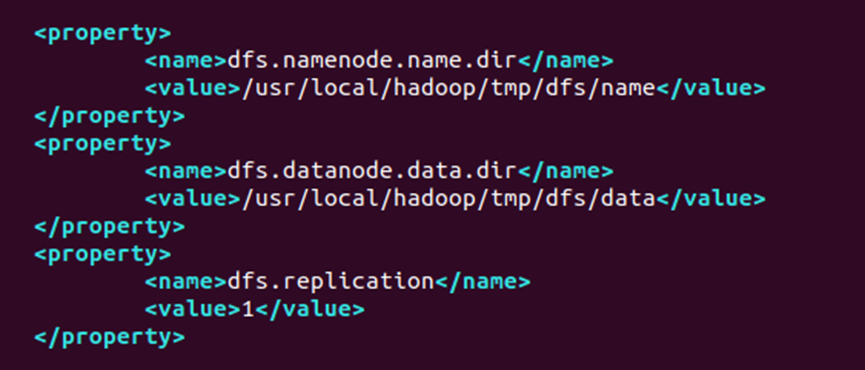
(3)配置 hdfs-site.xml(HDFS参数)

-
定义
NameNode和DataNode的数据存储路径。 -
NameNode负责文件系统元数据管理,DataNode负责实际数据存储。
(4)检查 slaves 文件
-
该文件列出所有运行
DataNode的节点,伪分布式模式下默认为localhost,无需修改。

(5)格式化HDFS(初始化文件系统)
-
首次启动前需执行
hdfs namenode -format,类似磁盘格式化。
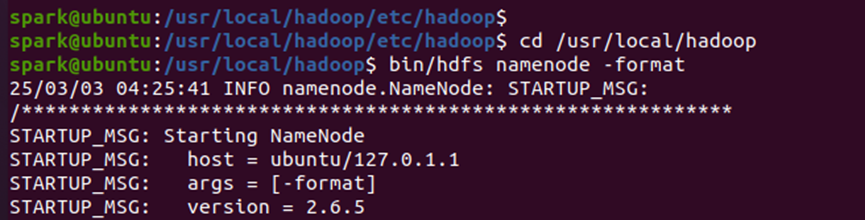
-
注意:重复格式化需先删除原有数据目录,否则会失败。
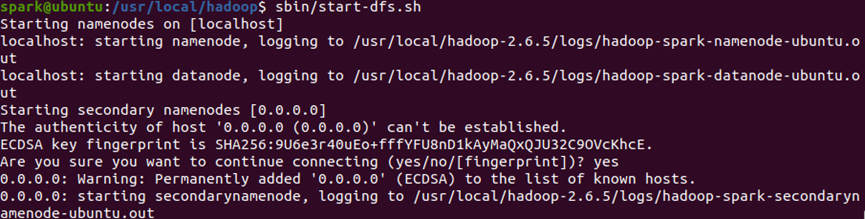
(6)启动HDFS服务
-
执行过程中会分别运行
start-dfs.sh,启动NameNode、DataNode和SecondaryNameNode。
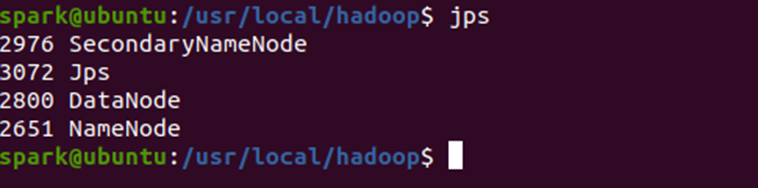
(7)验证HDFS进程
-
执行
jps命令,确认以下进程正常运行:-
NameNode -
DataNode -
SecondaryNameNode
-
2. YARN 配置
YARN(Yet Another Resource Negotiator)负责集群资源管理与任务调度。
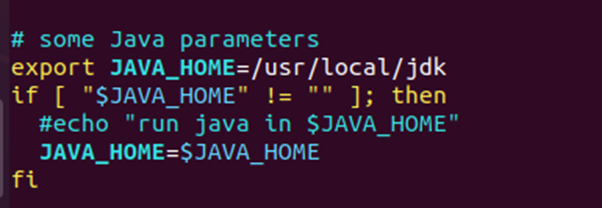
(1)配置 yarn-env.sh
-
修改文件中的
JAVA_HOME,确保YARN能正确调用JDK。
(2)调整 yarn-site.xml(资源管理参数)

-
关闭内存检查(虚拟机资源有限,避免任务因资源不足被拒绝)。
-
生产环境中需根据实际硬件配置优化参数。
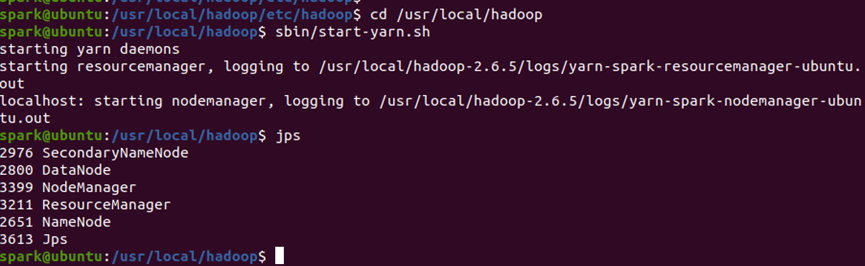
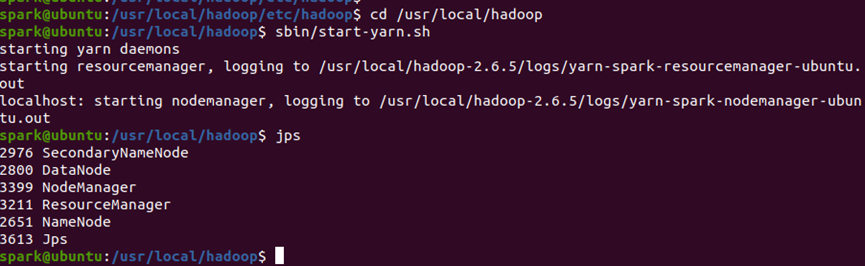
(3)启动YARN服务
-
运行
start-yarn.sh,启动ResourceManager(全局资源管理)和NodeManager(单节点资源管理)。
3. HDFS 与 YARN 测试
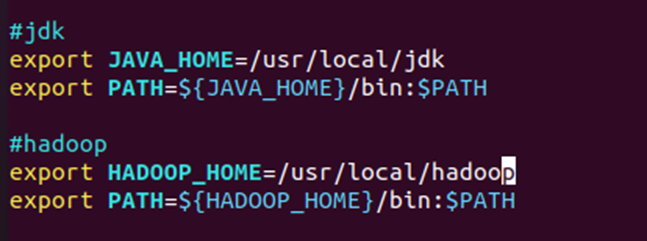
(1)配置Hadoop环境变量
-
在
/etc/profile中添加HADOOP_HOME和PATH,方便直接调用Hadoop命令。

-
执行
source /etc/profile使配置生效(新终端需重新执行或重启系统)。

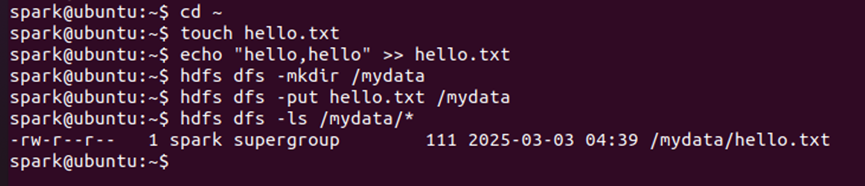
(2)HDFS基础操作测试
-
创建目录、上传文件等,验证HDFS功能是否正常。
(3)访问Web管理界面
-
HDFS WebUI:浏览器访问
http://localhost:50070,查看文件系统状态。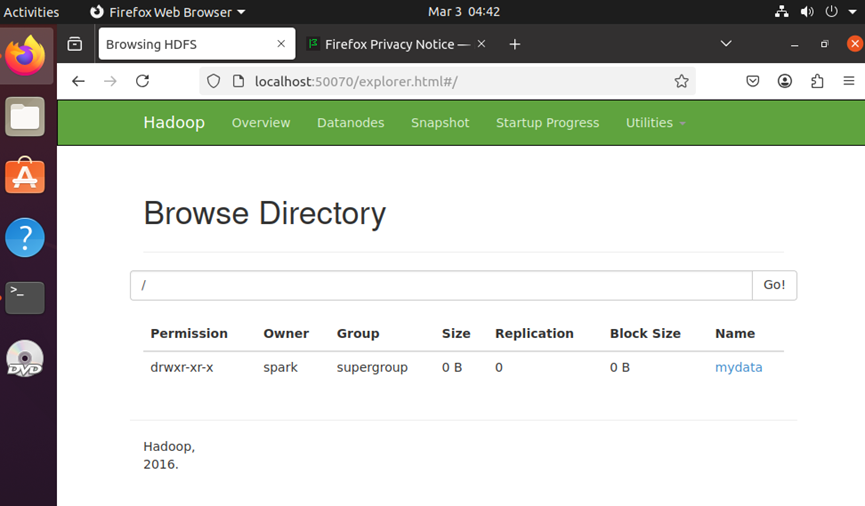
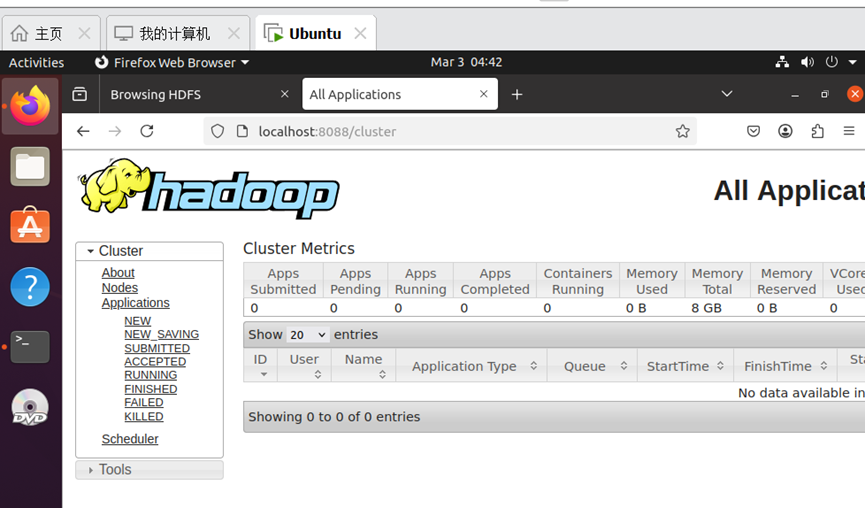
-
YARN WebUI:访问
http://localhost:8088,监控任务调度与资源使用情况。-
若从宿主机(如Windows)访问,需将
localhost替换为虚拟机IP。
-
(4)后续说明
-
当前未配置MapReduce,YARN仅支持资源管理。
-
待Spark环境搭建完成后,可提交Spark任务至YARN运行。
关键注意事项
-
权限问题:确保Hadoop目录及数据存储路径对当前用户可读写。
-
格式化HDFS:仅首次启动前执行,重复操作需先清理数据目录。
-
WebUI访问:若无法打开,检查防火墙或网络配置。
-
资源限制:虚拟机环境下,适当调低YARN内存要求以避免任务失败。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









