






文章目录
太长不看
WOS_Crawler是一个Web of Science核心集合爬虫。
- 支持爬取任意合法高级检索式的检索结果(题录信息)
- 支持爬取给定期刊列表爬取期刊上的全部文章(题录信息)
- 支持选择目标文献类型,如Article、Proceeding paper等
- 支持多种爬取结果的保存格式,如Plain text、Bibtex、HTML等,推荐使用Plain text,解析速度最快
- 支持将爬取结果解析、导入数据库(目前支持Plain text、Bibtex、XML格式解析、导入),解析数据项除了基本的文献信息外(标题、摘要、关键词、被引量等),还包括作者机构、基金、分类、参考文献等信息
WOS_Crawler基于Scrapy,使用PyQt5编写了图形界面,也有单独的Python API
程序主要依赖:Scrapy、BeautifulSoup、PyQt5、SQLAlchemy、bibtexparser、qt5reactor
项目地址:https://github.com/tomleung1996/wos_crawler
笔者是编程新手,这个爬虫能确保核心功能的正常使用,但肯定存在很多不人性化的地方和BUG,希望大家多多提意见!
0. 写在前面
Web of Science的爬虫我在一年多前就已经有写过,但是那个时候并没有考虑如何把程序写得更灵活、人性化一些,更多地只是满足自己学习科研上的需要。毕竟,采集Web of Science的题录数据其实是一个相当冷门的需求了,估计写出来也没人用。
但是我把这个爬虫整理一下放上GitHub,让大家用一下吐槽一下,说不定能够帮到一些和我一样的人,顺便提升我的编程能力。据我了解有不少同学面对老师的WoS文献采集任务还是只能手动500条一次次下下来,这个时间说长不长,但是为什么不把它省下来呢?对吧。所以就有了这个项目了。
做了数据爬取,然后还得把文本项解析一下存到数据库才能进行分析,我就索性把解析和导入功能也做了。后面希望还能把基本网络分析的功能集成进来,比如关键词共现、作者合著、引文网络等等。
希望Web of Science的表单项和URL不要发生太大变化吧!(至少一年多没变了)
1. WOS_Cralwer的使用方法
程序主要包含两种使用方法,一种基于PyQt5编写的图形界面,另一种基于Python API
1.1 图形界面使用方法
将工程中的main.py文件第36行的crawl_by_gui()取消注释,执行程序启动图形界面
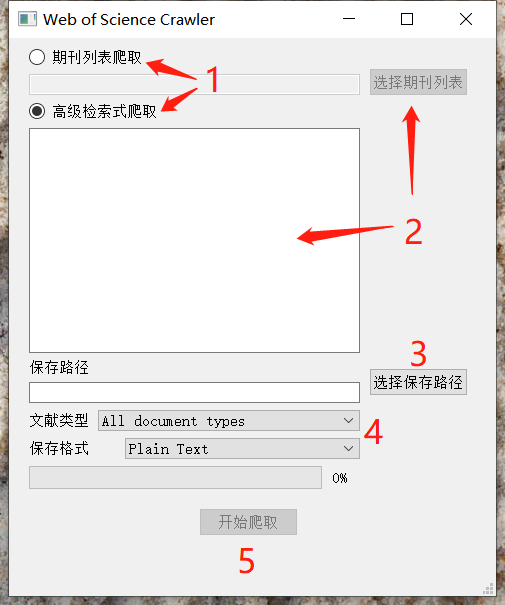
首先选择是根据期刊列表还是高级检索式进行爬取,然后选择期刊列表或者输入高级检索式。选择好保存路径、导出文件类型、保存格式后,点击开始爬取即可。爬取进度会在进度条显示。
在爬取的同时会进行结果的解析和数据库导入,默认的数据库使用的是SQLite,保存于目标路径的result.db文件中
1.2 Python API使用方法
将工程中的main.py文件第28-29行(按期刊列表)或第32-33行(按高级检索式)取消注释,传递合法的参数进去,执行程序即可。爬取进度会在终端显示。
2. 注意事项
- 因为Web of Science本身的限制,单个检索式如果结果数大于10万的话,大于10万的部分无法导出(即使手工也不行),此时可以通过年份划分来减少结果数,分批导出
- 导入数据库后,查询得到的结果条数可能会与网页结果数有偏差,我在定位目标批次后使用浏览器手动导出的方式证实了是WoS的问题(手动导出结果不足500条)。1万条结果会缺少5条左右
- 本程序虽不能通过WWS API获取数据,但是支持解析WWS API获得的XML文件
- 注重爬取道德,如有必要请设置合理的下载延迟
- 程序BUG在所难免,请在评论留言或提交ISSUE
3. Web of Science爬取逻辑
严格来讲,Web of Science的文献信息采集,是不需要“爬取”的,我们只是用到了它本身的导出功能(见下图)。
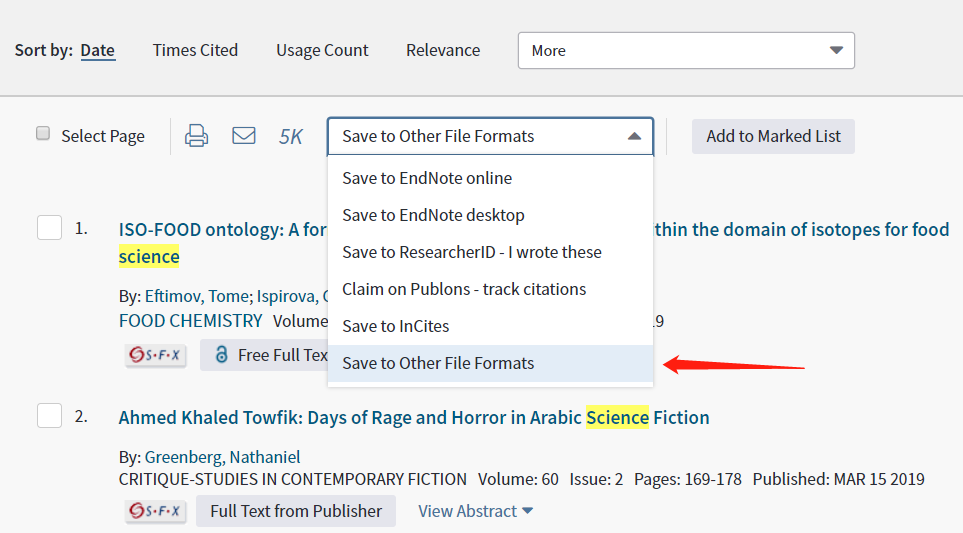
这个导出功能一次最多只能导出500条,如果我们要采集的检索结果多达数万,那么就要重复操作很多次了。而且,WoS默认的导出文件名称都叫savedrecs.xxx,手动改名字也是一个恶心的工作。
但既然WoS已经为我们提供了结构良好的数据导出功能,我们就无需再从头开始写我们的爬虫了,只需要模仿我们的手工操作,不断重复地导出500条结果即可。
3.1 抽象爬取逻辑
首先,我们比较抽象地定义我们的爬取步骤:
- 向Web of Science 提交检索请求
- 反复导出文献,直到全部结果导出完毕
3.2 具体爬取逻辑
然后,打开抓包工具Fiddler,人工走一遍文献导出流程,完善爬取步骤:
值得一提的是,WoS的爬取可以说是特别简单,了解流程之后就会明白本质上只是提交几个表单即可,不同的导出配置可以通过修改表单项来实现,十分适合拿来练手
- 获取
SID,SID是WoS用以辨识用户合法权限的标志,可以通过访问http://www.webofknowledge.com/,在跳转后的URL中直接提取获得(如果是校外等无权限用户,SID将不会在URL中出现 - 获取
本校已经购买的数据库,如果爬虫不需要在各校通用的话,可以把表单中的这一项写死。本校已经购买的数据库可以在第一步的页面中提取id为ss_showsuggestions的元素内容得到 - 向指定的URL提交检索请求,指定的URL是
http://apps.webofknowledge.com/WOS_AdvancedSearch.do,通过POST方式提交下面的表单,表单内容需要根据实际情况进行自动填充
| Key | Value | 备注 |
|---|---|---|
| product | WOS | |
| search_mode | AdvancedSearch | |
| SID | SID | 填入获取到的SID |
| input_invalid_notice | Search Error: Please enter a search term. | |
| input_invalid_notice_limits | Note: Fields displayed in scrolling boxes must be combined with at least one other search field. | |
| action | search | |
| replaceSetId | 留空 | |
| goToPageLoc | SearchHistoryTableBanner | |
| value(input1) | QUERY | 填入合法的高级检索式,如:TS=INFORMATION SCIENCE |
| value(searchOp) | search | |
| value(select2) | LA | |
| value(input2) | 填入目标文献语言,留空表示全部语言 | |
| value(select3) | DT | |
| value(input3) | 填入目标文献类型,留空表示全部类型 | |
| value(limitCount) | 14 | |
| limitStatus | collapsed | |
| ss_lemmatization | On | |
| ss_spellchecking | Suggest | |
| SinceLastVisit_UTC | 留空 | |
| SinceLastVisit_DATE | 留空 | |
| period | Range Selection | |
| range | ALL | |
| startYear | 1900 | 这里其实应该填入学校购买的时间范围,但是我尝试过这个和实际不一致不影响,除非检索式查询的是范围外的 |
| endYear | 2019 | 填入当前年份 |
| editions | 本校已购买的数据库 | 以列表的形式填入,如["SCI", "SSCI", "AHCI", "ISTP", "ISSHP", "ESCI", "CCR", "IC"] |
| update_back2search_link_param | yes | |
| ss_query_language | 留空 | |
| rs_sort_by | PY.D;LD.D;SO.A;VL.D;PG.A;AU.A | 这里的A和D表示升序和降序,前面的字母表示字段,影响结果排序 |
- 提取
QID,QID和SID的结合是检索结果集合的唯一标志。提交检索请求和表单后,如果检索式合法并且表单无误,可以在URL中提取到QID - 提取
检索结果数,以便计算循环导出所需要的次数,在提交表单后跳转的页面可以得到 - 提取
检索结果页面连接,在提交表单后跳转的页面可以得到 - 循环提交导出请求,假设500条一批,总共需要提交
检索结果数除以500次,有余数则加1次,每次需要修改的只有START和END,即起止点。导出请求需要提交到http://apps.webofknowledge.com//OutboundService.do?action=go&&,表单格式如下所示:
| Key | Value | 备注 |
|---|---|---|
| selectedIds | 留空 | |
| displayCitedRefs | true | |
| displayTimesCited | true | |
| displayUsageInfo | true | |
| viewType | summary | |
| product | WOS | |
| rurl | response.url | 填写当前的URL |
| mark_id | WOS | |
| colName | WOS | |
| search_mode | AdvancedSearch | |
| locale | en_US | |
| view_name | WOS-summary | |
| sortBy | PY.D;LD.D;SO.A;VL.D;PG.A;AU.A | |
| mode | OpenOutputService | |
| qid | QID | 填入获取的QID |
| sid | SID | 填入获取的SID |
| format | saveToFile | |
| filters | HIGHLY_CITED HOT_PAPER OPEN_ACCESS PMID USAGEIND AUTHORSIDENTIFIERS ACCESSION_NUM FUNDING SUBJECT_CATEGORY JCR_CATEGORY LANG IDS PAGEC SABBR CITREFC ISSN PUBINFO KEYWORDS CITTIMES ADDRS CONFERENCE_SPONSORS DOCTYPE CITREF ABSTRACT CONFERENCE_INFO SOURCE TITLE AUTHORS | 导出字段选择,这里我选择了全部字段 |
| mark_to | END | 本批导出文章的止点 |
| mark_from | START | 本批导出文章的起点 |
| queryNatural | QUERY | 合法的高级检索式 |
| count_new_items_marked | 0 | |
| use_two_ets | false | |
| IncitesEntitled | no | |
| value(record_select_type) | range | |
| markFrom | START | 本批导出文章的起点 |
| markTo | END | 本批导出文章的止点 |
| fields_selection | HIGHLY_CITED HOT_PAPER OPEN_ACCESS PMID USAGEIND AUTHORSIDENTIFIERS ACCESSION_NUM FUNDING SUBJECT_CATEGORY JCR_CATEGORY LANG IDS PAGEC SABBR CITREFC ISSN PUBINFO KEYWORDS CITTIMES ADDRS CONFERENCE_SPONSORS DOCTYPE CITREF ABSTRACT CONFERENCE_INFO SOURCE TITLE AUTHORS | 导出字段选择,这里我选择了全部字段 |
| save_options | OUTPUT_FORMAT | 导出格式的选择,纯文本为fieldtagged,Bibtex格式为bibtex,其他类型可以参考WoS官网 |
- 提交表单后,WoS会返回文本类型的结果,将其重命名后直接保存即可,和手工导出的结果完全一致
以上就是Web of Science爬取的基本逻辑了,主要是表单项的填写,琢磨透之后可以省掉不少功夫

















 5003
5003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









