







一、前言
本文将先讲述Bitmap(位图算法)的基本原理以及使用场景,进而深入分析Bitmap的一种实现算法:RoaringBitmap,通过对其数据结构以及部分核心源码的分析去了解实现过程
RoaringBitmap相关官方文章地址:
- github地址
- 论文-《Better bitmap performance with Roaring bitmaps》
- 论文-《Consistently faster and smaller compressed bitmaps with Roaring》
二、Bitmap
1、什么是位图
我们先来看一个经常被提到的面试问题:
有40亿个不重复且未排序的unsigned int整数,如何用一台内存为2G的PC判断某一个数是否在这40亿个整数中
先看下处理这40亿个整数至少需要消耗多少内存:一个int占4个字节,40亿*4/1024/1024/1024≈14.9G 远远大于指定的2G内存,按照通常的int存储明显无法在2G内存中工作,这时候就需要位图来处理了
位图就是用一个bit位来标记一个数字,第N位(从0开始)的bit代表着整数N,1即存在,0即不存在
举个例子:在一个1byte的内存空间中插入2、3、5、6四个数字
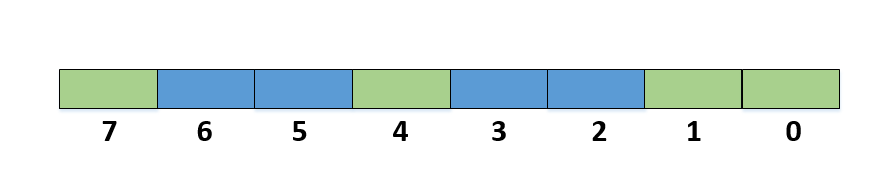
从上图可以看出,我们在1byte的内存空间,即8位中插入2、3、5、6,只需要将对应下标的bit从0(绿色)置为1(蓝色)即可,原本需要耗费4个int即16byte去存储,现在1个byte就解决了。
回到开始的问题,若是连续的40亿个数,则需要40亿/8/1024/1024≈476MB,大大降低了内存消耗
2、位图的应用
位图经常被用作处理海量数据的压缩,并对其进行排序、去重、查询、差集、并集、交集等操作
3、位图存在的问题
虽说上面的例子中,我们将14.9G的内存压缩为了476MB,节省了将近97%的内存空间,但这是基于数据连续的情况,即数据密集
若只存放40亿这1个数字,仍然需要476MB的内存空间去存储,那么就得不偿失了,所以只有当数据较为密集的时候使用位图才具有优势
为了解决位图在稀疏数据下的问题,目前有多种压缩方案以减少内存提高效率:WAH、EWAH、CONCISE、RoaringBitmap等。前三种采用行程长度编码(Run-length-encoding)进行压缩,RoaringBitmap则是在压缩上更进一步,并且兼顾了性能
下面是github上对于几种bitmap实现方案的描述
How does Roaring compares with the alternatives?
Most alternatives to Roaring are part of a larger family of compressed bitmaps that are run-length-encoded bitmaps. They identify long runs of 1s or 0s and they represent them with a marker word. If you have a local mix of 1s and 0, you use an uncompressed word.
There are many formats in this family:
- Oracle’s BBC is an obsolete format at this point: though it may provide good compression, it is likely much slower than more recent alternatives due to excessive branching.
WAH is a patented variation on BBC that provides better performance.- Concise is a variation on the patented WAH. It some specific instances, it can compress much better than WAH (up to 2x better), but it is generally slower.
- EWAH is both free of patent, and it is faster than all the above. On the downside, it does not compress quite as well. It is faster because it allows some form of “skipping” over uncompressed words. So though none of these formats are great at random access, EWAH is better than the alternatives.
There is a big problem with these formats however that can hurt you badly in some cases: there is no random access. If you want to check whether a given value is present in the set, you have to start from the beginning and “uncompress” the whole thing. This means that if you want to intersect a big set with a large set, you still have to uncompress the whole big set in the worst case…
Roaring solves this problem. It works in the following manner. It divides the data into chunks of 216 integers (e.g., [0, 216), [216, 2 x 216), …). Within a chunk, it can use an uncompressed bitmap, a simple list of integers, or a list of runs. Whatever format it uses, they all allow you to check for the present of any one value quickly (e.g., with a binary search). The net result is that Roaring can compute many operations much faster that run-length-encoded formats like WAH, EWAH, Concise… Maybe surprisingly, Roaring also generally offers better compression ratios.
三、RoaringBitmap
1、实现思路
RoaringBitmap(以下简称RBM)处理的是int型整数,RBM将一个32位的int拆分为高16位与低16位分开去处理,其中高16位作为索引,低16位作为实际存储数据。
RBM按照索引将数据分块存放,每个块中的整数共享高16位,第1个块包含了[0,216),它们的高16位均为0,第2个块包含了[216,2x216),它们的高16位均为1…以此类推,每个RBM中最多可以有216个块,每个块中最多可以存放216个数据
若不是很理解可以看下面这张图

下面我们看下RBM的数据结构:
RoaringArray:每个RBM都包含了一个RoaringArray,名字是highLowContainer,主要有下面几个重要属性:
keys:short数组,用来存储高16位作为索引
values:Container数组,用来存储低16位数据
size:用来记录当前RBM包含的key-value有效数量
注意:keys数组和values数组是一一对应的,且keys永远保证有序,这是为了之后索引的二分查找
RoaringBitmap
RoaringArray highLowContainer = null;
/**
* Create an empty bitmap
*/
public RoaringBitmap() {
highLowContainer = new RoaringArray();
}
RoaringArray
static final int INITIAL_CAPACITY = 4;
//存储高16位作为索引
short[] keys = null;
//用不同的Container存储低16位
Container[] values = null;
int size = 0;
protected RoaringArray() {
this(INITIAL_CAPACITY);
}
我们大致简单的总结一下RBM实现原理:
将一个32位无符号整数按照高16位分块处理,其中高16位作为索引存储在short数组中,低16位作为数据存储在某个特定的Container数组中。存储数据时,先根据高16位找到对应的索引key(二分查找),由于key和value是一一对应的,即找到了对应的Container。若key存在则将低16位放入对应的Container中,若不存在则创建一个key和对应的Container,并将低16位放入Container中
RBM的核心就是Container,也是RBM优于其他方案的关键,下面将对其进行介绍
2、Container
Container用于存储低16位的数据,根据数据量以及疏密程度分为以下3个容器:
ArrayContainerBitmapContainerRunContainer
下面将先对3种容器做一个大概的介绍,具体实现流程可以结合下一节的源码分析
①ArrayContainer
//ArrayContainer允许的最大数据量
static final int DEFAULT_MAX_SIZE = 4096;// containers with DEFAULT_MAX_SZE or less integers
// should be ArrayContainers
//记录基数
protected int cardinality = 0;
//用short数组存储数据
short[] content;
ArrayContainer采用简单的short数组存储低16位数据,content始终有序且不重复,方便二分查找
可以看出,ArrayContainer并没有采用任何的压缩算法,只是简单的将低16存储在short[]中,所以ArrayContainer占用的内存空间大小和存储的数据量呈线性关系:short为2字节,因此n个数据为2n字节
随着数据量的增大,ArrayContainer占用的内存空间逐渐增多,且由于是二分查找,时间复杂度为O(logn),查找效率也会大打折扣,因此ArrayContainer规定最大数据量是4096,即8kb。至于为什么阈值是4096,我们需要结合下一个Container一并分析:BitmapContainer
②BitmapContainer
//最大容量
protected static final int MAX_CAPACITY = 1 << 16;
//用一个定长的long数组按bit存储数据
final long[] bitmap;
//记录基数
int cardinality;
BitmapContainer采用long数组存储低16位数据,这就是一个未压缩的普通位图,每一个bit位置代表一个数字。我们上面说过每一个Container最多可以处理216个数字,基于位图的原理,我们就需要216个bit,每个long是8字节64bit,所以需要216/64=1024个long
BitmapContainer构造方法会初始化一个长度为1024的long数组,因此BitmapContainer无论是存1个数据,10个数据还是最大65536个数据,都始终占据着8kb的内存空间。这同样解释了为什么ArrayContainer数据量的最大阈值是4096
由于是直接进行位运算,该容器CRUD的时间复杂度为O(1)
③RunContainer
private short[] valueslength;// we interleave values and lengths, so
// that if you have the values 11,12,13,14,15, you store that as 11,4 where 4 means that beyond 11
// itself, there are
// 4 contiguous values that follows.
// Other example: e.g., 1, 10, 20,0, 31,2 would be a concise representation of 1, 2, ..., 11, 20,
// 31, 32, 33
int nbrruns = 0;// how many runs, this number should fit in 16 bits.
在RBM创立初期只有以上两种容器,RunContainer其实是在后期加入的。RunContainer是基于之前提到的RLE算法进行压缩的,主要解决了大量连续数据的问题。
举例说明:3,4,5,10,20,21,22,23这样一组数据会被优化成3,2,10,0,20,3,原理很简单,就是记录初始数字以及连续的数量,并把压缩后的数据记录在short数组中
显而易见,这种压缩方式对于数据的疏密程度非常敏感,举两个最极端的例子:如果这个Container中所有数据都是连续的,也就是[0,1,2.....65535],压缩后为0,65535,即2个short,4字节。若这个Container中所有数据都是间断的(都是偶数或奇数),也就是[0,2,4,6....65532,65534],压缩后为0,0,2,0.....65534,0,这不仅没有压缩反而膨胀了一倍,65536个short,即128kb
因此是否选择RunContainer是需要判断的,RBM提供了一个转化方法runOptimize()用于对比和其他两种Container的空间大小,若占据优势则会进行转化
了解了3种Container,我们看一下下面这组数据应该如何存储
RoaringBitmap roaringBitmap = new RoaringBitmap();
roaringBitmap.add(1);
roaringBitmap.add(10);
roaringBitmap.add(100);
roaringBitmap.add(1000);
roaringBitmap.add(10000);
for (int i = 65536; i < 65536*2; i+=2) {
roaringBitmap.add(i);
}
roaringBitmap.add(65536L*3, 65536L*4);
roaringBitmap.runOptimize();
调用runOptimize()前

调用runOptimize()后

先根据高16位分割数据,很明显可以分为3组,第一组的索引是0,数据是1、10、100、1000、10000;第二组的索引是1,数据是从65536到131071间的所有偶数;第三组的索引是3,数据是从196608到262143之间的所有整数。从结果我们可以看出索引keys是顺序排布的,第一组数据由于数据量小于4096,所以是ArrayContainer;第二组数据数据量大于4096,所以是BitmapContainer;第三组数据量大于4096,所以是BitmapContainer。调用runOptimize()方法后,由于第三组数据通过RLE算法优化后会占用更小的空间,所以转化为了RunContainer
3、源码分析
①添加
/**
* Add the value to the container (set the value to "true"), whether it already appears or not.
*
* Java lacks native unsigned integers but the x argument is considered to be unsigned.
* Within bitmaps, numbers are ordered according to {@link Integer#compareUnsigned}.
* We order the numbers like 0, 1, ..., 2147483647, -2147483648, -2147483647,..., -1.
*
* @param x integer value
*/
@Override
public void add(final int x) {
// 获取待插入数x的高16位
final short hb = Util.highbits(x);
// 计算高16位对应的索引值的下标位置
final int i = highLowContainer.getIndex(hb);
// 索引下标大于0说明该索引已存在且创建了对应的Container,则将低16位存入该Container中
if (i >= 0) {
highLowContainer.setContainerAtIndex(i,
highLowContainer.getContainerAtIndex(i).add(Util.lowbits(x)));
// 若索引下标小于0说明该索引不存在,则直接创建一个ArrayContainer并将低16位放入其中
} else {
final ArrayContainer newac = new ArrayContainer();
highLowContainer.insertNewKeyValueAt(-i - 1, hb, newac.add(Util.lowbits(x)));
}
}
RBM添加元素的外部代码就是这样的,结合注释很容易理解,下面我们看下内部具体过程:
首先我们看add方法上面的一段注释,结合github上的说明
Java lacks native unsigned integers but integers are still considered to be unsigned within Roaring and ordered according to Integer.compareUnsigned. This means that Java will order the numbers like so 0, 1, …, 2147483647, -2147483648, -2147483647,…, -1. To interpret correctly, you can use Integer.toUnsignedLong and Integer.toUnsignedString.
java缺少原生的无符号int,但是在RBM中加入的数字是被认为无符号的,于是RBM根据Integer.compareUnsigned的结果对数字进行排序,从小到大依次是0, 1, ..., 2147483647, -2147483648, -2147483647,..., -1。
取数字x的高16位
// 将x右移16位并转化为short,就是取x的高16位
protected static short highbits(int x) {
return (short) (x >>> 16);
}
计算高16位对应的索引值的下标位置
// involves a binary search
protected int getIndex(short x) {
// before the binary search, we optimize for frequent cases
// 两种常见场景可以快速判断,无需走二分查找:1、RoaringArray的大小为0,直接返回-1
// 2、当前索引是keys数组中的最大值,直接返回size-1,之所以可以这样判断是因为keys是有序的
if ((size == 0) || (keys[size - 1] == x)) {
return size - 1;
}
// no luck we have to go through the list
// 其他情况需要走二分查找
return this.binarySearch(0, size, x);
}
private int binarySearch(int begin, int end, short key) {
return Util.unsignedBinarySearch(keys, begin, end, key);
}
/**
* Look for value k in array in the range [begin,end). If the value is found, return its index. If
* not, return -(i+1) where i is the index where the value would be inserted. The array is assumed
* to contain sorted values where shorts are interpreted as unsigned integers.
*
* @param array array where we search
* @param begin first index (inclusive)
* @param end last index (exclusive)
* @param k value we search for
* @return count
*/
public static int unsignedBinarySearch(final short[] array, final int begin, final int end,
final short k) {
// 混合二分查找法:二分查找+顺序查找,始终采用该策略
if (USE_HYBRID_BINSEARCH) {
return hybridUnsignedBinarySearch(array, begin, end, k);
} else {
return branchyUnsignedBinarySearch(array, begin, end, k);
}
}
// starts with binary search and finishes with a sequential search
protected static int hybridUnsignedBinarySearch(final short[] array, final int begin,
final int end, final short k) {
int ikey = toIntUnsigned(k);
// next line accelerates the possibly common case where the value would
// be inserted at the end
if ((end > 0) && (toIntUnsigned(array[end - 1]) < ikey)) {
return -end - 1;
}
int low = begin;
int high = end - 1;
// 32 in the next line matches the size of a cache line
while (low + 32 <= high) {
final int middleIndex = (low + high) >>> 1;
final int middleValue = toIntUnsigned(array[middleIndex]);
if (middleValue < ikey) {
low = middleIndex + 1;
} else if (middleValue > ikey) {
high = middleIndex - 1;
} else {
return middleIndex;
}
}
// we finish the job with a sequential search
int x = low;
for (; x <= high; ++x) {
final int val = toIntUnsigned(array[x]);
if (val >= ikey) {
if (val == ikey) {
return x;
}
break;
}
}
return -(x + 1);
}
// 上面提到的无符号int,正数无变化,负数相当于+2^16
protected static int toIntUnsigned(short x) {
return x & 0xFFFF;
}
上面获取索引下标的过程采用了二分查找+顺序查找,若查找范围大于32则采用二分查找,否则进入顺序查找,查找过程不难理解就不赘述了。有一个需要注意的是若找到则返回对应索引的下标,没有找到则返回对应下标的负数,这是一个很巧妙的设计,同时传递了位置以及是否存在两层信息
接下来就是对索引下标正负分情况处理,若小于0,说明该索引不存在,则直接创建一个ArrayContainer并将低16位放入其中;若大于0,说明该索引已存在且创建了对应的Container,则将低16位存入该Container中。我们接下来分析核心部分,3种Container的add过程
- ArrayContainer添加过程
/**
* running time is in O(n) time if insert is not in order.
*/
@Override
public Container add(final short x) {
// 两种场景可以不走二分查找:1、基数为0
// 2、当前值大于容器中的最大值,之所以可以这样操作是因为content是有序的,最后一个即最大值
if (cardinality == 0 || (cardinality > 0
&& toIntUnsigned(x) > toIntUnsigned(content[cardinality - 1]))) {
// 基数大于等于阈值4096转化为BitmapContainer并添加元素,转化逻辑下面会有说明
if (cardinality >= DEFAULT_MAX_SIZE) {
return toBitmapContainer().add(x);
}
// 若基础大于等于content数组长度则需要扩容
if (cardinality >= this.content.length) {
increaseCapacity();
}
// 赋值
content[cardinality++] = x;
} else {
// 通过二分查找找到对应的插入位置
int loc = Util.unsignedBinarySearch(content, 0, cardinality, x);
//不存在,需要插入,存在则不处理直接返回(去重效果)
if (loc < 0) {
// Transform the ArrayContainer to a BitmapContainer
// when cardinality = DEFAULT_MAX_SIZE
// 同上,基数大于等于阈值4096转化为BitmapContainer并添加元素
if (cardinality >= DEFAULT_MAX_SIZE) {
return toBitmapContainer().add(x);
}
// 同上,若基础大于等于content数组长度则需要扩容
if (cardinality >= this.content.length) {
increaseCapacity();
}
// insertion : shift the elements > x by one position to
// the right
// and put x in it's appropriate place
// 通过拷贝数组将x插入content数组中
System.arraycopy(content, -loc - 1, content, -loc, cardinality + loc + 1);
content[-loc - 1] = x;
++cardinality;
}
}
return this;
}
ArrayContainer转化为BitmapContainer相关代码
/**
* Copies the data in a bitmap container.
*
* @return the bitmap container
*/
@Override
public BitmapContainer toBitmapContainer() {
BitmapContainer bc = new BitmapContainer();
bc.loadData(this);
return bc;
}
/**
* Create a bitmap container with all bits set to false
*/
public BitmapContainer() {
this.cardinality = 0;
// 长度固定为1024
this.bitmap = new long[MAX_CAPACITY / 64];
}
protected void loadData(final ArrayContainer arrayContainer) {
this.cardinality = arrayContainer.cardinality;
for (int k = 0; k < arrayContainer.cardinality; ++k) {
final short x = arrayContainer.content[k];
//循环赋值,这里的算法会在BitmapContainer添加过程中详述
bitmap[Util.toIntUnsigned(x) / 64] |= (1L << x);
}
}
扩容相关代码
// temporarily allow an illegally large size, as long as the operation creating
// the illegal container does not return it.
// 根据不同的情况进行扩容,不是很难理解
private void increaseCapacity(boolean allowIllegalSize) {
int newCapacity = (this.content.length == 0) ? DEFAULT_INIT_SIZE
: this.content.length < 64 ? this.content.length * 2
: this.content.length < 1067 ? this.content.length * 3 / 2
: this.content.length * 5 / 4;
// never allocate more than we will ever need
if (newCapacity > ArrayContainer.DEFAULT_MAX_SIZE && !allowIllegalSize) {
newCapacity = ArrayContainer.DEFAULT_MAX_SIZE;
}
// if we are within 1/16th of the max, go to max
if (newCapacity > ArrayContainer.DEFAULT_MAX_SIZE - ArrayContainer.DEFAULT_MAX_SIZE / 16
&& !allowIllegalSize) {
newCapacity = ArrayContainer.DEFAULT_MAX_SIZE;
}
this.content = Arrays.copyOf(this.content, newCapacity);
}
- BitmapContainer添加过程
@Override
public Container add(final short i) {
final int x = Util.toIntUnsigned(i);
final long previous = bitmap[x / 64];
long newval = previous | (1L << x);
bitmap[x / 64] = newval;
if (USE_BRANCHLESS) {
cardinality += (previous ^ newval) >>> x;
} else if (previous != newval) {
++cardinality;
}
return this;
}
代码不是很多,我们分析一下:
要将x添加到BitmapContainer中,就是先找到x在哪个long里,并将该long对应的bit位置为1,其实就是求x/64的商(第几个long)和余(long的第几位)
x/64取整找到long数组的索引,final long previous = bitmap[x / 64]得到了对应long的旧值,1L<<x等效于1L<<(x%64),即把对应位置的bit置为1,再和旧值做位或,得到新值
为什么1L<<x等效于1L<<(x%64)呢?我们看一下官方说明15.19. Shift Operators
If the promoted type of the left-hand operand is int, then only the five lowest-order bits of the right-hand operand are used as the shift distance. It is as if the right-hand operand were subjected to a bitwise logical AND operator & (§15.22.1) with the mask value 0x1f (0b11111). The shift distance actually used is therefore always in the range 0 to 31, inclusive.
If the promoted type of the left-hand operand is long, then only the six lowest-order bits of the right-hand operand are used as the shift distance. It is as if the right-hand operand were subjected to a bitwise logical AND operator & (§15.22.1) with the mask value 0x3f (0b111111). The shift distance actually used is therefore always in the range 0 to 63, inclusive.
如果左操作数是int,那么只会使用右操作数的低5位用于移位,因此实际移位距离永远在0-31之间
如果左操作数是long,那么只会使用右操作数的低6位用于移位,因此实际移位距离永远在0-63之间
所以1L<<x等效于1L<<(x%64)
- RunContainer添加过程
@Override
public Container add(short k) {
// TODO: it might be better and simpler to do return
// toBitmapOrArrayContainer(getCardinality()).add(k)
// but note that some unit tests use this method to build up test runcontainers without calling
// runOptimize
// 同样使用二分查找+顺序查找,唯一区别是每隔2个查询一次,这是为了查询起始值
int index = unsignedInterleavedBinarySearch(valueslength, 0, nbrruns, k);
// 大于等于0说明k就是某个起始值,已经存在,直接返回
if (index >= 0) {
return this;// already there
}
// 小于0说明k不是起始值,需要进一步判断
// 指向前一个起始值(即小于当前值的一个起始值)的索引
index = -index - 2;// points to preceding value, possibly -1
// 前一个起始值的索引大于0说明当前值不是最小值
if (index >= 0) {// possible match
// 计算当前值和前一个起始值的偏移量
int offset = toIntUnsigned(k) - toIntUnsigned(getValue(index));
// 计算前一个起始值的行程长度
int le = toIntUnsigned(getLength(index));
// 若偏移量小于前面的行程长度说明当前值在这个行程范围内,直接返回
if (offset <= le) {
return this;
}
// 若偏移量等于行程长度+1,说明当前值是上一个行程最大值+1
if (offset == le + 1) {
// we may need to fuse
// 说明前一个值并不是最后一个行程,那么有可能需要融合前后两个行程
if (index + 1 < nbrruns) {
// 若下一个行程的起始值等于当前值+1则需要将这两个相邻的行程做融合
if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {
// indeed fusion is needed
// 重置行程长度
setLength(index,
(short) (getValue(index + 1) + getLength(index + 1) - getValue(index)));
// 通过数组拷贝将多余的行程范围删除并将行程数量nbrruns-1
recoverRoomAtIndex(index + 1);
return this;
}
}
// 若不是融合则将上一个行程的长度+1即可
incrementLength(index);
return this;
}
// 若当前值后还有一个行程,则可能需要将当前值和下一个行程融合
if (index + 1 < nbrruns) {
// we may need to fuse
// 若下一个行程起始值等于当前值+1则需要将当前值和下一个行程融合
if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {
// indeed fusion is needed
// 重置起始值以及行程长度
setValue(index + 1, k);
setLength(index + 1, (short) (getLength(index + 1) + 1));
return this;
}
}
}
// 前一个起始值的索引等于-1说明当前值是最小值
if (index == -1) {
// we may need to extend the first run
// 若存在行程且最小值等于当前值+1,则重置起始值以及行程长度
if (0 < nbrruns) {
if (getValue(0) == k + 1) {
incrementLength(0);
decrementValue(0);
return this;
}
}
}
// 其他情况通用处理
makeRoomAtIndex(index + 1);
setValue(index + 1, k);
setLength(index + 1, (short) 0);
return this;
}
RunBitmap的添加过程相比其他两种较为复杂,优先处理了很多特殊情况再做通用处理
②转化
当我们手动调用runOptimize()方法时会触发对Container的优化,根据实际情况将ArrayContainer、BitmapContainer两种容器与RunContainer相互转化
官方论文关于容器转化的说明
Thus, when first creating a Roaring bitmap, it is usually made of array and bitmap containers.
Runs are not compressed. Upon request, the storage of the Roaring bitmap can be optimized using
the runOptimize function. This triggers a scan through the array and bitmap containers that
converts them, if helpful, to run containers. In a given application, this might be done prior to
storing the bitmaps as immutable objects to be queried. Run containers may also arise from calling
a function to add a range of values.
To decide the best container type, we are motivated to minimize storage. In serialized form, a run
container uses 2 + 4r bytes given r runs, a bitmap container always uses 8192 bytes and an array
container uses 2c + 2 bytes, where c is the cardinality. Therefore, we apply the following rules:
- All array containers are such that they use no more space than they would as a bitmap
container: they contain no more than 4096 values.- Bitmap containers use less space than they would as array containers: they contain more than
4096 values.- A run container is only allowed to exist if it is smaller than either the array container or
the bitmap container that could equivalently store the same values. If the run container has
cardinality greater than 4096 values, then it must contain no more than ⌈(8192 − 2)/4⌉ =
2047 runs. If the run container has cardinality no more than 4096, then the number of runs
must be less than half the cardinality.
/**
* Use a run-length encoding where it is more space efficient
*
* @return whether a change was applied
*/
public boolean runOptimize() {
boolean answer = false;
for (int i = 0; i < this.highLowContainer.size(); i++) {
Container c = this.highLowContainer.getContainerAtIndex(i).runOptimize();
if (c instanceof RunContainer) {
answer = true;
}
this.highLowContainer.setContainerAtIndex(i, c);
}
return answer;
}
我们看一下不同Container的转化过程
- ArrayContainer
@Override
public Container runOptimize() {
// TODO: consider borrowing the BitmapContainer idea of early
// abandonment
// with ArrayContainers, when the number of runs in the arrayContainer
// passes some threshold based on the cardinality.
int numRuns = numberOfRuns();
int sizeAsRunContainer = RunContainer.serializedSizeInBytes(numRuns);
if (getArraySizeInBytes() > sizeAsRunContainer) {
return new RunContainer(this, numRuns); // this could be maybe
// faster if initial
// container is a bitmap
} else {
return this;
}
}
计算转化为RunContainer后需要的行程个数
@Override
int numberOfRuns() {
if (cardinality == 0) {
return 0; // should never happen
}
int numRuns = 1;
int oldv = toIntUnsigned(content[0]);
// 循环所有数字,若前后不连续则行程长度+1
for (int i = 1; i < cardinality; i++) {
int newv = toIntUnsigned(content[i]);
if (oldv + 1 != newv) {
++numRuns;
}
oldv = newv;
}
return numRuns;
}
计算作为RunContainer序列化后的字节数
protected static int serializedSizeInBytes(int numberOfRuns) {
return 2 + 2 * 2 * numberOfRuns; // each run requires 2 2-byte entries.
}
计算ArrayContainer大小进行对比
@Override
protected int getArraySizeInBytes() {
return cardinality * 2;
}
构造RunContainer
protected RunContainer(ArrayContainer arr, int nbrRuns) {
this.nbrruns = nbrRuns;
// 长度为行程个数的2倍
valueslength = new short[2 * nbrRuns];
if (nbrRuns == 0) {
return;
}
int prevVal = -2;
int runLen = 0;
int runCount = 0;
// 循环每个元素,判断前后是否连续并设置起始值和行程长度
for (int i = 0; i < arr.cardinality; i++) {
int curVal = toIntUnsigned(arr.content[i]);
if (curVal == prevVal + 1) {
++runLen;
} else {
if (runCount > 0) {
setLength(runCount - 1, (short) runLen);
}
setValue(runCount, (short) curVal);
runLen = 0;
++runCount;
}
prevVal = curVal;
}
setLength(runCount - 1, (short) runLen);
}
- BitmapContainer
@Override
public Container runOptimize() {
int numRuns = numberOfRunsLowerBound(MAXRUNS); // decent choice
int sizeAsRunContainerLowerBound = RunContainer.serializedSizeInBytes(numRuns);
if (sizeAsRunContainerLowerBound >= getArraySizeInBytes()) {
return this;
}
// else numRuns is a relatively tight bound that needs to be exact
// in some cases (or if we need to make the runContainer the right
// size)
numRuns += numberOfRunsAdjustment();
int sizeAsRunContainer = RunContainer.serializedSizeInBytes(numRuns);
if (getArraySizeInBytes() > sizeAsRunContainer) {
return new RunContainer(this, numRuns);
} else {
return this;
}
}
计算runs的下界
// nruns value for which RunContainer.serializedSizeInBytes ==
// BitmapContainer.getArraySizeInBytes()
private final int MAXRUNS = (getArraySizeInBytes() - 2) / 4;
@Override
protected int getArraySizeInBytes() {
return MAX_CAPACITY / 8;
}
/**
* Counts how many runs there is in the bitmap, up to a maximum
*
* @param mustNotExceed maximum of runs beyond which counting is pointless
* @return estimated number of courses
*/
public int numberOfRunsLowerBound(int mustNotExceed) {
int numRuns = 0;
for (int blockOffset = 0; blockOffset + BLOCKSIZE <= bitmap.length; blockOffset += BLOCKSIZE) {
for (int i = blockOffset; i < blockOffset + BLOCKSIZE; i++) {
long word = bitmap[i];
numRuns += Long.bitCount((~word) & (word << 1));
}
if (numRuns > mustNotExceed) {
return numRuns;
}
}
return numRuns;
}
MAXRUNS:我们知道BitmapContainer大小固定为8kb即8192字节,我们就可以列一个等式去计算行程长度的最大数量,若超过这个值RunContainer占用更大空间,没有转化的意义。2 + 2 * 2 * runs=8192,求得临界值为2047
计算下界的过程不是很复杂,我们这里看一个有趣的算法numRuns += Long.bitCount((~word) & (word << 1)),很明显这是计算runs的数量的。我们来理解下原理:一个word里64位每个1代表一个数字,要统计run的数量其实就是统计这个word里有多少组连续的1,再进一步说就是统计有多少个0、1是相邻的,我们将word左移一位,再和word的反值做位与操作,如果有相邻的0和1,则计算后会出现一个1,我们再通过Long.bitCount(long i)方法统计计算结果有多少个1,即求得有多少个runs
这个runs是一个粗略值,若通过这个runs计算出来的RunContainer大小小于BitmapContainer,则进一步计算准确的runs
对run值进行校准
/**
* Computes the number of runs
*
* @return the number of runs
*/
public int numberOfRunsAdjustment() {
int ans = 0;
long nextWord = bitmap[0];
for (int i = 0; i < bitmap.length - 1; i++) {
final long word = nextWord;
nextWord = bitmap[i + 1];
ans += ((word >>> 63) & ~nextWord);
}
final long word = nextWord;
if ((word & 0x8000000000000000L) != 0) {
ans++;
}
return ans;
}
ans += ((word >>> 63) & ~nextWord);:这个算法不难理解,需要调整的情况就是前一个值的第63位和下一个值的第0位不相同,这种情况runs需要加一
构造RunContainer
// convert a bitmap container to a run container somewhat efficiently.
protected RunContainer(BitmapContainer bc, int nbrRuns) {
this.nbrruns = nbrRuns;
valueslength = new short[2 * nbrRuns];
if (nbrRuns == 0) {
return;
}
int longCtr = 0; // index of current long in bitmap
long curWord = bc.bitmap[0]; // its value
int runCount = 0;
while (true) {
// potentially multiword advance to first 1 bit
while (curWord == 0L && longCtr < bc.bitmap.length - 1) {
curWord = bc.bitmap[++longCtr];
}
if (curWord == 0L) {
// wrap up, no more runs
return;
}
int localRunStart = Long.numberOfTrailingZeros(curWord);
int runStart = localRunStart + 64 * longCtr;
// stuff 1s into number's LSBs
long curWordWith1s = curWord | (curWord - 1);
// find the next 0, potentially in a later word
int runEnd = 0;
while (curWordWith1s == -1L && longCtr < bc.bitmap.length - 1) {
curWordWith1s = bc.bitmap[++longCtr];
}
if (curWordWith1s == -1L) {
// a final unterminated run of 1s (32 of them)
runEnd = 64 + longCtr * 64;
setValue(runCount, (short) runStart);
setLength(runCount, (short) (runEnd - runStart - 1));
return;
}
int localRunEnd = Long.numberOfTrailingZeros(~curWordWith1s);
runEnd = localRunEnd + longCtr * 64;
setValue(runCount, (short) runStart);
setLength(runCount, (short) (runEnd - runStart - 1));
runCount++;
// now, zero out everything right of runEnd.
curWord = curWordWith1s & (curWordWith1s + 1);
// We've lathered and rinsed, so repeat...
}
}
- RunContainer
根据大小判断转化为ArrayContainer或BitmapContainer,代码不详述了
4、常用API
RoaringBitmap:
//添加单个数字
public void add(final int x)
//添加范围数字
public void add(final long rangeStart, final long rangeEnd)
//移除数字
public void remove(final int x)
//遍历RBM
public void forEach(IntConsumer ic)
//检测是否包含
public boolean contains(final int x)
//获取基数
public int getCardinality()
//位与,取两个RBM的交集,当前RBM会被修改
public void and(final RoaringBitmap x2)
//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitmap and(final RoaringBitmap x1, final RoaringBitmap x2)
//位或,取两个RBM的并集,当前RBM会被修改
public void or(final RoaringBitmap x2)
//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitmap or(final RoaringBitmap x1, final RoaringBitmap x2)
//异或,取两个RBM的对称差,当前RBM会被修改
public void xor(final RoaringBitmap x2)
//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitmap xor(final RoaringBitmap x1, final RoaringBitmap x2)
//取原始值和x2的差集,当前RBM会被修改
public void andNot(final RoaringBitmap x2)
//同上,但是会返回一个新的RBM,不会修改原始的RBM,线程安全
public static RoaringBitmap andNot(final RoaringBitmap x1, final RoaringBitmap x2)
//序列化
public void serialize(DataOutput out) throws IOException
public void serialize(ByteBuffer buffer)
//反序列化
public void deserialize(DataInput in) throws IOException
public void deserialize(ByteBuffer bbf) throws IOException
FastAggregation: 一些快速聚合操作
public static RoaringBitmap and(Iterator<? extends RoaringBitmap> bitmaps)
public static RoaringBitmap or(Iterator<? extends RoaringBitmap> bitmaps)
public static RoaringBitmap xor(Iterator<? extends RoaringBitmap> bitmaps)
5、序列化
将RBM序列化为字节数组并存入mysql
RoaringBitmap roaringBitmap = new RoaringBitmap();
roaringBitmap.add(1L,100L);
int size = roaringBitmap.serializedSizeInBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(size);
roaringBitmap.serialize(byteBuffer);
return byteBuffer.array();
序列化为字节数组后,存入mysql的blob字段
将mysql中的blob字段反序列化为RBM
private RoaringBitmap deSerializeRoaringBitmap(Blob blob) throws SQLException {
byte[] content = blob.getBytes(1, (int) blob.length());
ByteBuffer byteBuffer = ByteBuffer.wrap(content);
return new RoaringBitmap(new ImmutableRoaringBitmap(byteBuffer));
}
官方给出的结合Kryo5序列化
Many applications use Kryo for serialization/deserialization. One can use Roaring bitmaps with Kryo efficiently thanks to a custom serializer (Kryo 5):
public class RoaringSerializer extends Serializer<RoaringBitmap> {
@Override
public void write(Kryo kryo, Output output, RoaringBitmap bitmap) {
try {
bitmap.serialize(new KryoDataOutput(output));
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException();
}
}
@Override
public RoaringBitmap read(Kryo kryo, Input input, Class<? extends RoaringBitmap> type) {
RoaringBitmap bitmap = new RoaringBitmap();
try {
bitmap.deserialize(new KryoDataInput(input));
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException();
}
return bitmap;
}
}
在项目中,我们采用了FST序列化,发现FSTStreamEncoder与RoaringBitmap的序列化有冲突,这是因为FSTStreamEncoder会对Int、Short、Long等类型做变长存储处理(如,根据Int的大小存储为1-5个字节),而RoaringBitmap的序列化与反序列化依赖于这些类型的序列化的字节数是固定的,所以需要自定义处理
将RoaringBitmap绑定自定义的序列化器进行注册,在自定义的序列化器中我们对FSTObjectOutput以及FSTObjectInput进行代理,重写writeShort、writeInt、writeLong等方法,将其路由为写字节数组
四、一些补充
1、RBM对long的支持:
64-bit integers (long)
Though Roaring Bitmaps were designed with the 32-bit case in mind, we have an extension to 64-bit integers:
import org.roaringbitmap.longlong.*;
LongBitmapDataProvider r = Roaring64NavigableMap.bitmapOf(1,2,100,1000);
r.addLong(1234);
System.out.println(r.contains(1)); // true
System.out.println(r.contains(3)); // false
LongIterator i = r.getLongIterator();
while(i.hasNext()) System.out.println(i.next());
2、0.8.12版本中将所有的unsigned shorts替换为chars
本博客的所有源码基于0.8.11版本,所以还是short


有个哥们提了个issue,他将所有的unsigned short都替换为了char,并且去除了所有toIntUnsigned以及compareUnsigned方法。这个想法得到了作者的认可并且merge进了主分支

关于性能,他用真实数据测试了foreach和or操作,性能上有不小的提升,但也有一些有所回退,根据目前最新版本0.8.14该功能未回退,应该没有太大影响
参考文档
RoaringBitmap github
《Better bitmap performance with Roaring bitmaps》
Consistently faster and smaller compressed bitmaps with Roaring
高效压缩位图RoaringBitmap的原理与应用
精确去重和Roaring BitMap (咆哮位图)














 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









