







简介
搭建一个多维度监控微服务的可视化平台,包括Docker容器监控、MySQL监控、Redis监控和微服务JVM监控等,并且在必要的情况下可以发送预警邮件。
这节主要用到的组件有Prometheus、Grafana、alertmanager、node_exporter、mysql_exporter、redis_exporter、cadvisor。各自作用如下所示:
-
Prometheus:获取、存储监控数据,供第三方查询;
-
Grafana:提供Web页面,从Prometheus获取监控数据可视化展示;
-
alertmanager:定义预警规则,发送预警信息;
-
node_exporter:收集微服务端点监控数据;
-
mysql_exporter:收集MySQL数据库监控数据;
-
redis_exporter:收集Redis监控数据;
-
cadvisor:收集Docker容器监控数据。
接入Prometheus
微服务接入Pormetheus只需要在community-common模块引入下面这个依赖即可:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>Prometheus端点的暴露依赖于spring-boot-starter-actuator,所以还需要在community-common模块里引入了`sspring-boot-starter-actuator依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>application.yml 中加入如下配置,默认打开所有端点。
management:
endpoints:
web:
exposure:
include: '*'
endpoint:
health:
show-details: ALWAYS启动server-admin,然后通过IDEA查看是否已经包含/actuator/prometheus端点:

接下来需要创建的服务较多,所以先约定下各个服务的端口号:
| 服务 | 端口 |
|---|---|
| prometheus | 8403 |
| grafana | 8404 |
| node_exporter | 8405 |
| alertmanager | 8406 |
| cadvisor | 8407 |
| redis_exporter | 8408 |
| mysql_exporter | 8409 |
我们需要创建相关挂载目录和配置文件。
在虚拟机中创建Prometheus挂载目录和配置文件:
#创建Prometheus挂载目录
mkdir -p /home/data/soft/prometheus/conf/
#在该目录下创建Prometheus配置文件
vim /home/data/soft/prometheus/conf/prometheus.ymlpromethues.yml配置文件内容如下所示:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.1.224:8403']
- job_name: 'node_exporter'
static_configs:
- targets: ['192.168.1.224:8405']
labels:
instance: 'node_exporter'
- job_name: 'redis_exporter'
static_configs:
- targets: ['192.168.1.224:8408']
labels:
instance: 'redis_exporter'
- job_name: 'mysql_exporter'
static_configs:
- targets: ['192.168.1.224:8409']
labels:
instance: 'mysql_exporter'
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.1.224:8407']
labels:
instance: 'cadvisor'
- job_name: 'server-admin-actuator'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['192.168.1.66:12181']
labels:
instance: 'server-admin'
- job_name: 'server-app-actuator'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['192.168.1.66:12182']
labels:
instance: 'server-app'
rule_files:
- 'memory_over.yml'
- 'server_down.yml'
alerting:
alertmanagers:
- static_configs:
- targets: ["192.168.1.224:8406"]配置的具体含义如下图所示:

值得注意的是,每个服务的targets都是一个数组,言外之意就是可以收集多个服务器下的exporter提供的监控数据。
接着创建上面提到的两个监控规则memory_over.yml和server_down.yml:
# 创建memory_over.yml
vim /home/data/soft/prometheus/conf/memory_over.yml 内容如下所示:
内容如下所示:
groups:
- name: memory_over
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80
for: 20s
labels:
user: MrBird
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 80% (current value is:{{ $value }})"含义是,当某个节点的内存使用率大于80%,并且持续时间大于20秒后,触发监控预警。
接着创建server_down.yml:
# 创建server_down.yml
vim /home/data/soft/prometheus/conf/server_down.yml内容如下所示:
groups:
- name: server_down
rules:
- alert: InstanceDown
expr: up == 0
for: 20s
labels:
user: ehm
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 20 s."含义是,当某个节点宕机(up==0表示宕机,1表示正常运行)超过20秒后,则触发监控。
接着创建alertmanager相关挂载目录和配置:
# 创建alertmanager挂载目录 /home/data/soft/alertmanager
mkdir -p /home/data/soft/alertmanager
# 创建alertmanager配置文件alertmanager.yml
vim /home/data/soft/alertmanager/alertmanager.ymlalertmanager.yml内容如下所示:
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '742294220@qq.com'
smtp_auth_username: '742294220@qq.com'
smtp_auth_password: 'yqfyrbmchajobejj'
smtp_require_tls: false
关闭
#templates:
# - '/alertmanager/template/*.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 5m
repeat_interval: 5m
receiver: 'default-receiver'
receivers:
- name: 'default-receiver'
email_configs:
- to: '1055195939@qq.com'
send_resolved: true配置文件的含义如下所示:

其中,smtp_auth_password并不是邮件的密码,而是授权码,以qq为例,授权码可以在下面这个页面定义:

点上图「开启」按钮会提示发送短信,短信发送成功后会显示的是smtp_auth_password
创建好后,我们接着创建一个docker-compose.yml文件,用于构建上面提到的那些服务:
# 创建docker-compose.yml
vim //home/data/soft/prometheus/bin/docker-compose.yml内容如下所示:
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- /home/data/soft/prometheus/conf/:/etc/prometheus/
ports:
- 8403:9090
restart: on-failure
node_exporter:
image: prom/node-exporter
container_name: node_exporter
ports:
- 8405:9100
redis_exporter:
image: oliver006/redis_exporter
container_name: redis_exporter
command:
- '--redis.addr=redis://192.168.1.165:6379'
- '--redis.password=hm@8519999&'
ports:
- 8408:9121
restart: on-failure
mysql_exporter:
image: prom/mysqld-exporter
container_name: mysql_exporter
environment:
- DATA_SOURCE_NAME=root:root@(192.168.1.165:3306)'
ports:
- 8409:9104
cadvisor:
image: google/cadvisor
container_name: cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- 8407:8080
alertmanager:
image: prom/alertmanager
container_name: alertmanager
volumes:
- /home/data/soft/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- 8406:9093
grafana:
image: grafana/grafana
container_name: grafana
ports:
- 8404:3000
中,在创建redis_exporter和mysql_exporter的时候需要指定它们的IP、端口和密码等配置。
然后在/prometheus目录下使用docker-compose up -d启动这些容器:
 容器运行成功后,在浏览器里访问:http://192.168.1.224:8403/alerts:
容器运行成功后,在浏览器里访问:http://192.168.1.224:8403/alerts:
 可以看的刚刚定义的两个告警规则已经成功加载。
可以看的刚刚定义的两个告警规则已经成功加载。
访问http://192.168.1.224:8403/targets,观察在Prometheus配置文件里定义的各个job的状态:
 可以看的都是监控的UP状态。
可以看的都是监控的UP状态。
还可以点击上面这个页面的各个xxx_exporter的链接,如果页面显示出了收集的数据,则说明各个exporter已经成功采集到了数据,以mysql_exporter为例子,访问http://192.168.1.224:8409/metrics:
访问http://192.168.1.224:8406/#/status看看我们在alertmanager.yml配置的规则是否已经生效:

现在监控数据都准备好了,接下来使用grafana以图形化的方式呈现它们。
Grafana使用
使用浏览器访问http://192.168.1.224:8404,用户名密码为admin/admin,首次登录需要修改密码。
进入主页后,我们修改下主题,让接下来的演示更为清晰:
然后回到主页点击Add data source添加数据源:
选择Prometheus,URL填写http://192.168.1.224:8403

然后点击页面下方的save & test即可。
数据源添加好后,就可以继续添加监控面板了,如下图所示创建一个新的监控:
这样创建监控面板比较麻烦,可以到Grafana官方市场选择别人配置好的模板:Dashboards | Grafana Labs。
别人的模板也未必一定就100%适合,这里我准备好了四个监控面板,你只需要导入即可:

这四个文件我已经上传到了百度云: 百度网盘 请输入提取码 提取码: fh3t
下面演示如何导入。

然后点击页面的Upload .json file按钮选择上面的json文件,比如导入Docker容器监控面板:

点击Import后,效果如下所示:
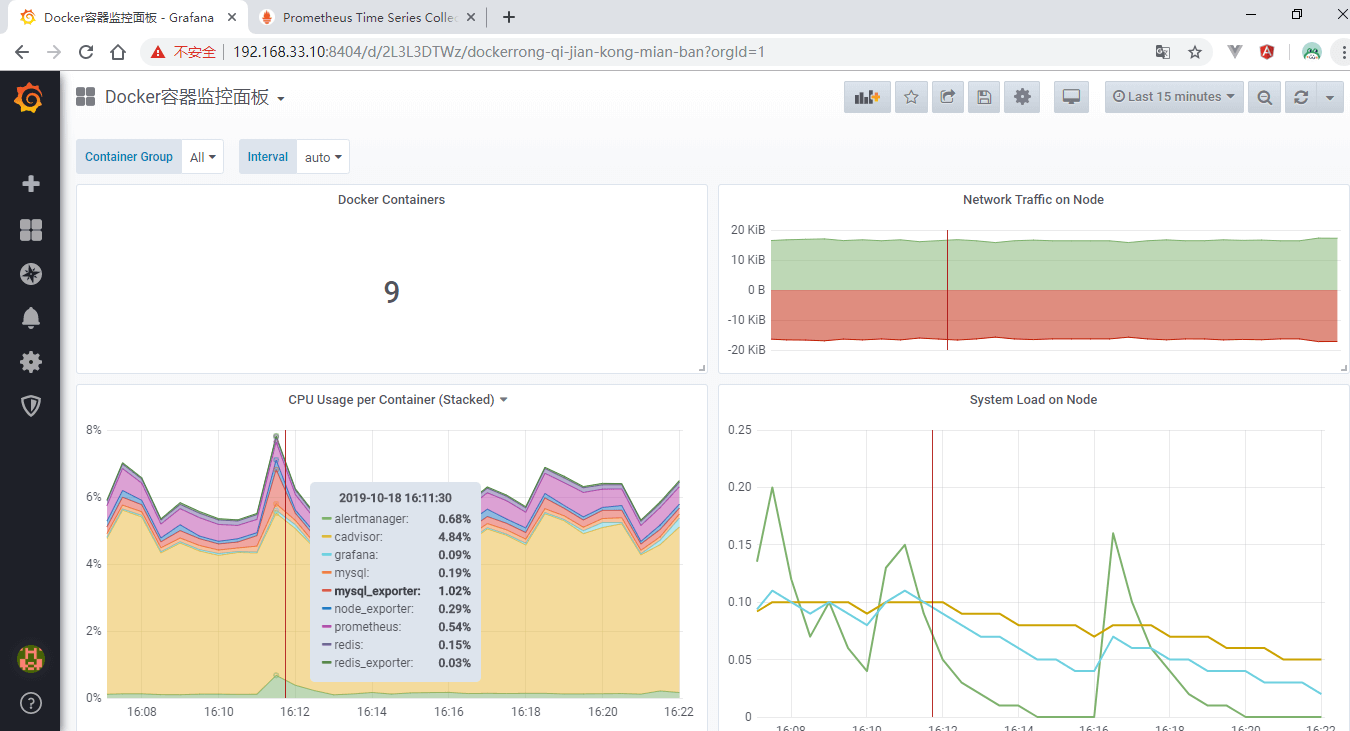
页面将显示Docker容器数量,每个容器CPU使用率,容量等等信息。剩下的三个模板自己导入即可,这里就不再演示了。
测试告警
我们在IDEA中关停community-admin服务,然后使用浏览器访问http://192.168.1.224:8403/alerts:
 可以看到,页面显示该端点已经处于PENDING(等待)状态,20秒后(server_down.yml里定义的时间)应用还是不可用的话,则认为该服务已经是(宕机)状态,则会触发server_down预警:
可以看到,页面显示该端点已经处于PENDING(等待)状态,20秒后(server_down.yml里定义的时间)应用还是不可用的话,则认为该服务已经是(宕机)状态,则会触发server_down预警:

使用浏览器访问http://192.168.1.224:8406/#/alerts可以看到alertmanager已经收到了这笔预警:
过一会(5秒的扫描时间+20秒的等待确认时间+10秒的分组等待时间)你的邮箱将收到如下所示的邮件:
 memory_over不太好测试,这里就不演示了。
memory_over不太好测试,这里就不演示了。
企业微信接收
step 1: 访问网站 注册企业微信账号(不需要企业认证)。
step 2: 访问apps 创建第三方应用,点击创建应用按钮 -> 填写应用信息:

alertmanger内容如下所示:
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '7xxx4220@qq.com'
smtp_auth_username: '7xxx94220@qq.com'
smtp_auth_password: 'bege'
smtp_require_tls: false
#templates:
# - '/alertmanager/template/*.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 5m
repeat_interval: 5m
receiver: 'default-receiver'
routes:
- match:
severity: down
receiver: 'wechat'
receivers:
- name: 'default-receiver'
email_configs:
- to: '1xxxx95939@qq.com'
send_resolved: true
- name: 'wechat'
wechat_configs:
- corp_id: 'wwxxe380a58963b'
to_party: '1'
agent_id: '1000002'
api_secret: 'JlGk5fyN2AeT82samJS86KCiIaOo-L8'配置文件的含义如下所示:
wechat.yml内容如下所示:
groups:
- name: wechat
rules:
- alert: server_status
expr: up == 0
for: 20s
labels:
severity: down
annotations:
summary: "机器 {{ $labels.instance }} 挂了"配置文件的含义如下所示:

用微信扫描微信插件上的二维码

个人微信即可同步收到企业微信的信息



附录
到这里我们已经成功搭建了一套完善的监控系统,并实现了预警功能。alertmanager支持非常丰富的预警配置,下面列举一些:
groups:
- name: example #定义规则组
rules:
- alert: InstanceDown #定义报警名称
expr: up == 0 #Promql语句,触发规则
for: 1m # 一分钟
labels: #标签定义报警的级别和主机
name: instance
severity: Critical
annotations: #注解
summary: " {{ $labels.appname }}" #报警摘要,取报警信息的appname名称
description: " 服务停止运行 " #报警信息
value: "{{ $value }}%" # 当前报警状态值
- name: Host
rules:
- alert: HostMemory Usage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
name: Memory
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机内存使用率超过80%."
value: "{{ $value }}"
- alert: HostCPU Usage
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance,appname) > 0.65
for: 1m
labels:
name: CPU
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机CPU使用率超过65%."
value: "{{ $value }}"
- alert: HostLoad
expr: node_load5 > 4
for: 1m
labels:
name: Load
severity: Warning
annotations:
summary: "{{ $labels.appname }} "
description: " 主机负载5分钟超过4."
value: "{{ $value }}"
- alert: HostFilesystem Usage
expr: 1-(node_filesystem_free_bytes / node_filesystem_size_bytes) > 0.8
for: 1m
labels:
name: Disk
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [ {{ $labels.mountpoint }} ]分区使用超过80%."
value: "{{ $value }}%"
- alert: HostDiskio
expr: irate(node_disk_writes_completed_total{job=~"Host"}[1m]) > 10
for: 1m
labels:
name: Diskio
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}]磁盘1分钟平均写入IO负载较高."
value: "{{ $value }}iops"
- alert: Network_receive
expr: irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 3
for: 1m
labels:
name: Network_receive
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}] 网卡5分钟平均接收流量超过3Mbps."
value: "{{ $value }}3Mbps"
- alert: Network_transmit
expr: irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 3
for: 1m
labels:
name: Network_transmit
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}] 网卡5分钟内平均发送流量超过3Mbps."
value: "{{ $value }}3Mbps"
- name: Container
rules:
- alert: ContainerCPU Usage
expr: (sum by(name,instance) (rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 60
for: 1m
labels:
name: CPU
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: " 容器CPU使用超过60%."
value: "{{ $value }}%"
- alert: ContainerMem Usage
# expr: (container_memory_usage_bytes - container_memory_cache) / container_spec_memory_limit_bytes * 100 > 10
expr: container_memory_usage_bytes{name=~".+"} / 1048576 > 1024
for: 1m
labels:
name: Memory
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: " 容器内存使用超过1GB."
value: "{{ $value }}G"














 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









