







A Survey of Compiler Testing
Chen, Junjie, Jibesh Patra, Michael Pradel, Yingfei Xiong, Hongyu Zhang, Dan Hao和Lu Zhang. 《A Survey of Compiler Testing》. ACM Computing Surveys 1, 期 1 (不详): 35.
INTRODUCTION
编译器错误可能导致从正确的源代码生成不正确的二进制代码。编译器中的单个错误可以传播到基于它的任何应用程序,并导致异常的行为。例如,Java 7实现中的错误编译bug导致几个受欢迎的Apache项目崩溃。有时,甚至可以恶意注入编译器bug以损害编译应用程序的安全性。例如,Apple Xcode开发环境的一个恶意变种包含一个编译器“bug”,该错误将后门植入到每个已编译的应用程序中。这样的编译器后门还可以利用偶然引入的错误,如通过LLVM中的一个众所周知的错误来破坏Unix sudo工具。
编译器错误不仅会导致意想不到的行为,甚至可能导致严重的后果,而且还会使软件调试更加困难。因为开发人员几乎无法确定软件故障是由他们正在开发的程序还是所使用的编译器引起的。例如,当错误的编译器将正确的程序优化为具有错误运行时行为的可执行文件时,程序开发人员还不清楚是什么原因导致了意外行为。由于应用程序开发人员通常认为不当行为往往是由他们自己引入的错误引起的,因此他们可能花费很长时间才能最终意识到编译器错误是根本原因。
编译器测试面临的挑战
- 缺乏编译器行为的正式规范:虽然编译器具有高级规范,可以将源程序以保留语义的形式转换为目标程序,但通常不会执行低级别的详细信息(例如什么时候用什么优化)。例如,LLVM编译器具有58个优化转换通道,可以通过各种方式进行组合,但是何时应用这些通道中的哪个通道则没有规范。
- 编译器处理的变成语言具有丰富的语义,输入程序必须先通过词法分析器和解析器中的所有健全性检查和类型检查,然后才能测试编译器执行的优化。
- 编译器具有各种选项和功能。例如,大多数编译器提供不同的优化级别,支持源语言的多种变体,并考虑多个目标平台。大量的配置创建了一个很大的空间,难以穷举地探索并且与常规输入空间正交
对于大多数编程语言来说,存在多个等效的实现,这为对编译器进行差异测试提供了可能。
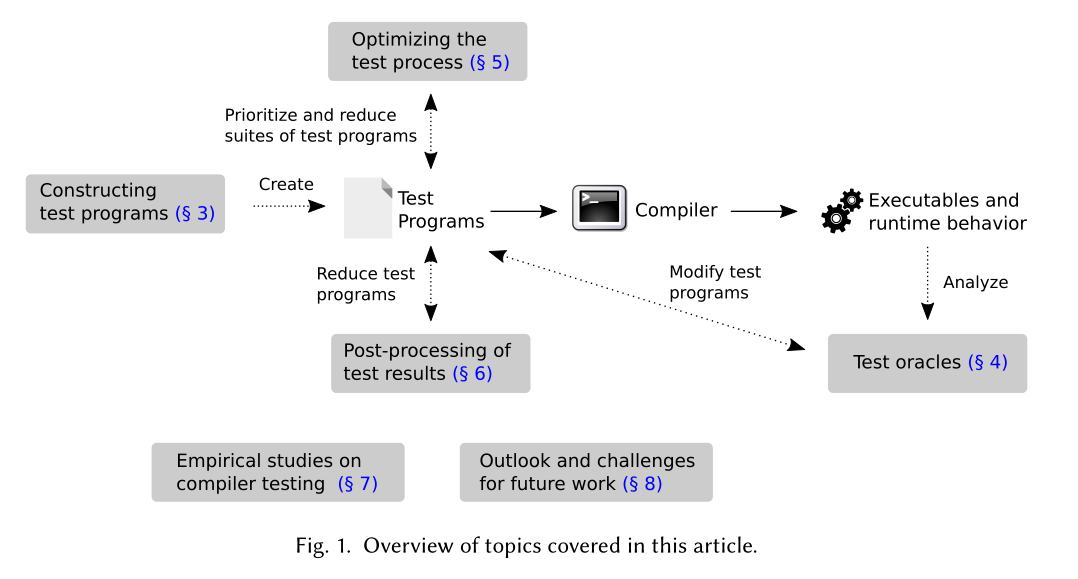
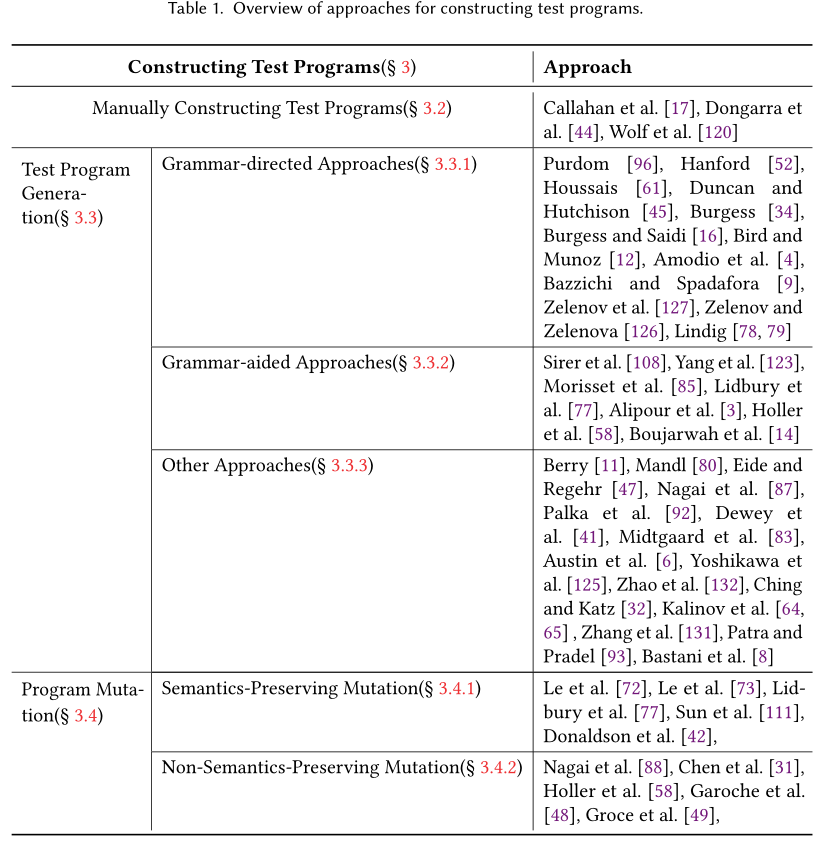
CONSTRUCTING TEST PROGRAMS
Challenges For Constructing Test Programs
构建用于测试编译器的测试程序具有挑战性。特别是,很难构建有效,多样且满足某些测试要求的测试程序。
Validity of test programs.
构造无效程序对于测试编译器的用处有限,因为程序要经历编译器处理的多个阶段。如果为编译器提供了无效的输入程序,则该程序会在处理的初始阶段被丢弃。
Diversity of test programs
与所有测试的输入一样,构建的测试程序应多样化。一组语法多样的测试程序将使用编译器的不同部分,在一定程度上可以增加被测试编译器的代码覆盖率。这可能有助于发现错误。
Specific requirements imposed by a testing method
某些测试方法有特定的限制,此时测试程序的构建就会变得更困难。例如,一种常见的测试方法是用两个编译器编译一个程序并比较执行结果。在这种情况下,输入程序应该没有未定义的行为。另一方面,如果仅测试编译器崩溃,则输入程序不一定必须没有未定义的行为。除了有效性和多样性要求之外,构建遵循这些限制或一致性的测试程序也可能具有挑战性。

Manually Constructing Test Programs
从编译器测试的早期开始,就一直使用手工构建的测试程序。这样的测试程序可以有效地发现错误,因为手工编写的程序可以满足任何需求,并且可以针对新实现的功能编写测试程序。
Test Program Generation
人工编写测试程序需要耗费大量的精力,所以很多研究人员研究了用于编译器测试的测试程序自动生成,这些工作大致可以分为三类:语法指导、语法辅助和其他方法。
Grammar-directed Approaches
语法制导的测试程序生成将编程语言的语法作为输入,基于该语法生成程序。语法制导是为自动生成测试编译器的测试程序而提出的第一种方法。给定一种语言的上下文无关语法,生成这种语言的程序。
Purdom提出的一种提出了一种基于上下文无关文法测试解析器和文法正确性的方法。这种生成方法从唯一的开始符号开始,通过应用语法中的左右重写规则进行,此方法通过一些启发式的方法,通过递归遍历语法生成简短的句子。但这种方法仅通过使用上下文无关的语法,很难表达语言的上下文相关特征。
以编译器测试为目标的测试程序的生成使用三个特定的二级语法,即W语法,属性语法和词缀语法。
Affix grammar.
词缀语法最初是为语言学应用而发明的[82],它提出了一种使用上下文附加词法来扩展上下文无关语法的方法,该上下文敏感概念使用词缀到语法产生物中。Hanford提出了一种使用扩展的上下文无关文法的方法。扩展语法的规则附加了其他已知语法生成器的规则。
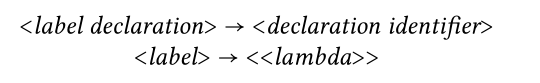
第一行是语法规则,第二行是语法生成器。这些规则意味着每当声明一个标识符(a)时,语法生成器就会被激活,并且->a的规则会被添加到上下文无关的语法中。通过将规则添加到无上下文语法中,可以有效地生成具有某些上下文敏感功能的程序,例如“声明后使用”。
Attribute grammar.
属性语法是通过将属性添加到语法规则来扩展无上下文语法的另一种方法,由Knuth引入。他通过将附加信息(属性)附加到某些产品中来扩展上下文无关语法来表达语义。Knuth的公式具有两种类型的属性:综合属性和继承属性。当语法规则表示为语法分析树时,综合属性的值取决于子级的属性值,而继承属性的属性值取决于父级的属性值。
Duncan和Hutchison 提出了一种通用的测试语法,作为将属性添加到语言的无上下文语法中的方式和位置的指南。这些属性是非负整数,从某种意义上说,它们指导测试程序的生成,这些属性的值确定在生成过程中将使用哪些语法。
Burgess 提出了一种基于属性语法的Pascal编译器测试方法。后来,Burgess和Saidi 对其进行了扩展,以检查两个Fortran编译器中的优化错误。他们通过添加属性来扩展语法,为语法生成分配权重,并生成自检测试程序。
Amodio等人的方法训练一个递归神经网络来生成测试程序。训练模型可以生成符合给定语法的数据,并且还可以尊重语言的其他格式良好的属性,例如在使用变量之前定义变量。为了使神经网络能够学习这样的特性,该方法为每个程序元素计算上下文向量,该上下文向量对例如已经定义的变量集进行编码。
W-grammar
Grammar-aided Approaches
语法辅助方法将语法作为输入,此外还使用一些启发式方法来解决上下文敏感问题。这些方法从用作占位符的类似模板的固定代码片段开始,然后利用语法生成程序的其余部分。此外,为了指导整体生成,某些方法还将测试驱动程序文件作为输入,而其他方法则将其扩展为语法产品。
Sirer等。提出了一种这样的语法辅助方法,通过概率迭代语法productions来测试Java虚拟机(JVM)。给定一个语法和一个称为种子的框架程序,该方法将输出自检测试程序,即带有断言的程序,以验证JVM的正确性。输入语法规范包含需要用其他信息进行扩充的production,例如,对特定产品可以使用的次数的限制,以及描述产品适用上下文的保护条件。
杨等。提出了一种名为Csmith的语法辅助工具,该工具可以创建C测试程序。Csmith还会生成包含控制流语句,结构,数组和大多数C表达式的程序。该方法使用复杂的启发式方法来避免生成具有未定义行为以及依赖于未指定行为的C程序。生成从创建一个main函数和一组结构类型声明开始,每个结构类型声明都包含随机数量的随机决定类型的成员变量。使用main函数作为起点,其余C代码将基于C语法的子集生成。Csmith根据当前的生成状态,根据概率表和过滤函数选择允许的产量。筛选器功能可增强上下文敏感性。在生成期间,Csmith将执行某些安全检查,并仅在所有安全检查均通过的情况下创建代码片段。
Holler等人没有像以前的方法那样生成或硬编码占位符代码。使用实际程序作为占位符。他们从语料库中提取这些程序,并用随机生成的代码片段替换程序的某些部分。代码片段是通过遍历语法生成并通过对特定生成有多种选择的情况下做出随机决定来生成的。此外,该方法还使用了一些启发式方法(如标识符重命名),以将生成的代码片段放入目标程序或占位符程序中。总体方法是生成和突变的结合
Other Approaches
并非所有用于自动测试程序生成的方法都基于目标编程语言的语法。下面讨论了一组不直接使用语法作为输入的方法。他们中的许多人都基于预定义的代码模板生成测试程序,这些模板指定了测试程序的框架,然后用其他代码段填充该框架。
Berry 根据实际程序员使用的语言功能的频率,提出了针对编译器的测试程序生成方法。为此,他们收集有关如何使用语言功能的统计信息,然后根据常用功能设计测试程序。这个方法的思想是:具有较高使用频率的功能更可能在编译器的实际使用过程中被编译器使用,因此也更有可能触发错误。
Mandl是一种避免在程序中生成重复元素的方法。它使用一种称为正交拉丁正方形的独特方法来生成用于验证Ada编译器的测试程序。拉丁正方形是一个正方形矩阵,其中每行和每列仅包含一个元素一次,即矩阵的所有元素都是唯一的。如果两个矩阵组合在一起可以创建另一个拉丁正方形,则它们是正交的拉丁正方形。Mandl将测试模板表示为正交拉丁正方形,并通过用允许的值替换模板矩阵中的一行元素来生成测试程序。这种方式的优点是可以生成多个唯一的测试程序
上文提到的Csmith方法是Randprog基于非语法的方法的扩展,是由Eide和Regehr提出。Randprog会生成随机的C程序来查找C的volatile限定符的错误编译。Randpro生成的每个程序都是硬编码的,首先会生成许多随机初始化的全局变量,程序包含局部变量的声明以及使用全局变量和局部变量表达式的函数,当然程序还会生成一个main函数
还有一些方法没有使用硬编码,而是使用用户可控的配置或者模板文件来生成测试程序
另外,机器学习也被用于测试程序的生成当中
Program Mutation
程序变异的主要思想是修改现有测试程序的某些部分,现有程序大多是通过上一节中提到的程序生成技术生成的。构建测试程序的变异方法可以分为两类。一类基于保留语义的变异,第二类基于不尝试保留程序语义的变异
Semantics-Preserving Mutation
语义保留变异的主要思想是不改变程序行为的情况下对程序进行变异。几乎所有保留变异的语义都基于等效模输入(EMI)思想。
基于EMI思想,Le等人提出了Orion通过变异程序中未执行的代码部分来创建测试程序。后来Le等人又通过扩展Orion提出了Athena,采用了指导性的突变策略给定一个程序,他们对程序的未执行部分进行变异,目的是生成一个与原始程序有较大距离的变异程序。该距离是根据控制流图(CFG)节点,CFG边缘之间的距离以及程序大小来计算的。为了指导突变,Athena使用马尔可夫链蒙特卡洛(MCMC)采样来选择长距离变异的程序。
Non-Semantics-Preserving Mutation
陈等人用于测试JVM的主要思想与Le等人的方法类似,执行MCMC(马尔可夫链蒙特卡洛)采样,选择具有更大可能性触发编译器错误的突变。更具体地说,为了测试JVM实现,Chen等人使用多种变异操作来变异类文件,例如在类中插入/删除方法。
Holler等提出了一种基于变异的方法,称为LangFuzz,该方法可在Mozilla Firefox的JavaScript解释器中发现错误。langFuzz包含两个阶段:学习和变异。学习阶段使用解析器处理一组样本输入文件来学习大量的代码片段,第二阶段解析目标程序,从学习到只是的相同类型扩展替换一些非终止符。
TEST ORACLES
编译器测试必须解决test-oracle问题:确定测试程序是否触发了编译器的bug。现有的方法分为两类:差异测试和蜕变测试。
Differential Testing for Compilers
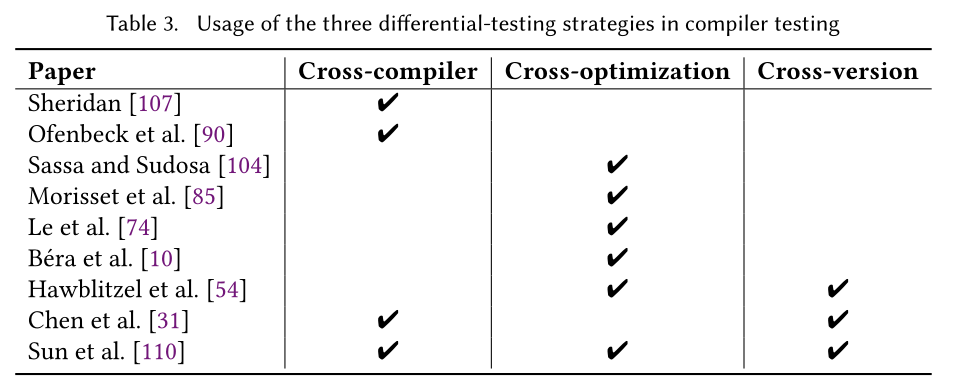
- **Cross-compiler strategy:**通过比较不同编译器产生的结果来检测编译器错误
- **Cross-optimization strategy:**通过比较单个编译器不同优化级别产生的结果来检测编译器错误
- **Cross-version strategy:**通过比较单个编译器不同版本产生的结果来检测编译器错误
Metamorphic Testing for Compilers
蜕变测试的核心思想是构造蜕变关系,该关系指定被测项目输入的特定更改将如何改变输出。

感觉蜕变测试和程序生成中使用的等效模思想很类似
OPTIMIZING THE TEST PROCESS
通常,编译器已经过良好的测试,并且得到了广泛的使用,因此很难检测到编译器中的潜在错误。实际上,编译器测试方法往往需要花费大量的测试时间才能通过运行许多测试程序来发现相对较少的编译器错误。所以测试过程的优化就显得非常重要。这些优化方法可以分为两种类型:测试程序优先级和测试套件缩减
Test-Program Prioritization
在编译器测试中,在所有可用的测试程序中,只有少数可以触发错误。因此,如果我们较早运行这些程序,则可以提高编译器测试的效率。测试程序优先级排序是一种优化测试程序执行顺序的方法,以便可以尽早执行具有更大可能性触发编译器错误的程序。
传统的优先级是基于代码覆盖率,但是编译器测试中的测试程序覆盖信息在测试之前无法得知
Chen等通过将每个测试程序转换为文本向量,提出了一种测试程序优先级排序方法。此方法考虑了与Bug相关的令牌的三类,即用于转换的语句,类型和修饰符以及运算符。然后,基于这些文本向量,此方法使用三种策略对这些测试程序进行优先级排序。 1)第一个是按照文本向量和原始向量之间的距离降序安排测试程序(0,0,…,0),这称为贪婪策略。 2)第二个方法是借用自适应随机测试策略来安排测试程序。更具体地说,它选择下一个测试程序,以使距已选择测试程序的距离最小。 3)第三个是使用局部约束搜索策略安排测试程序。
Chen等之后又提出了“学习测试”的思想,并实现了一种称为LET的测试程序优先级排序方法。LET首先提取两类功能,这些功能在某种程度上有助于揭示编译器错误。第一个是存在特征,反映了目标测试程序中是否包含某些类型的元素。第二个是用法功能,反映了如何在目标测试程序中使用这些元素。基于这两类功能,LET建立了功能模型和时间模型。前者旨在预测新测试程序的漏洞暴露概率,而后者旨在预测新测试程序的执行时间。基于这两个模型,LET计算每个新测试程序每单位时间的漏洞发现概率。最后,LET根据计算出的值计划这些新的测试程序。
由于上述提出的的测试程序优先级排序方法忽略了不同的测试程序可能具有相同的测试功能(即,测试编译器的相同功能,甚至检测到相同的错误)的情况,可能会降低其加速效果。为了缓解这个问题,Chen等提出了一种基于测试覆盖率信息区分具有不同测试功能的测试程序的方法。如前所述,编译器测试中的测试程序覆盖率信息不是预先可用的,因此他建议根据测试程序功能静态预测覆盖率,而无需执行测试。然后,根据静态预测的测试覆盖率,此方法将测试程序分为不同的组,每个组往往具有相似的测试能力。最后,该方法通过迭代枚举每个组来对测试程序进行排名。
Test-Suite Reduction
减少测试套件也是降低测试成本的一种方法。通过排除冗余测试程序,可以提高编译器测试的效率。
POST-PROCESSING OF TEST RESULTS
一旦编译器测试找到了触发编译器错误的测试程序,下一步就是了解并修复这些错误。为了完成此任务,一些研究工作集中在测试结果的后处理上。主要包括:
- 减少测试程序
- 重复的错误识别
- 编译器错误调试
Test Program Reduction
增量调试
测试程序往往很大且很复杂。因此,在向编译器开发人员报告编译器错误之前,重要的步骤是生成仍然触发编译器错误的小型测试程序,即减少测试程序。这是因为小型测试程序可以帮助开发人员调试编译器错误。
Regehr等为C编译器的测试程序设计和实现了三种缩减器
- 第一个称为Seq-Reduce测试程序简化程序,仅适用于Csmith生成的测试程序。由于Csmith生成的测试程序是由伪随机数生成器生成的整数序列确定的,因此Seq-Reduce测试程序归约器会迭代生成仍触发错误但小于以前生成的最小变体的变体。随机修改序列。
- 第二个称为快速减少测试程序减速器,它也仅适用于Csmith生成的测试程序。它支持一系列转换规则,例如消除死代码和利用路径分歧。这些规则基于所生成的测试程序的静态结构及其运行时行为的信息。
- 第三个称为C-Reduce,它适用于C编译器的任何测试程序。
以上介绍的reducer特定于某些单一类型的测试输入(例如C程序或OpenCL内核)。 Herfert等提出了一种通用的树约简算法,称为GTR,以减少任何树形结构的测试输入,例如Python和JavaScript。这种方法独立于编程语言。它的输入是一棵具有属性的树(例如,触发特定的编译器错误),在还原过程中应保留该属性。它的输出是一棵已减少但仍具有该属性的树。
Duplicated Bug Identification
由于随机测试或模糊测试是检测编译器错误的最重要方法之一,因此这些模糊测试器会遇到一个严重的问题:在一秒钟的测试时间内,模糊测试器可能会产生大量的触发错误的测试程序,其中很多测试程序实际上会触发相同的编译器错误。由于编译器开发人员昂贵且数量有限,因此这种冗余的触发错误的测试程序会增加开发人员的调试难度。特别是,现有工作报告说,由于这个问题,一些工业编译器开发人员停止使用Csmith。因此,有必要在报告编译器错误之前识别出此类重复项。
其中比较经典的就是之前读过的chen等提出的Taming Compiler Fuzzers。在给定大量错误触发测试程序的情况下,必须对这些测试程序进行排名,以便将触发明显错误的测试程序排在靠前的位置。他们通过定义一组距离函数来度量测试程序之间的相似性,从而区分触发不同编译器错误的测试程序,然后,它根据最远点优先算法对这些测试程序进行排名,该算法迭代地选择所有现有选定测试程序中距离最大,距离最近的下一个测试程序。这种方法的主要思想是如果两个测试程序之间的距离更远,则它们更有可能触发两个不同的错误
Compiler Bug Debugging
略
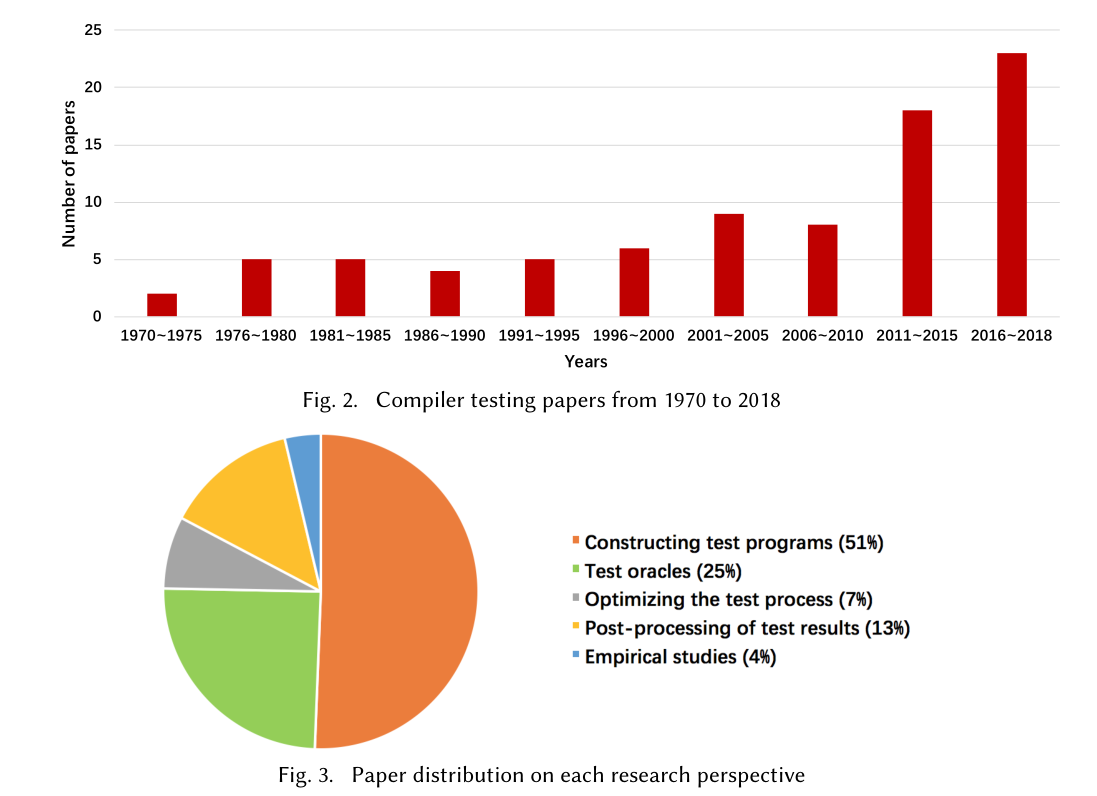
EMPIRICAL STUDIES ON COMPILER TESTING
除了开发解决技术难题的新方法外,编译器测试研究领域还受益于一些实证研究。这些研究系统地探索了编译器错误和编译器测试方法,提供了有关编译器测试的见解
OUTLOOK AND CHALLENGES FOR FUTURE WORK
Efficiency of Compiler Testing
一个效率瓶颈是,在编译器测试中,不同的测试程序经常多次发现错误。这不仅导致效率问题,而且还导致开发人员需要对重复的测试程序进行检查和分类,从而需要进行大量额外的工作。希望有一种方法可以生成测试程序,该程序仅通过使用已知的引起错误的测试程序的反馈来生成仅触发新错误的程序。
通过从现有测试程序中提取特征向量,可以更好地确定测试程序的优先级。可以将这样的方法集成到生成过程中以增强测试效率
从现有的导致错误的测试程序中学习可以帮助我们识别将来的导致错误的测试程序,从而对测试程序进行优先级排序。这样的方法也可以集成到测试生成中,以直接生成具有更大可能性触发错误的程序。
Compiler Verification
编译器验证是消除编译器错误的另一种尝试。但是,由于开发正式规范和证明的成本很高,因此验证技术通常只能应用于一小部分编译器,并且可以保证对属性的选择。测试如何补充验证可能是另一个研究方向,重点可能是尚未验证的编译器部分。
Generalizability of Approaches
尽管在自动化编译器测试方面已经取得了巨大的进步,但是这些努力大部分都针对一种特定的编程语言。大部分的方法都是针对C语言。比如Csmith仅仅设计用于生成C程序,将它迁移到其他变成语言并不容易。
另一个相关的问题是当前的方法是否可以推广到也将程序作为输入的其他软件系统,例如重构工具,调试器,静态错误检测器,代码搜索引擎等。需要进行更多的研究。了解这些工具和编译器之间的区别以及可以推广的方法。
Coverage of Bugs
当前用于构建测试程序和测试oracle的自动方法只能覆盖所有可能的测试程序和oracle的子集,因此仅覆盖一部分bug。在测试程序生成中,为了仅生成没有未定义行为的有效程序,诸如Csmith之类的工具依靠静态分析来逼近有效程序的边界,因此无法生成所有有效程序。另外,某些错误可能需要无效的程序才能触发它们。类似地,自动oracle主要依赖于程序/编译器之间的等效关系,因此不能用于发现需要等价关系之外的oracle的错误。
虽然生成无效程序很容易,但是了解哪些无效程序很可能触发错误可能并不容易。也可以考虑具有不确定行为或不确定行为的程序。
Handling the Discovered Bugs
在编译器的早期开发阶段,测试过程可能会产生许多错误,如何确定错误的优先级并向开发人员报告仍然是未解决的问题。
另一个挑战是测试程序的可读性。较小的程序并不一定意味着更好的可读性,如何对可读性进行建模以及如何实现更好的可读性是尚待解决的问题。
Benchmarks
当前,尚无用于评估编译器测试有效性的编译器错误基准。现有研究经常在评估过程中花费大量精力来发现现有编译器中的错误。商定一个共同的基准可以进一步促进编译器测试研究的发展。
CONCLUSION
编译器测试已经发展成为一个成熟的领域,已经对实际的编译器开发产生了重大影响。尽管在编译器测试方面取得了一些进步,但是将来仍然要解决几个有趣的挑战,包括如何概括现有方法以及如何进一步提高其有效性和效率。
从这篇综述和之前看过的编译器fuzz相关文章来看,编译器测试还存在着一些挑战和需要解决的问题,总结如下:
- 如何构造有效的程序输入,程序往往是高度结构化的;
- 如何解决测试的 Oracle 问题,即如何判断一个程序的输出是正确的;
- 如何优化测试的进程,包括时间和空间上的优化;
- 如何处理大量的 crash,人工处理 crash 非常耗时且难度大;
- 如何从已有的编译器测试中学习经验,指导编译器测试的发展。















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









