







1.hadoop简介
hadoop是当今流行的分布式并行计算框架和大数据解决方案,利用基于商品硬件的计算机集群,具有容错性好和伸缩性强的特点。造价低廉,技术通用开放,维护和管理方便。特别适合超大数据的处理,对于TB和PB级的数据都可以应付(当然需要往集群中加入更多的机器,上百、上千或者上万台机器的hadoop集群都屡见不鲜)。
与其他并行计算不同的一个鲜明特点是其计算理念:代码向数据处移动,而不是数据向代码处移动。
理解这个计算理念是深入理解hadoop的基石。试想我们用传统方法怎么处理一个文件:将文件拿到代码运行的机器,然后以拿到的文件作为程序的输入,在本地计算机进行处理,最后将结果输出。但是当文件特别大时比如10TB,而本地计算机的磁盘( 如100G)和内存(如8G)较小时,用这种方式来处理是不可能的;即使将文件分成片(每片足够小都可被本地计算机处理)运送过来处理,但是处理完成恐怕也得很长时间以后。因此可行的做法是将处理的代码发送到数据所在的机器,并且数据所在的环境最好是多个计算机组成的集群,集群里的机器并行运算,逻辑上犹如一个超大硬盘超大内存的超大型计算机。
2.基本概念与术语
hadoop基于2种基本技术,一是hadoop分布式文件系统即hdfs,另一个是mapreduce计算框架。hadoop的生产环境的最初目标操作系统为linux(Redhat,SuSE,Oracle Linux,Ubuntu等都可以),经过Hortonworks和微软的合作,hadoop运行的操作系统也可以是Windows。
hdfs承担存储功能,mapreduce承担计算功能。
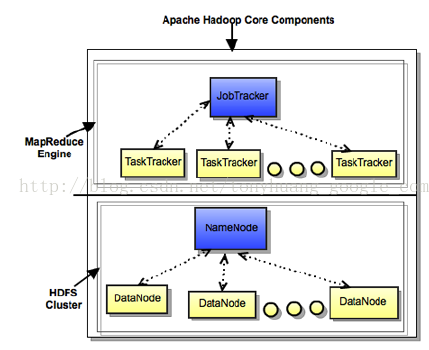
mapreduce有2种版本,一是mapreduce v1,二是mapreduce v2.无论v1还是v2,都支持四个基本概念:name node, job tracker, data node,task tracker.
理解这四个基本概念是理解hadoop集群的基础。
hdfs:无论文件多大,hadoop都可以容纳:添加新的机器以扩充其容量,一个大文件可以按块分布在不同机器上,各个机器上的文件分布都统一在name node上管理。
name node:提供元数据管理和名字空间管理。任何文件的分布情况都可从name node 上查询得知。
data node : 每台data机器上都有一个data node,负责数据管理。
job tracker :负责mapreduce 计算任务的资源管理和调度,会向各个data node分派任务。
task tracker:每台data node机器上有一个task tracker,负责监控本机上的计算任务执行情况。
name node, data node, job tracker和task tracker是OS的四个守护进程,是hadoop集群运行的基础。
因为data node 所在的机器既能承担计算任务又能承担存储任务,因此data node机器上同时运行task tracker.也可以将name node和job tracker 运行在一台机器上。
从逻辑上看,hadoop集群如下图所示:
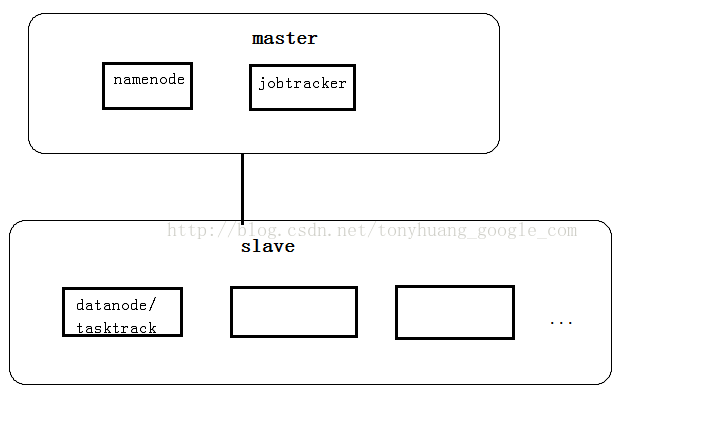
物理结构上,hadoop集群如下图所示:
也可以将承担matser角色的组件全都运行在一台机器上
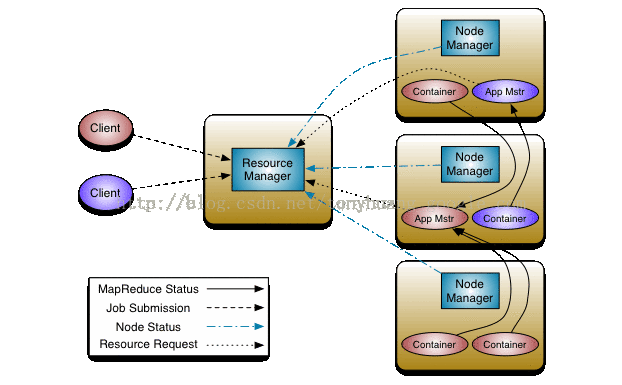
自从hadoop 2.x后,其资源调度框架改为YARN (Yet Another Resource Negotiator)
YARN的逻辑结构如下:
3.所需要的软硬件环境
硬件:
选项一:准备若干台计算机,pc机、小型机、服务器、笔记本电脑等都可以。
选项二:在一台计算机上利用虚拟化软件(vmware,oracle virtualbox等)跑多台虚拟机。
软件:
操作系统:linux (如ubuntu, redhat, SUSE等)
JAVA: jdk1.6或者jdk1.7
hadoop软件包: hadoop-1.1.2 或者0.23.x。 下载地址:http://apache.etoak.com/hadoop/common/
4.正式搭建hadoop集群(hadoop-1.x或0.23.x)
假设我们要搭建一个有三个节点的hadoop cluster,一个节点作为master运行namenode,jobtracker(主机名为master)和seconday namenode;其他两个节点作为 slave运行datanode和 tasktracker(主机名分别为slave1,slave2)。每个节点操作系统都是ubuntu。
4.1 在每个节点上建立一个同名用户,比如hduser。
以下步骤尽量以hduser登录并执行。
4.2 在每个节点上确保java 已经安装。
4.3 在每个节点运行 sudo apt-get install ssh 来安装ssh(以root用户运行此命令也可,hduser用户也可使用ssh)。
4.4 配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,如果已经互连则忽略此步骤。
4.5 在每个节点上执行以下命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
4.6 在master上执行:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
如果是RPM-based Linux,如 redHat,还需执行 chmod 644 ~/.ssh/authorized_keys
---保证可在master无需密码以ssh登录到本机(ssh localhost)
scp ~/.ssh/authorized_keys slave1:/home/hduser/.ssh/
scp ~/.ssh/authorized_keys slave2:/home/hduser/.ssh/
---保证可在master无需密码以ssh登录到slave1,slave2(ssh salve1 ; ssh slave2)
4.7 在master上将hadoop安装包解压安装,比如安装到~/hadoop
4.8 在master上配置conf/hadoop-env.sh文件
#添加
export JAVA_HOME=/usr/lib/jvm/java-6-sun/ (这里修改为你的jdk的安装位置。 )
可以先在master上进行,然后用scp拷贝到其他机器 (scp ~/hadoop/conf/hadoop-env.sh hduser@slave:~/hadoop/conf/hadoop-env.sh)。
4.9 在master上 配置~/hadoop/conf/slaves文件,每行一个机器名
slave1
slave2
4.10 在master上编辑hadoop配置文件~/hadoop/conf/core-site.xml, ~/hadoop/conf/hdfs-site.xml, ~/hadoop/conf/mapred-site.xml
core-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value> //根据你的环境修改
</property>
<property>
<name>hadoop.tmp.dir</name>//Hadoop的默认临时路径,这个最好配置(如果不配置hadoop有时会莫名其妙无法启动),
<value>/home/hduser/tmp/</value>
</property>
</configuration>
hdfs-site.xml :
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value> //根据你的环境修改
</property>
</configuration>
然后用scp将整个~/hadoop拷贝到其他机器 (scp -rp ~/hadoop hduser@slave:~/)
4.10 格式化文件系统
~/hadoop/bin/hadoop namenode -format
4.11 启动hadoop
~/hadoop/bin/start-all.sh
如果要停止hadoop :~/hadoop/bin/stop-all.sh
4.12 验证hadoop 运行:
在master浏览器上执行: http://localhost:50030 和http://localhost:50070/ 可以分别看到mapreduce job和hdfs
4.13 加入新节点:
在NameNode节点上修改$HADOOP_HOME/conf/slaves文件,加入新加节点主机名,再建立到新加节点无密码的SSH连接
运行启动命令:
start-all.sh















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









