






一、二叉树理论
以下的理论知识和图都来自于代码随想录。
1.1 二叉树的种类
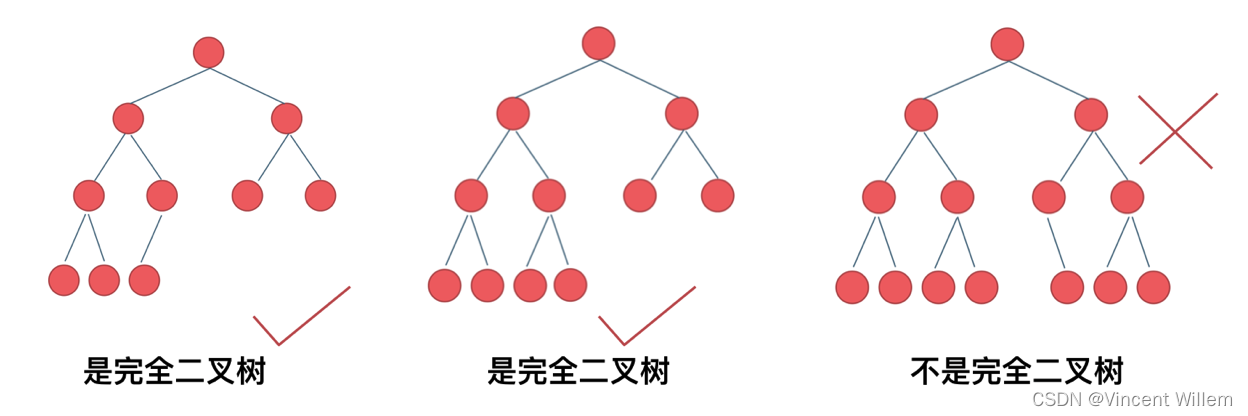
对于多数题目来讲,二叉树主要分为满二叉树和完全二叉树。
满二叉树是指一棵二叉树只有度为 0 和度为 2 的节点,并且度为 0 的节点在同一层上,那么这个二叉树被称作是满二叉树:
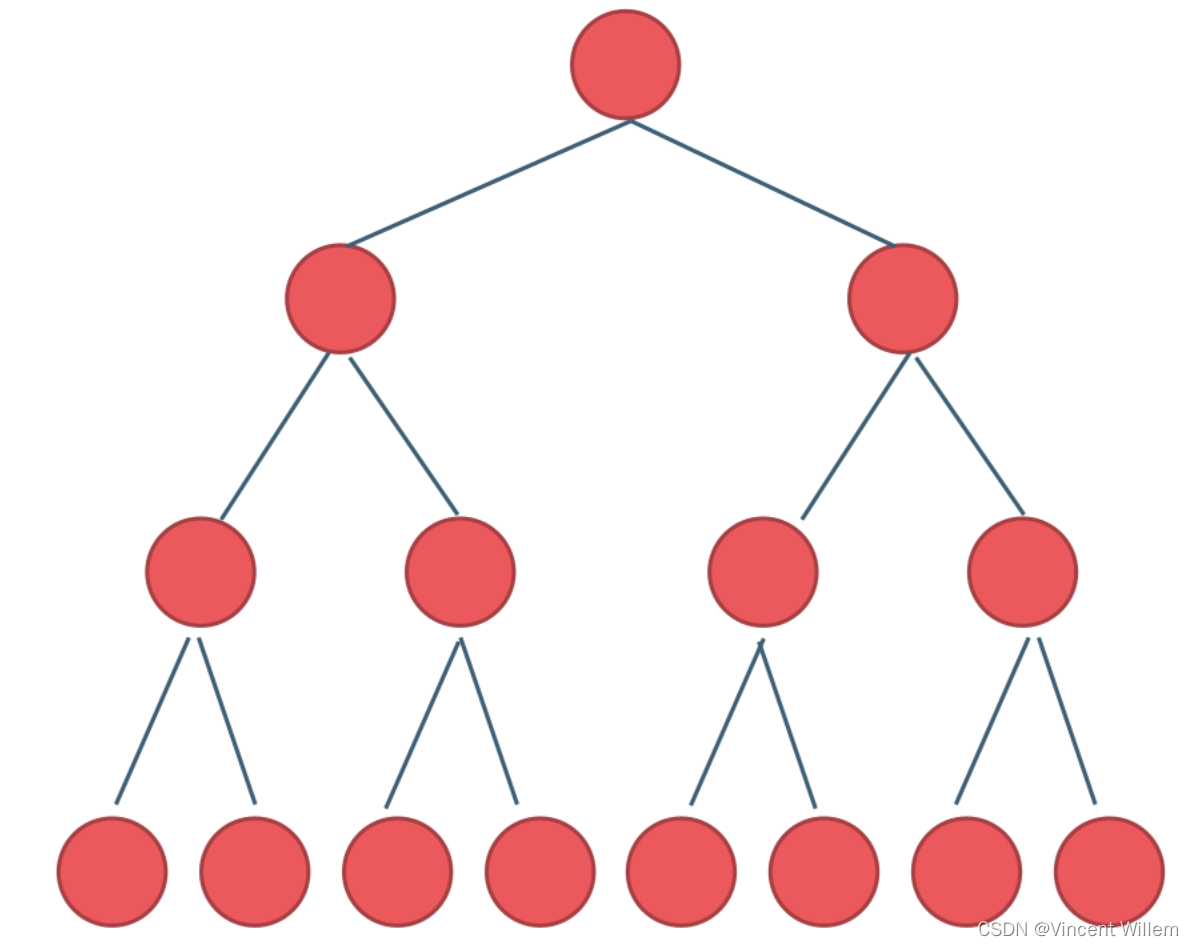
完全二叉树
完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
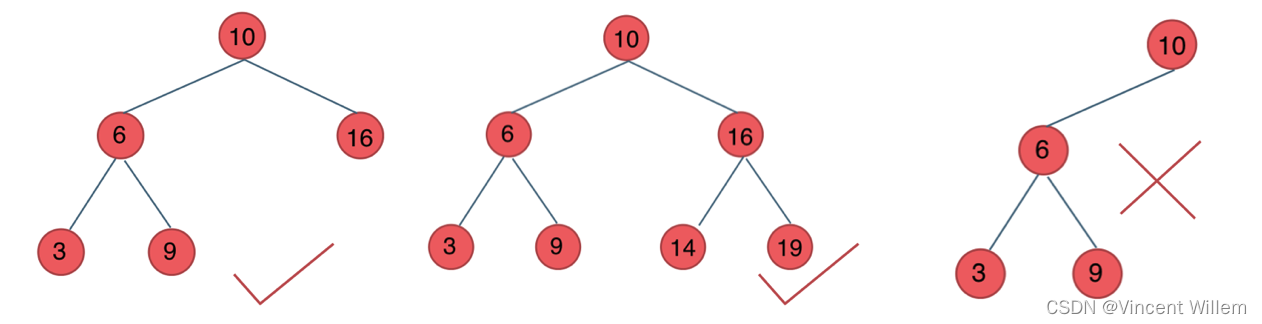
二叉搜索树
二叉搜索树是一个有序的树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树

平衡二叉搜索树
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
在 C++ 中,map、set、multimap 和 multiset 的底层实现都是平衡二叉树,因而他们的增删操作的时间复杂度是 logn,特别的,对于 unordered_map、unordered_map 和 unordered_set的底层实现是哈希表。
1.2 二叉树的存储方式
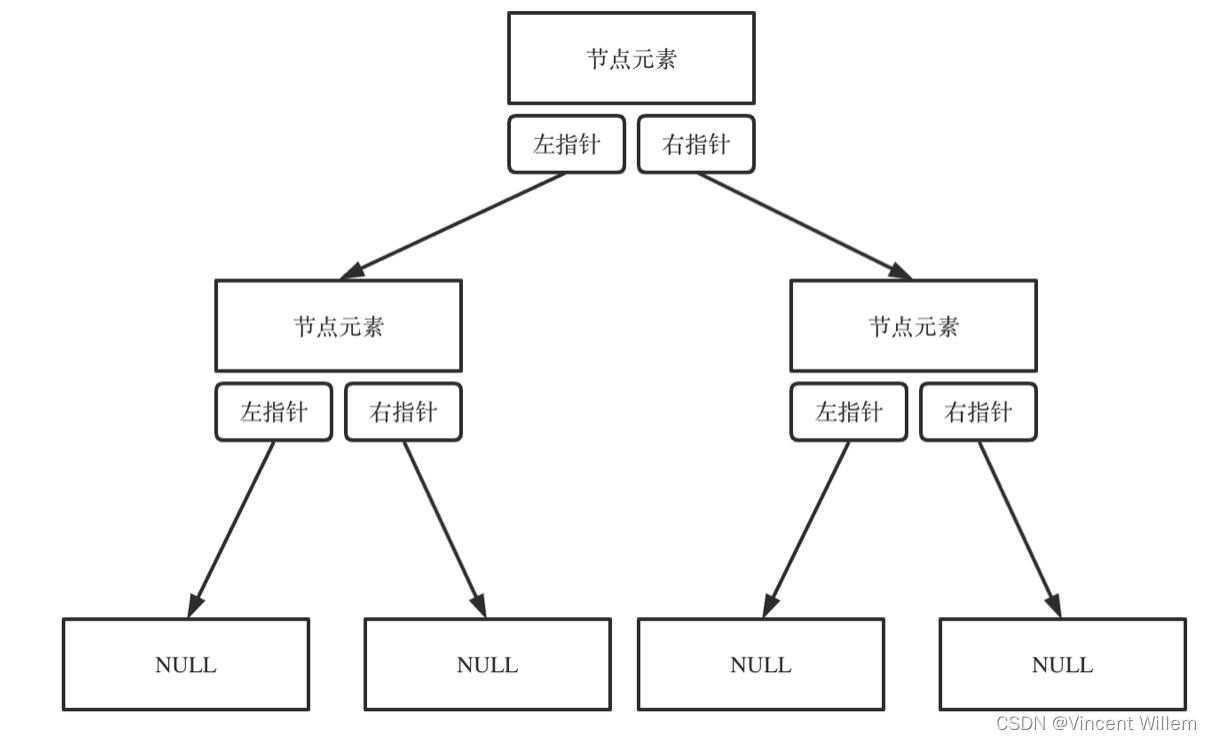
二叉树可以链式存储,也可以顺序存储。
前者采用的是指针的方式,而后者存储的方式是数组,对应的,前者是将散布在各个地址的节点串联在一起,而顺序存储的方式在内存上就是连续分布的。

对于顺序存储而言,其父节点的索引是 i ,那么它的左孩子的索引就是 i * 2 + 1,右孩的索引是 i * 2 + 2。
1.3 二叉树的遍历方式
总的来说,二叉树的遍历方式分为深度优先搜索和广度优先搜索,其中,前者包括前序遍历、中序遍历和后序遍历三种方式,而这三种方法可以通过递归法和迭代法分别实现;后者一般采用层序遍历的方式,通过迭代法实现。
对于 dfs 而言,遍历的三种方式,其实本质上就是对中间节点的访问顺序:
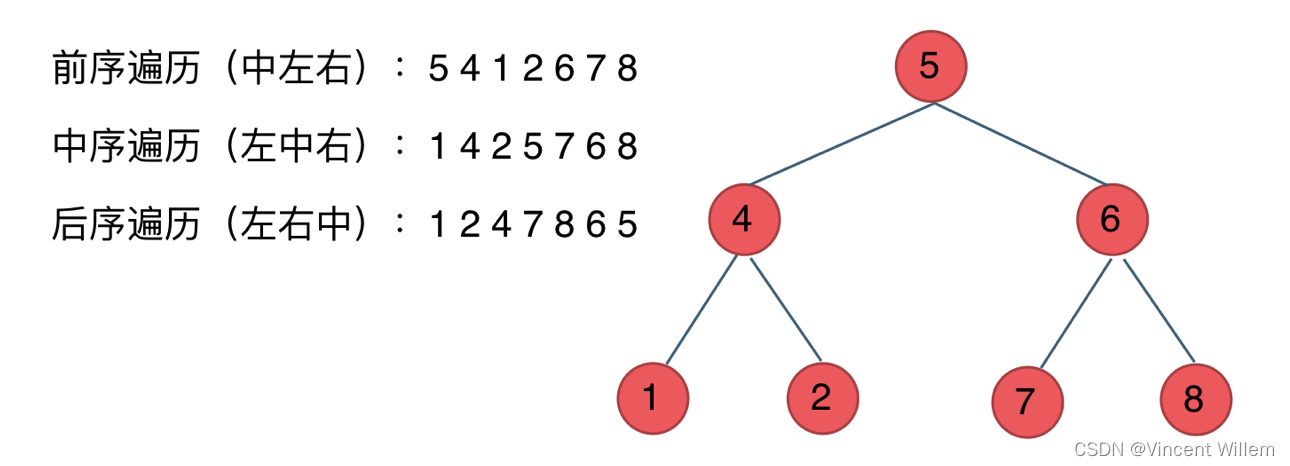
1.4 二叉树的定义
对于链式存储的二叉树而言,其定义的方式如下:
class TreeNode{
public:
int val;
TreeNode *left;
TreeNode *right;
TreeNode (int x) : val(x) , left(NULL), right(NULL) {}
};二、题目打卡
2.1 二叉树的前序遍历、中序遍历、后序遍历
前序遍历:
class Solution {
private:
vector<int> res;
public:
vector<int> preorderTraversal(TreeNode* root) {
if(!root) return res;
res.push_back(root->val);
preorderTraversal(root->left);
preorderTraversal(root->right);
return res;
}
};后序遍历:
class Solution {
private:
vector<int> res;
public:
vector<int> postorderTraversal(TreeNode* root) {
if(!root) return res;
postorderTraversal(root->left);
postorderTraversal(root->right);
res.push_back(root->val);
return res;
}
};中序遍历:
换一种写法:
class Solution {
public:
void recur(vector<int> &res, TreeNode* root){
if(!root) return;
recur(res,root->left);
res.push_back(root->val);
recur(res,root->right);
return;
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
recur(res,root);
return res;
}
};2.2 二叉树的迭代遍历
前序遍历:
class Solution {
private:
stack<TreeNode*> q;
vector<int> res;
public:
vector<int> preorderTraversal(TreeNode* root) {
if(!root) return {};
q.push(root);
while(!q.empty()){
TreeNode* tmp = q.top();
q.pop();
res.push_back(tmp->val);
if(tmp->right) q.push(tmp->right);
if(tmp->left) q.push(tmp->left);
}
return res;
}
};中序遍历:
class Solution {
private:
stack<TreeNode*> s;
vector<int> res;
public:
vector<int> inorderTraversal(TreeNode* root) {
TreeNode* cur = root;
while(cur != NULL || !s.empty()){
if(cur){
s.push(cur);
cur = cur->left;
}else{
cur = s.top();
s.pop();
res.push_back(cur->val);
cur = cur->right;
}
}
return res;
}
};后序遍历:
由于前序遍历的顺序是中左右,后续遍历是左右中,因而改变插入栈的顺序,可以变成右左中,最后再反转即可。
遍历后续遍历实际上是把前序遍历改一下插入栈的顺序,最后对结果列表进行反转即可。
class Solution {
private:
stack<TreeNode*> s;
vector<int> res;
public:
vector<int> postorderTraversal(TreeNode* root) {
if(!root) return {};
s.push(root);
while(!s.empty()){
TreeNode* tmp = s.top();
s.pop();
res.push_back(tmp->val);
if(tmp->left) s.push(tmp->left);
if(tmp->right) s.push(tmp->right);
}
reverse(res.begin(),res.end());
return res;
}
};
这样写的话,实际上并没有统一写法,而且相对比较绕,可以使用对中间节点加上 NULL 指针的办法,统一写法:
class Solution {
private:
stack<TreeNode*> s;
vector<int> res;
public:
vector<int> postorderTraversal(TreeNode* root) {
if(!root) return {};
s.push(root);
while(!s.empty()){
TreeNode* tmp = s.top();
if(tmp){
s.pop(); // 避免重复加入
s.push(tmp);
s.push(nullptr);
if(tmp->right) s.push(tmp->right);
if(tmp->left) s.push(tmp->left);
}else{
s.pop();
TreeNode* tmp_ = s.top();
s.pop();
res.push_back(tmp_->val);
}
}
return res;
}
};
这个展示的是后序遍历,对于另外两种,只需要改变 s.push(tmp) 这一句的顺序即可,思考的方式是根据中序、前序、后序遍历的顺序,以栈的角度思考进行代码顺序调整就可以了,比如后续遍历的顺序是 左右中,那么压入栈的顺序就应该是 中右左。















 81
81











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









