






数据形式:
user_id, brand_id, type, visit_datetime
10944750, 13451, 0, 6月4日
10944750, 13451, 2, 6月4日
10944750, 13451, 2, 6月4日
10944750, 13451, 0, 6月4日
10944750, 13451, 0, 6月4日
.......
其中user_id:用户号
brand_id:商品号
type:0:代表点击 ,1:代表购买,2:代表收藏,3:代表加入购物车,
visit_datetime:访问商品页面的日期
运用协同过滤算法最后需要处理的数据形式应该是:用户号,商品号,权值(用户对商品喜好程度)
所以要进行数据预处理来计算权值。
权值计算:
首先重设type,表达为基本权值:0.1:代表点击 ,2:代表购买,1:代表收藏,1:代表加入购物车,
在此考虑用简单的时间序列模型来表现客户的行为:考虑到客户的点击行为有一定时间周期性(也要基于商品类型:比如消耗品)将数据分成每7日(周一到周日)。随着时间增长,客户的点击就代表跟商品有更高的依赖,加权值就增加。
比如:用户A在第一周点击了x1商品10次,那么权值计算就是:0.1×1×10
如果在接下来第二周和第三周又分别点击了8次和6次,那么权值计算:0.1×1×10+0.1×2×8+0.1×3×6
计算出每种type的权值,相加即为此用户对该商品的总权值,即商品喜好程度。
数据清理:
设置阈值,低于多少的权值的商品应该忽略:这点用f值来评判。
A:检索到的,相关的 (搜到的也想要的)
B:未检索到的,但是相关的 (没搜到,然而实际上想要的)
C:检索到的,但是不相关的 (搜到的但没用的)
D:未检索到的,也不相关的 (没搜到也没用的)
precision(准确率)= A/A+C recall(找回率)=A/A+B
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)
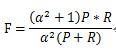
其中a即为设置的阈值.
协同过滤算法:
linux平台,hadoop,hive,mahout
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









