



在2025云栖大会现场,Qoder技术负责人陈鑫分享了Qoder产品研发背后的思考以及AI Coding的发展趋势。他指出上下文工程正在逐渐取代提示词工程成为主流,但上下文太长或太短都会影响模型的效果,为此Qoder做出了一系列优化设计,包括支持RepoWiki功能、集成记忆感知系统等。他还表示,未来多智能体架构是应对更长、更复杂任务的基石,但构建这样多智能架构仍存在诸多技术挑战,未来Qoder将继续结合世界领先的模型和先进的工程能力,帮助开发者开发更加复杂的任务。
以下是演讲全文:
感谢各位来到 Qoder 的专场,由我来给大家分享一下Qoder IDE背后的技术思考,回顾一下我们怎么一步一步把产品做到世界领先的,以及我们对未来技术趋势的判断。
AI Coding 技术发展趋势
第一部分先介绍 AI Coding 技术发展的三个趋势:
趋势一、从提示词工程到上下文工程
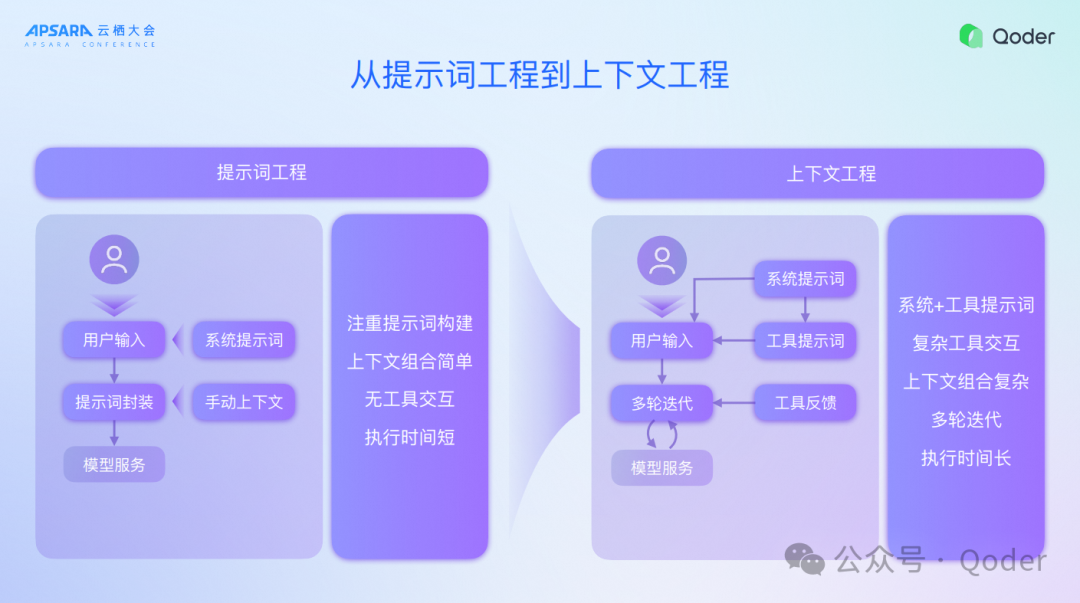
一是大家熟知的,现在智能体已经从提示词工程一步一步进化到了上下文工程,为什么要把提示词工程和上下文工程区分开,主要是大家工作的两种形态发生了很大的变化,最早我们开发LLM应用的时候,更多是Chatbot,主要是编写一些系统提示词、优化Workflow、用户输入的请求,经过一系列大模型的处理达到更好的效果。重点就是提示词的改变和提示词的封装上面,以及让开发者引入很多的上下文,然后把上下文组装起来,告诉大模型。但是随着Agent的快速发展,发生了很大的变化,为什么叫上下文工程,除了原来的系统提示词以外,还有非常多工具的提示词去编写,Agent最重要的是使用工具,除了使用工具,还在多轮的跟物理世界的迭代,读取代码写代码的过程中产生了很多工具的反馈,这些都需要一轮一轮的方式叠加到上下文里面去,最终让大模型知道走到哪一步,下一步怎么办,怎么持续把用户的问题解掉。
这个过程中就会发现上下文的宽度严重不足了,过去18K就够了,现在200K、300K,甚至1M都不够。随着大模型上下文越来越大,成本和开销越大,速度也会越慢,而且大模型并不是对非常长的上下文都有着强的指令遵循能力。比如说世界顶级模型,最多也就是200K以内,甚至100K以内有相对较好的指令遵循能力。如果上下文越长就会出现模型理解力越差,甚至放在最前面的上下文就会忘记,这是大模型注意力机制的缺点。当然随着大模型能力越来越好,更长上下文也具备很长注意力。我们必须在一个有限的上下文中,把解决问题最精准的内容放进去,这是关键的挑战。所以在上下文工程我们也做了非常多的技术优化,接下来给大家一一呈现。
趋势二、从短任务对话协同到长任务异步委派
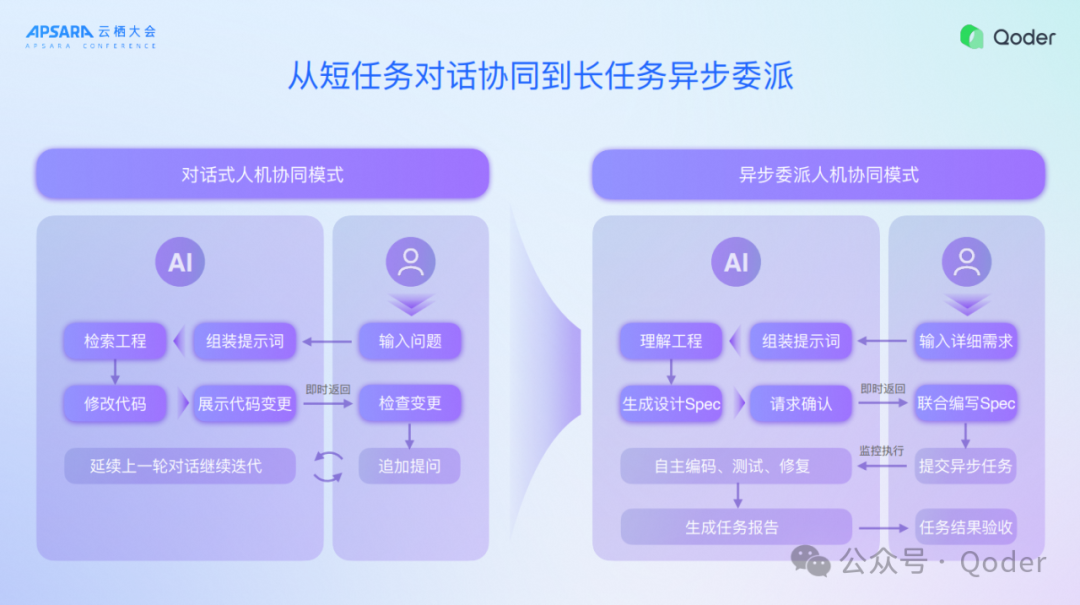
第二个技术趋势是从短任务的对话协同逐步到了长任务的异步委派。异步委派任务的相关思考和设计,核心带来的就是两种不同的人机交互模式:
-
对话式人机协同模式更多要不断地手把手,迭代式的给AI进行交互,在这个过程中如果要调整模式,就希望AI有不懂的就要问,从而逐步地引导开发者,把问题澄清。
-
异步委派模式就需要追求准确的输入、以及自主地完成编码测试修复。原来对话式人机协同模式是AI把代码写出来,再询问开发者要不要测试,但是异步委派这种频繁的交互花费更多时间。现在我们就需要AI能够自主地完成更长的任务、更复杂的任务和更多阶段的任务,这是非常大的技术的演进。
趋势三、从AI代码生成到全链路软件开发
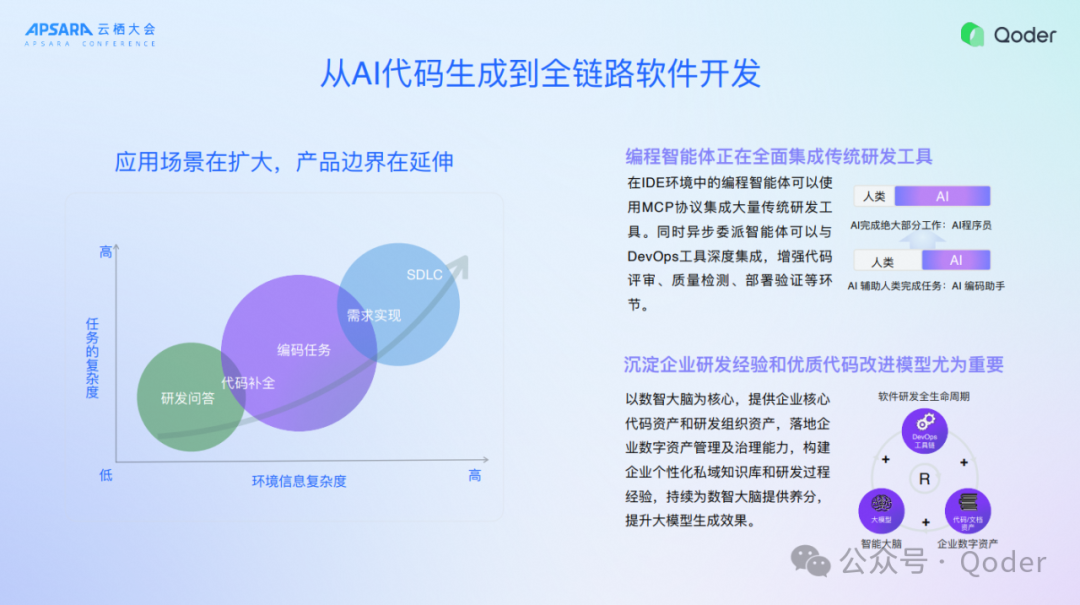
AI Coding发展到全链路的软件开发,之所以大家发现所有的产品都在聚焦于代码生成、代码编写。开发人员工作力的提升,好像还没有到测试和设计,为什么呢?核心的原因有几个:
-
大模型本身能力还不足以支撑端到端的研发,以及长时间任务的完成。
-
现在大模型在很多的复杂任务上的工程能力还没达到。
-
研发任务是最简单的补全编码任务,再往后会发生什么?大模型要理解你的需求设计,要能帮你做设计,要对复杂代码库做充分的理解,智能、能力要非常高,大家都知道写一个代码模块简单,做一个架构就难了,对阿里来说,可能得需要P7以上的员工做一个复杂架构设计,对人的要求很高,对AI的要求也高。
-
如果测试意味着什么?一是AI要充分地理解复杂的需求和逻辑,这个时候没有代码,逻辑是抽象的。二是理解图,甚至要界面上点一点,需要多模态的能力,这些都对大模型的能力有一个非常复杂的要求。
过去有一些传统的做法,在CI/CD或者其他流程中把某一个模块做AI化,这个不是叫AI原生的做法,AI原生的做法是今天让AI像人一样操作这些工具,自主地完成设计、编码和测试的过程,我相信在不久的将来,可能6-12个月,这个全链路就会发生很大的变化,这是第一个预判。
企业的知识和经验非常重要,我们在做很多企业级落地的时候会发现大模型之所以做不好,很多原因是因为我们工程的rules没有写好,一些编码的API、知识没有沉淀好。但是在过去落地的过程中发现沉淀这些知识和编辑维护这些知识,对于企业来讲成本太高,所以我们尝试了Repo Wiki,发现大模型来做知识的总结和沉淀可能更有效一点,所以未来会变成由AI驱动,然后企业其他研发作为补充的方式逐步的沉淀企业的经验和优秀的知识,这是第二个预判。
Qoder产品背后的技术思考
前面介绍了三个最主要的发展趋势,接下来从产品层面看一下关键能力背后的技术思考。
Qoder整体产品架构
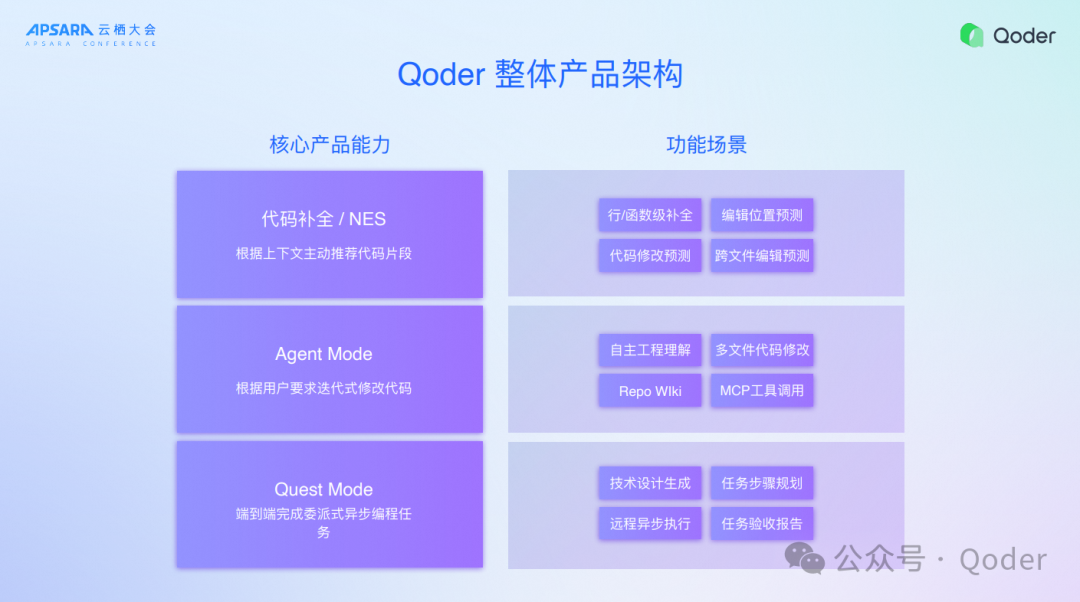
其实对于Qoder产品,最重要的就是这三个能力,因为子功能非常多,我抽象为以下三种不同的编程形态:
-
第一种是代码补全/NES:在编码区,由开发者编码,AI预测,它预测的是片段级的。
-
第二种是Agent Mode:对话式协同,根据用户要求迭代式修改代码。
-
第三种是Quest Mode:端到端完成委派异步变成任务。
在以前,使用代码补全的用户是远远大于使用Agent 的用户,但是在Qoder上,使用Agent Mode的用户是比做代码补全的用户要多。这说明我们判断的没错,即现在研发范式已经逐步地进入了Agent核心驱动的模式,所以Agent Mode是我们核心产品的能力,Quest Mode是我们的未来,工作负载越来越多的异步化,最终会在Quest Mode上面承载大量的研发任务。
接下来,我具体展开每一个核心产品能力背后的技术思考。
一、代码补全/NES

代码补全/NES是所有的开发者都可以使用的能力,原来只能做代码补全,现在可以做下一个边际未知预测,让代码补全能力从中间式补全变成可以用来做代码的重构、规范的修正、错误的修复,还可以更加精准地预测开发者做下一步要干什么,这是能力的升级。
关键挑战是合适的时机给开发者推荐合适的能力。过去代码补全能力是开发者写到哪,AI就续写一段。但是NES不一样,NES需要判断开发者修改的变量在哪些地方引用了,在哪些地方逐一的修改,甚至另外的文件修改,重构也一样,这块函数改了,其他地方的函数要不要改,所以整体的预测难度就大幅度提升。我们通过不断强化学习的想法合成开发者意图的链路,最终不断地优化。
二、智能对话 Agent Mode

智能对话Agent Mode是与开发者同步式协同的方式完成编码任务,核心难点有:
-
理解代码库:我们面向的是非常复杂的真实软件,大家可以把Agent执行的一个任务拆解成两个核心的能力。但是这需要先理解代码库,理解工程,知道开发者输入需求以后需要改哪些文件,需要学习什么。
-
执行任务:把所有的信息收集好给AI,AI基于传入的上下文准确的调用工具,准确完成编码任务。
通过这两步,我们构建了核心的代码检索能力和Agent能力。
三、工程知识可视 Repo Wiki

我们并不是第一家做Repo Wiki的,但是我们是第一家有能力把所有开发者的私有仓库全部做成Wiki的产品,这是质的突破。其他家只能解决开源仓库几百个,上千个,我们可以解决上万个、百万个甚至上亿仓库的生成,核心就是在于我们专门精调Wiki专用的多智能体的架构,各种各样的智能体负责生成,以及单独训练了Wiki的专用模型,才实现了既低成本又快速,又高质量的整体Wiki生成。
但是Wiki生成只是第一步,是整个在context战略当中的第一环,因为它原来没生成的时候,大家完全没有更高层次的知识架构的呈现。基于此,生成的文档首先用于开发者查看并支持分享的文档,更重要的是,它未来也能够帮助AI更深入地理解代码库。在未来长期的知识演进中,开发者可以持续贡献知识,丰富知识库。
大家知道在编写真实需求的过程中,我们会有大量的暗知识、坑等,例如开发者写完代码没有注释,后来者就会踩坑。这些坑能不能让AI感知人类标注的方式逐步沉淀,最终变成上下文,假以时日,AI就是这个团队里面最懂工程的角色,没有之一。如果达成这样,相信我们的效果会继续往上提升一大截。
四、异步委派任务Quest Mode

异步委派任务 Quest Mode,通过Spec-Driven,Development的模式去实现智能体端到端交付编程任务。这个能力要求是非常高的,首先必须要有全球最顶级的大模型才能做;其次要有复杂多智能体架构和协同机制;最后要有比较强的远程的沙箱环境容器大规模的调度能力,以及快速的云端代码检索能力,这些能力全部具备,才能够保证这个模式能工作。
大家发现,现在能够做异步委派的产品比较少,耳熟能详的就是几家做大模型核心的厂商,当然阿里也是一个全球非常强的大模型的竞争者,所以基于这一套能力就可以顺理成章的构建异步委派任务了。
Qoder技术优化路径
前面简单回顾了我们的产品和背后的技术思考和重要的要点,今天继续下钻一层,看看怎样一步一步使用核心技术将Qoder打造成全球领先效果的产品。
一、Qoder代码补全/NES能力进化
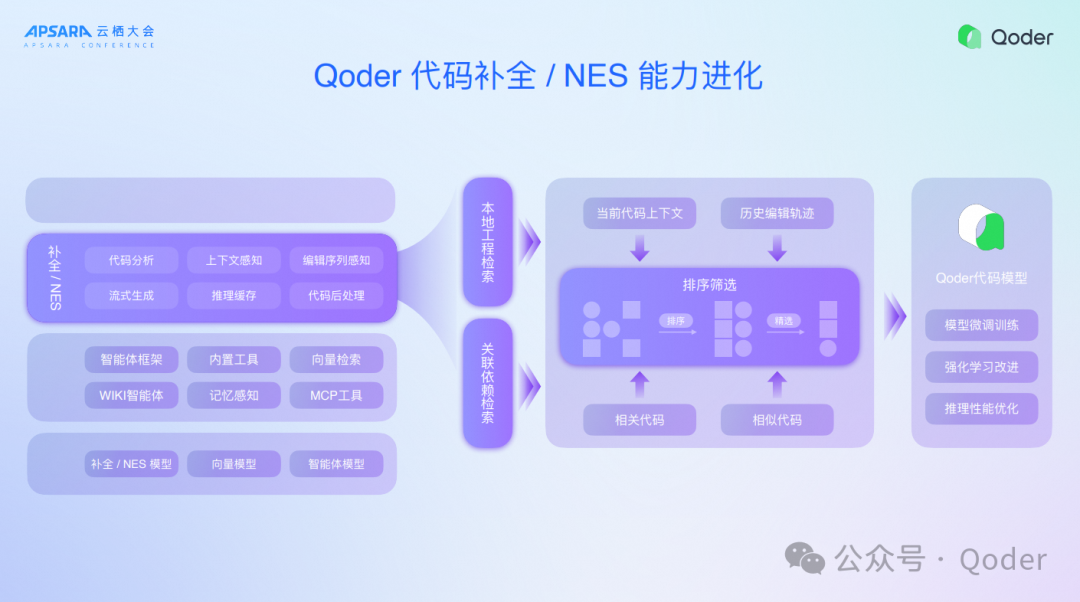
首先是最基础的代码补全和NES,其实从2023年开始做代码补全能力,到2024年已经能达到了33%的采纳率,全语言的平均值,这个值对于开发者来讲效果已经非常好。但是我们在原来的代码补全能力之上,又进化NES,就是下一个点位预测,包括工程本地的检索、关联的依赖检索、相关型上下文、相似型上下文以及开发者的所有编辑轨迹,我们都做了非常长的上下文工程能力,同时,我们还配套专门训练了NES模型,通过最新强化学习方法,一个大规模训练的集群,最终保证能力的持续进化。
二、面向未来模型能力,布局Coding Agent技术
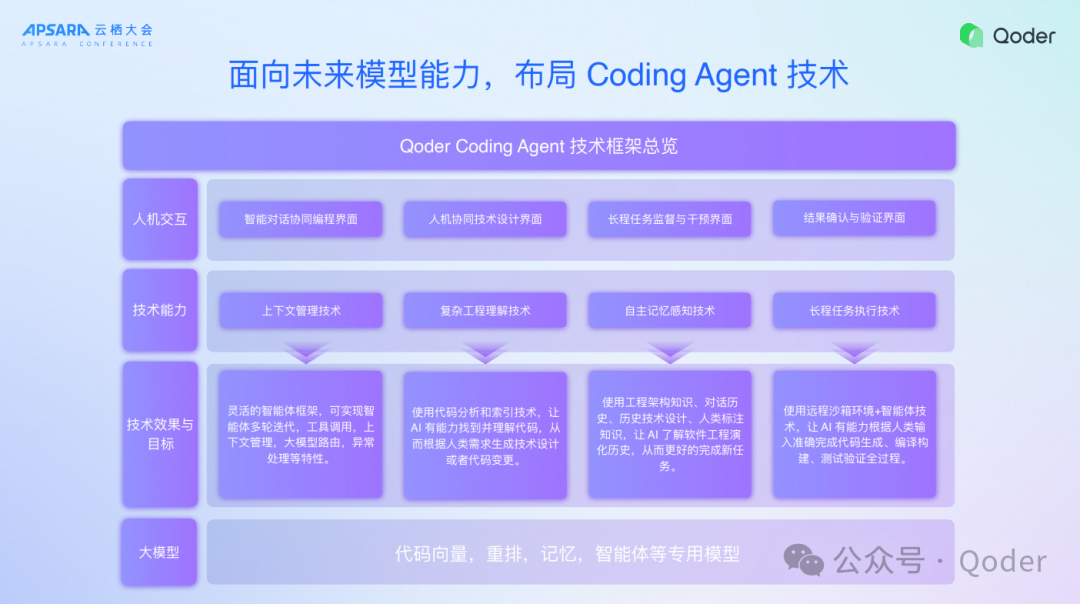
第二个就是Agent能力,我们面向未来的模型能力布局了Coding Agent技术。通过我们对于Agent技术的判断,实现了四种非常不一样的人机交互模式。首先是智能对话的模式,这个是传统Agent Mode;接下来人机协同技术设计界面、长程任务监督与干预界面、结果确认与验证界面这三个模式都是面向未来的委派式的人机协同交互模式。大家认为长程任务也可以使用CLI运行,为什么要用IDE,这就是开发者对于复杂任务的掌控。当任务越来越大,开发者如何洞察它、掌握它以及确认它是OK的,就一定需要复杂的GUI或者是复杂的研发流程协助的,而不是一句话就可以搞定,所有的交互一定是复杂的,任务复杂了,交互一定复杂,所以在这种背景下我们设计了一系列的交互的界面。
再深入就是支撑交互界面的核心技术,包括上下文管理技术、复杂工程管理技术、复杂工程理解和自主的记忆感知。今天除了拥有世界顶级的模型以外,包括代码向量模型、重排模型、记忆模型、Wiki模型还有NES补全模型,全部都是我们精心训练的。这些模型在相应的性能和推理速度上都达到了世界非常领先的水平,这也是我们产品相较于其他产品明显感觉到不同的地方。
三、打造完整、极致的上下文工程能力
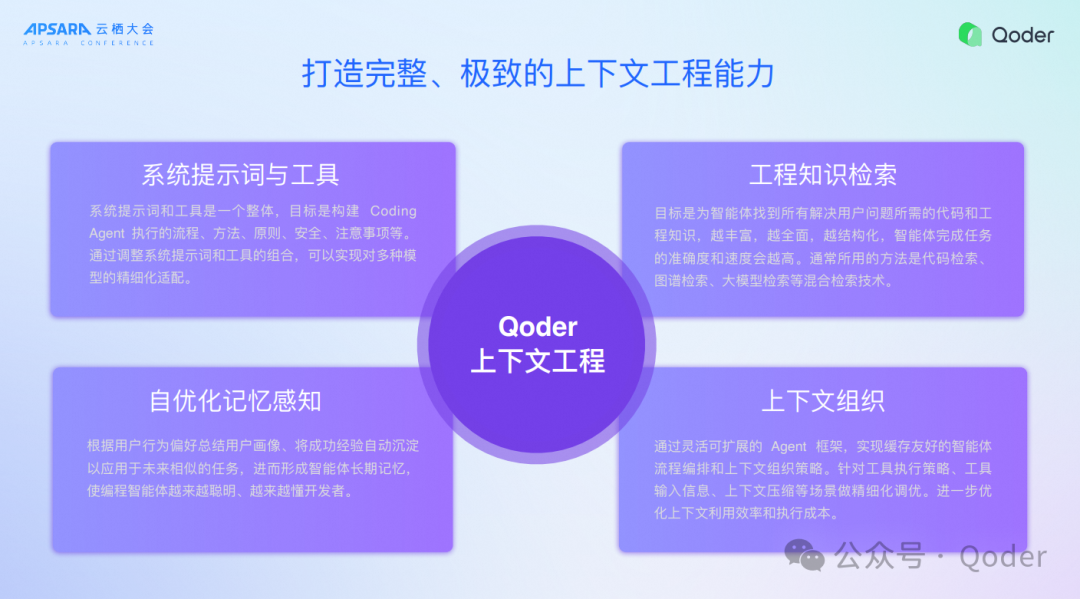
我们是如何打造完整、极致上下文工程能力的?其实刚开始就提到了做Agent最重要的就是上下文工程,包括四部分:
-
系统提示词与工具:所有的大模型都有个性,不同的大模型对提示词的感知不一样,我们要针对不同的模型特点设计不同的工具,这是非常复杂的部分需要大量的评测和复杂的Agent框架去高效完成。
-
高效检索:快速检索到知识代码和知识,给到大模型,这块的核心要点就是全面、结构化,而且信息密度要足够高。我们可以用一个超大上下文把所有的东西都塞进去,但是带来的后果是模型注意力的下降、成本的暴增、速度变慢,这个结果开发者是不买账的。今天我们要用最精准的方式找到解决问题最相关的代码和知识送给模型,这是核心要突破的点。
-
自优化记忆感知:我们是希望能够在开发者跟AI对话过程中,逐步让AI总结开发者的行为习惯和过去的经验教训,形成一个记忆的体系,实现最懂开发者习惯和工作的人就是AI。为什么今天一定要做记忆?还有一个数据跟大家分享,虽然一再强调rules是实现更高效果的核心,就是要打造各种各样的rules给大模型,但是实际上能够把rules用得好的人是百分之十以下,真正使用rules的也是非常小的比例,绝大部分的开发者是没有能力对Agent做精细的调教,这样效果就差了。我们用AI帮大家形成rules,所以记忆感知有一部分能力就是自优化、自迭代的rules,通过不断地跟AI潜移默化的过程中,就让rules变得丰富,这也是我们今天能够给大家一个非常强能力核心的基础。
-
上下文组织:通过灵活可扩展的Agent框架,实现缓存友好的智能体流程编排和上下文组织策略。针对工具执行策略、工具输入信息、上下文压缩等场景做经下滑调优,进一步优化上下文利用效率和执行成本。
四、新一代智能工程知识、代码检索技术
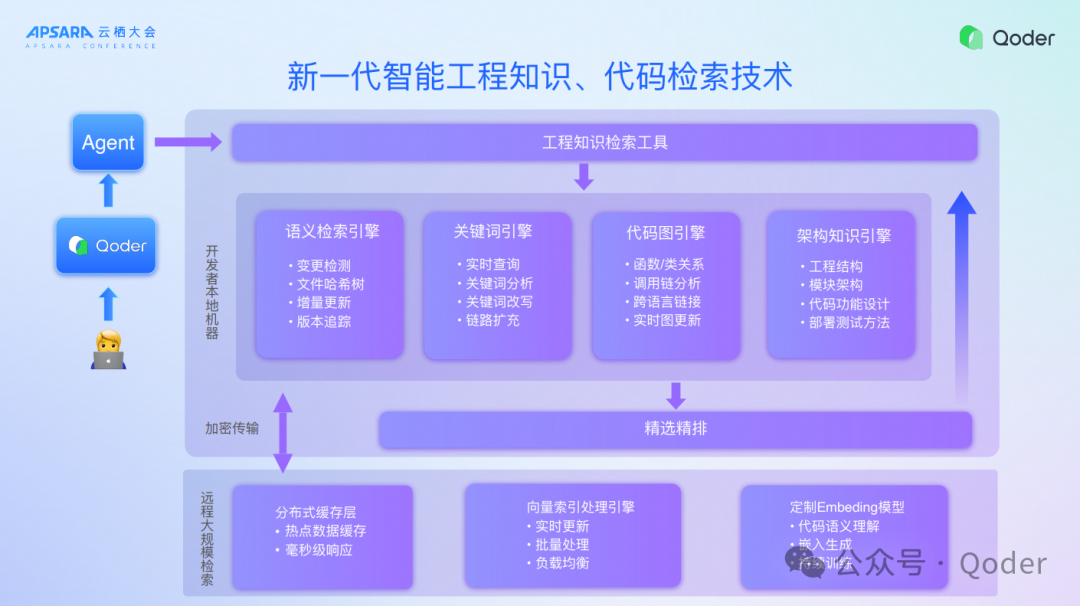
最早在2023年、2024年做代码的语义检索,就是传统的RAG模式,通过Embedding、ranker去做代码检索,但是我们发现这还不够,今天我们已经从传统的RAG的代码结构引擎变成真正意义的Context Engineer。现在传给开发者已经不是关键词了,而变成了一句话,今天大模型希望开发者给他返回什么样的东西,然后开发者通过语义关键词引擎、代码图谱引擎和架构知识引擎,告诉大模型解决这个问题需要这些代码,通过非常结构化的方式传给它。好处是什么?一次性获取到所有解决问题的代码,不需要进一步迭代了,就带来了效率和成本大幅度的提升,解决问题更加精准。所以我们已经通过一些技术的能力将整个变成了Context Engineer。
五、具备自优化能力的记忆感知技术
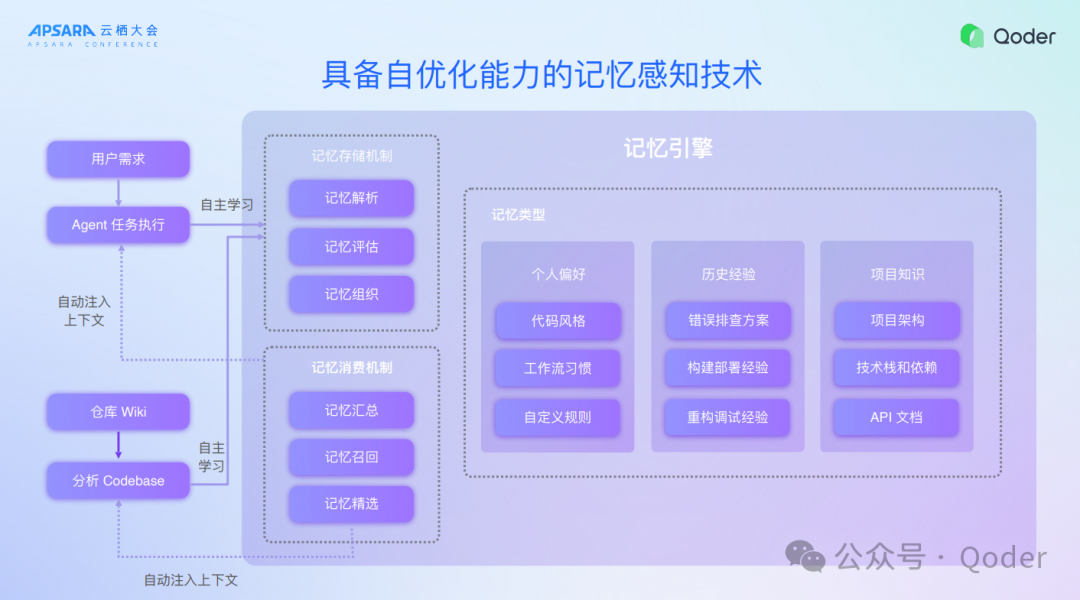
我们开发者常说记忆系统是一个门槛比较低,人人都能做一个记忆系统,但要产生效果非常难。今天Qoder也是全球最早一波,甚至是现在做的功能最复杂的记忆感知体系。我们会根据开发者的代码进行自动的抽取,也可以根据开发者跟AI Agent的对话做实时的抽取,背后有计算引擎考虑记忆的融合、汇总以及遗忘相关的机制,希望AI能够模拟人,记住我们的行为、习惯以及我们的偏好,包括个人偏好、历史经验、系统知识,所有这一套再跟Context Engineer结合,就会发现现在AI不但能够了解今天代码库里面所有的细节,而且还能够知道开发者想要什么,提升开发者效率,避免每次对话都跟全新的人打交道一样,例如上一个对话纠正了一个问题,下一次继续犯错,所以在Qoder里面就不会发生这样的问题,就是因为有了记忆感知体系。
六、缓存友好的上下文管理技术
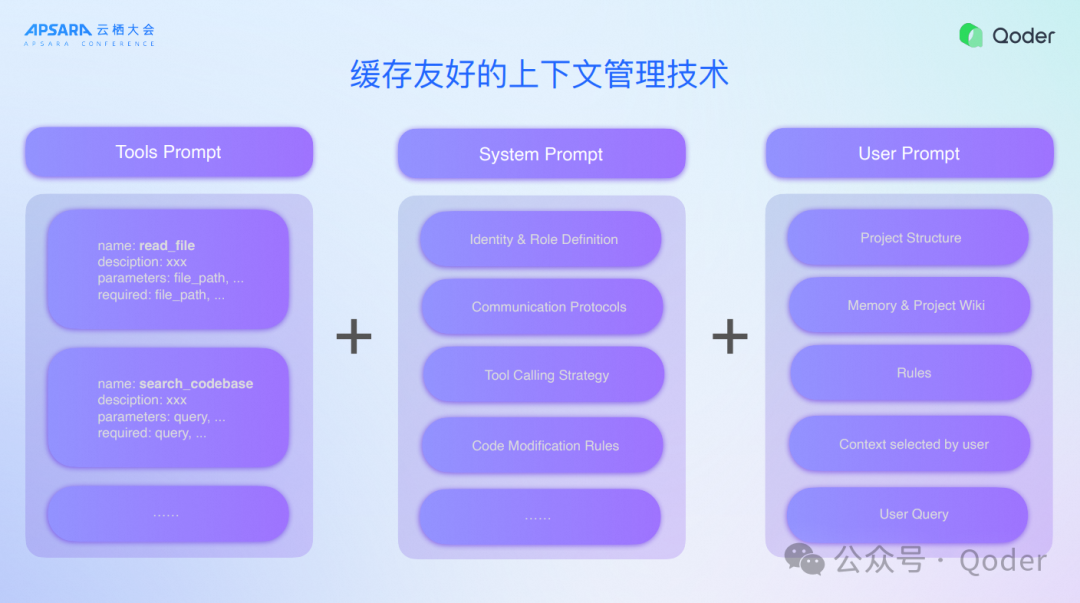
我们打造了一个缓存友好的上下文管理技术,所有做Agent最重要的就是做缓存友好的上下文管理,尤其是我们给大家提供的能力是200K上下文。我们从一开始就定义要给大家提供非常长的上下文解决问题,这个过程当中有Tools Prompt精调、System Prompt精调以及User Prompt,包含工程结构、记忆、Rules,还有用户选择context和用户query,所有的这些信息用一个非常复杂的结构拼起来,传递给大模型,让大模型才能很好地帮助我们精准地完成任务。
七、智能体效果评测体系
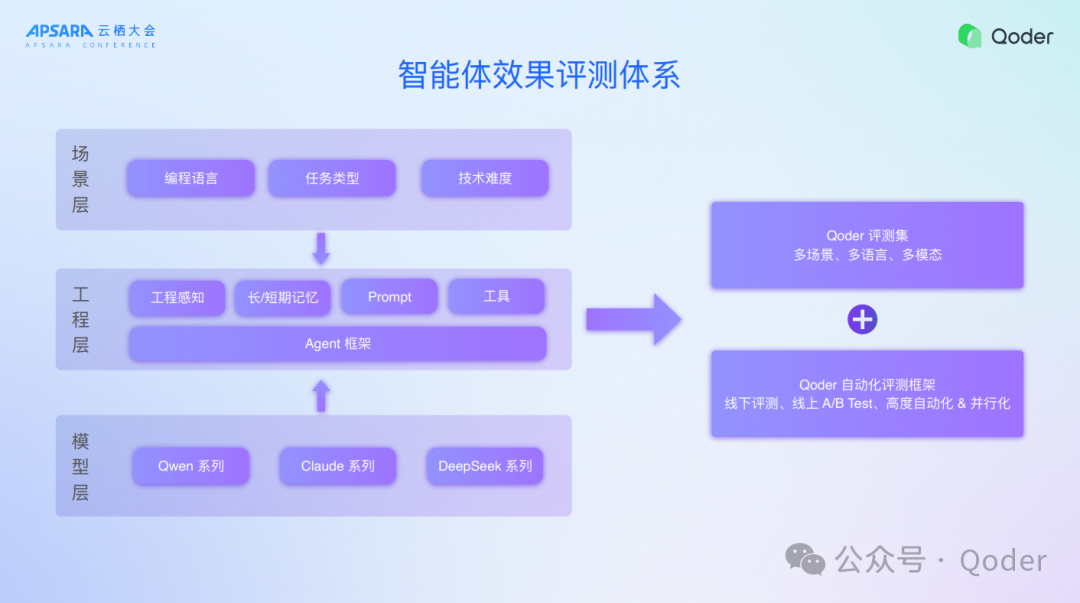
最后是评测,怎么知道效果变好了、开发者哪里有问题,哪个模型适合什么场景,有什么偏好,怎样路由等,我们希望实现模型的自动选择。这是一个技术潮流,最新的OpenAI发布了GPT5以后,就把模型选择器下下掉了,它认为这个是一个糟糕的设计,开发者很难知道模型怎么选,模型能力越来越强,边界越来越模糊,选择的难度就更大了。今天我们希望通过一个比较复杂的评测体系,能够当一个模型推出的时候,可以帮助大家做好相应的评测和路由,最终达到很好的效果。现在越来越多的开发者是为了效果买单,而不是说接入了多少款模型,最终要的是效果、解决问题的速度。
Qoder未来的技术挑战与应对
Qoder未来的技术挑战与应对,我从来没有见过软件工程或者效能产品发展速度如此之快,所有的范式只有一年的生命周期,我们畅想一下未来发生什么。
一、从设计、执行到验证
全链路软件研发实现更高准确率
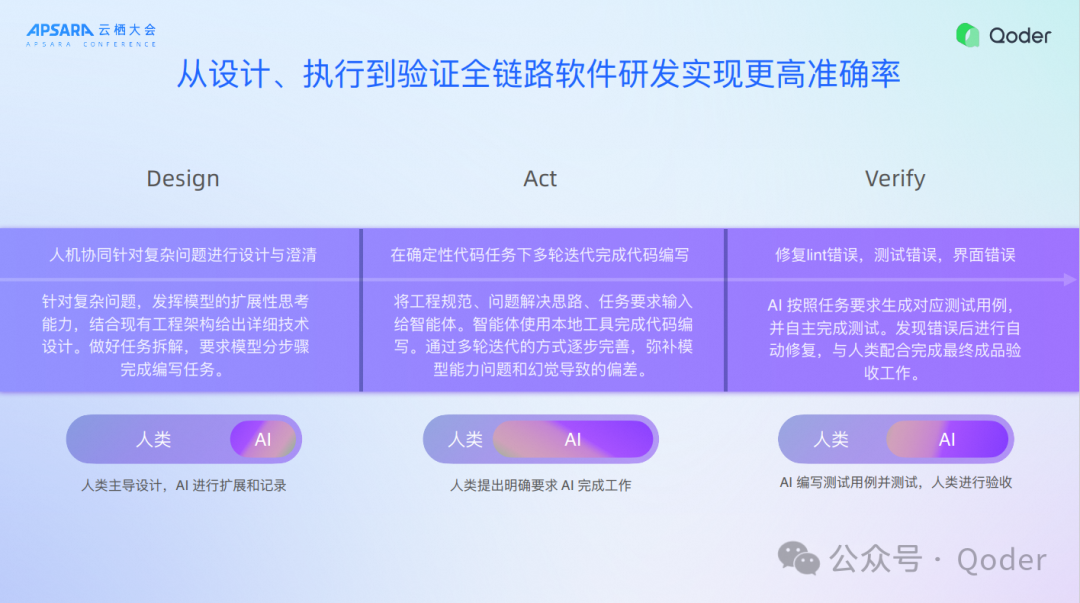
我们认为今天要实现软件研发,更高的准确率要做好三个阶段:
第一个阶段:Design,今天要想实现效能的提升,异步的委派,最重要的还是表达清楚需求。我们设计了Agent专门帮助开发者澄清需求,未来有80%的设计工作可以由AI来做。设计工作是一个价值高地,如果今天AI能够统领代码库,甚至多个微服务的架构都能够精确地设计好技术方案,这个对开发者来讲时间是大大地提升,在座的开发者应该有体感,实际上我们很多工作都是在这儿,在前面的需求澄清和设计阶段花费了大量的精力,我们希望通过Qoder能够把这块辅助了。
第二个阶段:Act,我们做Agent Mode就是做这块,能够把代码生成做得足够好。
第三个阶段:Verify,这个大家都没有做好的,随着代码生成越来越多,不能靠人去Verify了,这个过程中除了简单的单元测试,link错误修复,界面错误以外,我们今天能不能做集成测试,甚至是复杂的UI测试,这个也是价值高地。
如果这三个都能做到非常好,那一个任务端到端的交付就成为现实,这个时候效率就跟现在完全不一样,现在还是需要人手把手把着AI。
二、多智能体架构应对更长更复杂任务
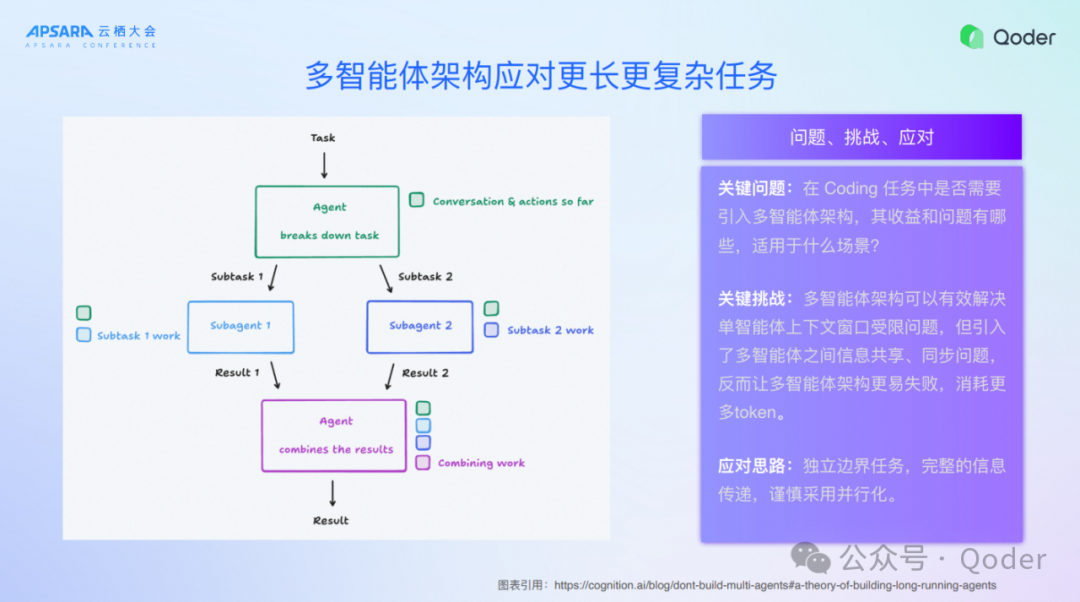
如果要实现三阶段能力的端到端,一定需要一些技术的支撑,多智能体架构就是未来我们应对更长、更复杂任务的基石。这张图是Devin公司做的,他是最早做多智能体架构的,他们在上面踩了很多坑,其实我们做多智能体架构的时候,核心要解决单智能体的上下文窗口受限问题,实现更长、更复杂任务,但是同时也引入了多智能体之间的信息共享、同步问题,有可能让多智能体更容易失败。
所以,我们一定要对多智能体进行精调,而且每一个Sub Agent都需要做非常好的开发,就像我们开发Agent Mode下面的工具一样,实际上Sub Agent本质上也是一个工具,完成单个任务的时候要的内聚,以及跟主Agent要有足够好的协同,这个系统是非常精妙的系统,我们要独立边界、完整的信息传递谨慎采用并行化,通过这些才能达到更好、更长任务的实现。
三、更多专用领域模型突破复杂任务成本瓶颈

最后的核心,我们做的所有的产品没有模型一定就没有竞争力的,在这个过程中,我们目标是用更多专业的模型突破复杂任务的成本和性能的上限,我们做了一系列的模型支撑Qoder,但是背后有几十个模型为大家服务,最核心的就是智能体大模型。前几天也看到了Qwen3 Qoder或者Qwen 3 Max等等一系列的模型发布,海外也有非常多的模型发布,我们会第一时间对这些模型进行评测和支持,实现更长上下文、更加复杂任务的执行。
除了这些还不够,还需要一系列模型辅助,尤其是未来的Design、Act、Verify三阶段里面需要大量的模型支撑,包括记忆类模型、检索类模型、Wiki生成的模型,以及各种Tools也需要专业训练的模型,会话总结、代码应用、Terminal的处理都可以用一个模型处理,可以让场景更加泛化,信息提取更加精准,效果更加好,以及最早做的补全NES模型,整个这一套成了Qoder效果拔群的基础,也是我们最擅长,也是最能做好的事情。
今天我的分享就到这里,谢谢大家!
欢迎用户到Qoder官网免费下载体验!
官网地址:
下载体验链接:https://qoder.com

关注我,掌握Qoder最新动态


















 5216
5216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









