









最近读了一下经典的MapReduce这篇论文,大概的了解了一下整个模型的处理流程和用户的编程的方法,以及处理过程的优化和差错处理,下面我来谈谈我对论文的理解。网上有的更多的是使用MapReduce,而我着重对原理的理解。
并且,我也跟着MIT6.824的实验实验了一个简单的MapReduce模型,采用多线程来模拟分布式,最终实现了词频统计和倒排序索引
编程模型
整个mapreduce分成两个部分,包括map和reduce部分,其中map的输入为key/value pairs,输出为intermediate key/value pairs,而reduce接受 key和所对应的values将其合并。简单的过程如下所示:
map (k1,v1) -> list(k2,v2)
reduce (k2,list(v2)) -> list(v2)
执行过程
整个模型的执行过程比较明了,当处理到mapreduce部分时,master开始统领整个过程,将输入内容分割并分配给M台机器进行Map的工作,结束后每个Map都将中间值分成R个分区hash(key)%R,R个机器读取完每个中间文件的相应的分区后进行Reduce的工作最后输出结果并合并。整个过程如下图所示
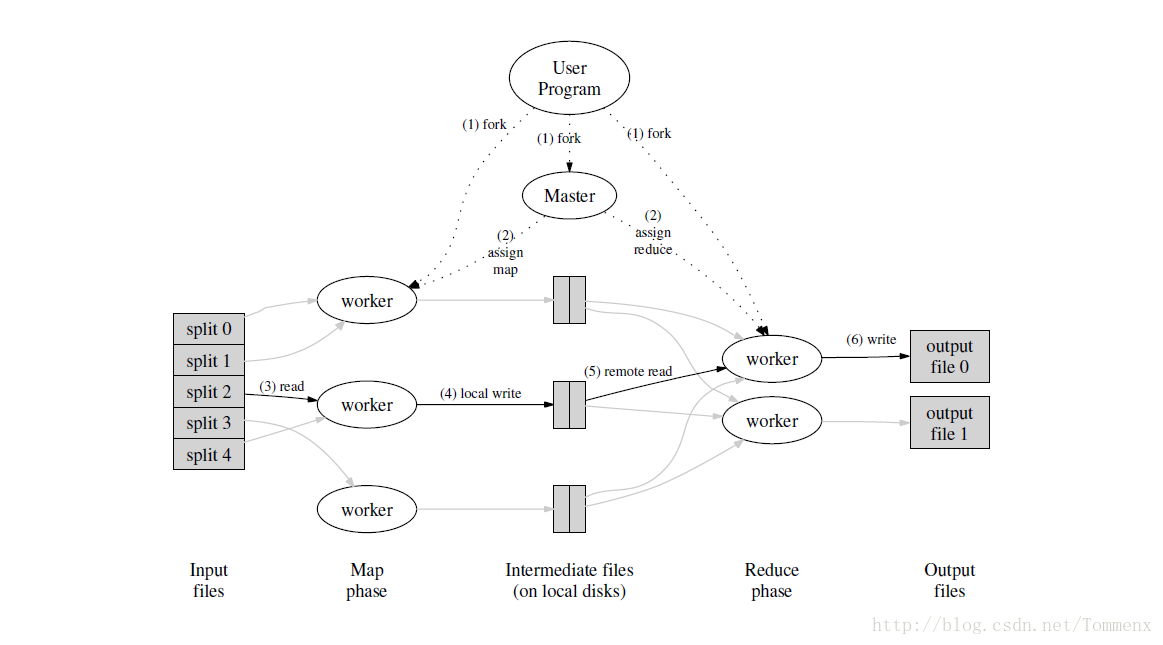
map
- MapReduce Library 将用户的输入文件分成M块,每一块的大小为16-64MB可以由用户指定,然后将用户的代码复制到集群的各个机器上
- master指定 M map 任务,R reduce 任务,并挑选空闲的机器执行
- map 将输入的内容转化成 intermediate key-value pairs ,并存储在自己的内存当中
- 周期性的将内存中的键值对写入本机的磁盘中并分割成R个区,可以使用
hash(key)%R处理,并将在磁盘中的存储位置返回给master
reduce
- reduce 利用网络从master所给的地址中读取完所有的内容后,按照key将结果进行排序,如果内容过大可以使用外部排序
- 当reduce 遍历完成后,将 key 和对应的 value序列传递给用户指定的reduce程序
- 当所有的任务都执行完成后,mapreduce 返回用户程序代码
容错处理
Mapreduce 编程模型是建立在一个计算机的集群上的,需要考虑主机失效的情况,类似与GFS。这一点也是十分重要的,考虑了实际情况中,集群往往采用了一些低性能,被淘汰的电脑,计算机失效的情况十分的常见。其中失效分成了两种情况:
1.Worker Failure;
2.Master Failure;
Worker Failure
- master周期性的
pingworker,如果长时间没有的到回应认为当前worker失效 - 当work完成了master所指派的任务时,会被标记成
idle - 因为map结束后,结果存储在本地的磁盘中,如果任务结束而主机失效了,需要重新分配在一台主机上,而reduce则不用,因为结果存储在全局的文件系统中
- 总之其中的worker失效了,master会将任务重新指派给被标记为
idle的机器继续完成任务,不会有其他的影响
Master Failure
- master可以周期性的建立备份,当master宕机后,可以从这些checkpoint中恢复过来
- 然而,必须终止当前的mapreduce活动,用户需要重新开始尝试
模型优化
Locality
mapreduce是面向大规模数据的处理模型,因此大量的数据在网络中传输占用了大量的带宽,产生了大量的时延,因此我们可以有限指派数据所在的电脑进行map的任务,避免了这部分数据的传输。而mapreduce是配合GFS使用,而GFS将文件分成大小相同的chunck并有多个replicas分布在不同的chunck-machine,所以master将map任务分配给了那些有这些replica的机器上,减小了网络数据量的传输
Task Granularity
我们将map任务切割成M块,reduce任务分割成R块,理论上M和R应该远远大于机器的数量,让一个worker运行多个不同的任务能够动态的均衡负载并且当worker失效的时候能够快速的恢复(???这里一直不太懂)
在R和M的设置上,我们选择一个M使得每一份输入的大小控制在16-64MB,而R的大小是worker数量的一个倍数,例如当workers=2000,R=5000,M=20000
Backup Tasks
Backup Tasks 是模型优化的精髓。由于众所周知的“木桶效应”,执行的时间往往是由最慢的那个worker决定的,即“straggler”。正是由于这些“stragger”的存在,使得整个mapreduce的过程耗费大量的时间。因此,在当mapreduce过程接近完成的时候,master又将这些正在进行的任务分配给backup,无论是primary还是backup完成了都标记成任务完成,经过计算大约减少了44%的时间
性能分析
Grep
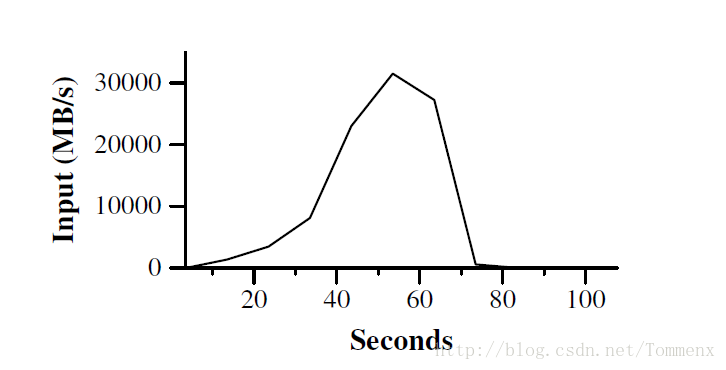
上图是数据传送过程中的速率图,其中在50s左右的时候1764台机器开始进行工作,数据传输速率到达30GB/s,当map结束后,速率开始下降我都知道80s是停止。这里所谓的数据传输速率可以代表progress computation。
可以看出在前60s的overhead,是因为master需要将处理的程序传送到每一个worker上,能达到这样的速度也是由于上面所说的Local Optimization
使得大量的传输不依靠网络。
Sort
- 在这次sort中,我们设置M=15000,R=4000,在(a)的最上面的图中我们可以看出在200秒左右map任务完成,速率最高到达13GB/s,低于上面的Grep是因为map结束后需要产生Intermediate Key并写入磁盘中,耗费大量的I/O时间
- shuffling在第一个map完成之后开始,由于本次有1700个worker,因此大致上有两个峰分别代表两个batch
- 最后一张图是reduce worker工作,输入为Intermediate key-value paris,最终在891秒完成了任务
有一些东西需要我们稍微注意一下:
- 输入的速率远大于shuffle也是因为Local Opimization,大部分的数据都在本地,而shuffle是依靠网络,reduce远距离读取worker存在本地硬盘中的结果
- 输出的速率比起shuffle更小是因为我们做了备份,每个结果都有一个备份因此速率更小
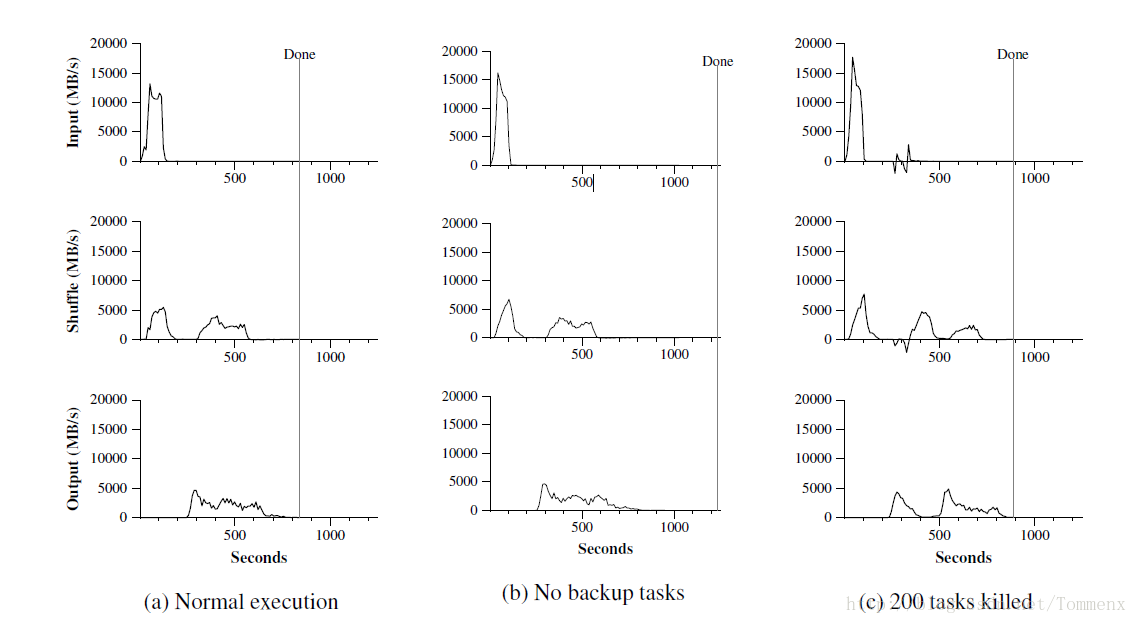
Effect of Backup Tasks
在图(b)中可以看出最后的完成的时间为1200多秒,因为有”stragger”一直拖着,导致最后完成需要更多的时间。
可以看出backup对整个工作还是十分有益的
Machine Failures
图(c)表示了在运行的过程中出现了部分机器失效的情况,可以看出立刻安排了新的workers,整个mapreduce的工作还是继续进行
可以看到Input rate 出现了负增长,是因为部分完成的map的工作丢失了(intermediate key-values存储在本地)随后马上执行re-execution,只比正常情况多了5%的时间
总结
以上就是我对mapreduce的总结,我会尽快写出MIT6.824 实验一(实现一个简易的mapreduce)














 5388
5388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









