







1:关系数据库的由来:
IBM的工程师Dr E F codd 的关系型数据库模型发表于1970 论文名称: A relational Model of data for Large Shared Data Bank (这个在wiki 和google上可以搜到)
SQL: Structured query language: oracle官方SQL文档
2:如何给一个用户解锁:
当我们安装oralce的数据库的时候,会默认安装一个SAMPLE的例子:
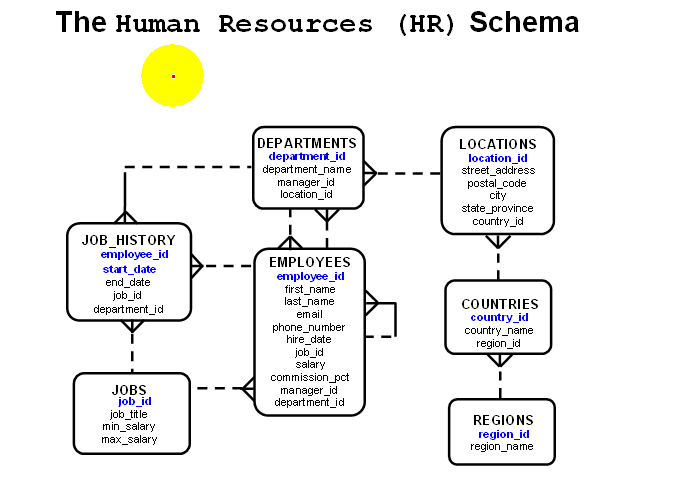
关于oracle的书中讲解中,大多会采用这个例子经典的只有七张表:这七张表可以作为学习关系型数据库的基础
但是这个用户默认是关闭的。这个用户的用户名为HR
如果想看这些表,需要对HR用户进行解锁:
解锁步骤:
1: alter user HR account unlock ; 对改用户进行解锁 (在sqlpllus中登录sysdba执行)
2:select username ,account_status from dba_users; 查询有多少用户
3: alter user HR identified by HR; 修改密码; 修改密码后才变成 open状态
4:登录 conn HR/HR
5: show user; 用于显示当前登录的用户
SQL> show user;
USER 为 "HR"以下是这七张表:
3:关于null:
关于null :
null is a value that is unavailable,unassigned, unknown,
or inapplicable.
null is not the same as zero or a blank space.
null和其他值进行数学运算的时候,
如果在算术表达式中,有一个值包含null 这个值就是null。
null 和字符串进行合并的时候 为其他字符串本身。
4:别名
别名的命名:
可以用AS或者空格 ex: select last_name as name, solary solary_month from employees;
select last_name||first_name AS "Employees" from employees;
增加可读性 加空格:
select last_name||' '||first_name AS "Employees" from employees;
IN(set) 判断某个值是否在某个集合里面。
也可以用or来写。
Like 用%匹配 0个或者多个字符串
_ 匹配一个字符。
如果想匹配_ 需要用转义字符 like '%S\_%' escape '\'
后面是指定 转义字符为escape '\' \
关于查询出来的行数据含有null值时候,在数据显示的时候null放前还是放后的问题;
select last_name ,department_id,salary from employees order by department_id ,salary desc
以上例子意思是,首先按照department_id 升序排列, 然后当 department_id相同即部门相同 的时候
,再按照 salary 降序排列。 关于null放前还是放后的问题,
有命令 null first 或 null last 等:
5:substitution variables(使用变量):
几乎所有地方都可以使用。
SQL> select last_name ,department_id,salary from employees where employee_id=&e
mploy_null ;替换变量是客户端软件的功能,不是数据库服务器的功能,在发回到数据库服务器的时候,
就不存在替换变量了。
select employee_id ,last_name,job_id, &&column_name from employees
order by &column_name如果一个&变量 每次都要输入值,如果用两个&&表示后面还有需要输入这个值。
&&需要的参数。
也可以用define
define employee_num = 200
define命令 能够显示定义的变量》
定义后 &后的变量就可以不用数据输入了。
消除定义为 undefine employee_num
6:oracle常用函数
function::=

2:mutiple-row funciton :就是多行函数,对多行进行操作,聚合函数
--------------------------------------------------------------------------------------------------------------------------------------------------
大小写函数 LOWER('STR')
UPPER('STR')
INITCAP('STR')
LPAD() pad是填充的意思。为了使输出格式化对齐
SELECT LPAD('Page 1',15,'*.') "LPAD example"
FROM DUAL;
LPAD example
---------------
*.*.*.*.*Page 1TRUNC(88.947) 88.94 直接截取掉
MOD(1500,200) 100 求余
>>>>> 隐式转换
char varchar2 ----> date
ex:select last_name , hire_date from employees where hire_date >'09-july-90';
char varchar2 ----> number
ex:select '99.00' + 22.23 from dual
char 必须是 0--9的字符
select TO_NUMBER('-$123,456.78','$999,999.99') from dual; (前后的转换的格式必须保持一致,不然容易出错)
where last_name='Higgins';
----------- -----
205 06/94
where last_name='Higgins'; fm作用是把前面的0去掉;
EMPLOYEE_ID MONTH
----------- -----
205 6/94
??? SELECT TO_DATE('July 07 , 2008','Month DD ,YYYY') from dual
select TO_CHAR(salary,'$99,999.00') salary from employees where last_name='Ernst';
Nesting function:
优先计算内部的函数,然后再计算外面的。
-----------------------------------------------------------------------------------------------------------------------------------------------------------
NVL
lets you replace null (returned as a blank) with a string in the results of a query. If
expr1
is null, then
NVL
returns
expr2
. If
expr1
is not null, then
NVL
returns
expr1
.
NVL2 lets you determine the value returned by a query based on whether a specified expression is null or not null. If expr1 is not null, then NVL2 returns expr2. Ifexpr1 is null, then NVL2 returns expr3.
if exp1 != null exp2
NULLIF compares expr1 and expr2. If they are equal, then the function returns null. If they are not equal, then the function returns expr1. You cannot specify the literal NULL for expr1.
The NULLIF function is logically equivalent to the following CASE expression:
CASE WHEN expr1 = expr2 THEN NULL ELSE expr1 END
COALESCE
returns the first non-null
expr
in the expression list. You must specify at least two expressions. If all occurrences of
expr
evaluate to null, then the function returns null.
You can also use COALESCE as a variety of the CASE expression. For example,
COALESCE(expr1, expr2)
is equivalent to:
CASE WHEN expr1 IS NOT NULL THEN expr1 ELSE expr2 END
Similarly,
COALESCE(expr1, expr2, ..., exprn)
where n >= 3, is equivalent to:
CASE WHEN expr1 IS NOT NULL THEN expr1
ELSE COALESCE (expr2, ..., exprn) END case是sql国际标准 为了兼容性 可以用case
这个非常有用:
CASE expr when comparison_expr1 then return_expt1
[when comparison_expr2 then return_expt2
when comparison_exprn then return_exptn
else else_expt]
END
意思就是 当expr = expr1 时 返回 expt1 ,当 expr = expr2时,返回 expt2 , 当expr=exprn时,返回 exptn ,如果以上都不匹配 返回 else_expt
decode是oracle特有的:

DECODE compares expr to each search value one by one. If expr is equal to a search, then Oracle Database returns the corresponding result. If no match is found, then Oracle returns default. If default is omitted, then Oracle returns null.
7:使用聚合函数
1: count(*) 和 count(1)用法一致。 count(1)的执行速度比count(*)稍微快一点。
count(column_name|exp) 在满足列或者表达式的非空行的数据的个数。
count(distinct expr) 不相同的非空行的个数。:
2:AVG用法:
select AVG(comission_pct) from
select AVG(NVL(comission_pct,0)) from employees n --排除非空行;
3:Group 字句:
group by 和 where放在一起,先执行where 再执行 group by,
select 中的列 在 group by 中 必须要有,在查询的时候一定要保持查出来的数据想对应,不然容易出错。好好回味 多个分组的意义
group by 后的列 如果有多个,这些列查出来的一行是中 group by后的列名组合起来是唯一的,一定是唯一的,所以如果select后的非聚合函数列
如果不和group by 保持一致,得出的数据不一定是唯一的,所以会造成数据的出错。
为了方便不出错,group by 后面的和 select后面的保持一致。
select department_id,job_id, sum(salary) from employees group by department_id ,job_id order by department_id;
DEPARTMENT_ID JOB_ID SUM(SALARY)
------------- ---------- -----------
10 AD_ASST 4400
20 MK_MAN 13000
20 MK_REP 6000
30 PU_CLERK 13900
30 PU_MAN 11000
40 HR_REP 6500
50 SH_CLERK 64300
50 ST_CLERK 55700
50 ST_MAN 36400
60 IT_PROG 28800
70 PR_REP 10000
DEPARTMENT_ID JOB_ID SUM(SALARY)
------------- ---------- -----------
80 SA_MAN 61000
80 SA_REP 243500
90 AD_PRES 24000
90 AD_VP 34000
100 FI_ACCOUNT 39600
100 FI_MGR 12000
110 AC_ACCOUNT 8300
110 AC_MGR 12000
SA_REP 7000
已选择20行。
100 FI_ACCOUNT 39600
100 FI_MGR 12000如果 只按照department_id分组, 这两个数据一定是和在一起的,为: 100 51600 求和 也是求着两个的和,如果再按照 job_id分组,相当于 在部门为100的部门中,job_id不同的有哪些,就是100部门的人都做那些不同的工作, 这样就要在 部门号为100的部门中 按照 job_id分组,就显示了以上的分组结果:
因为 select 后面的的聚合函数执行在 group by 语句后面,即 在分组后再进行聚合函数计算,所以sum(salary) 聚合函数计算的是group by后的结果,
即 部门号为100 做 FI_ACCOUNT工作的人的工资总数为 39600;
group by后面的列数越多,分组越细,不管怎么分,聚合函数一定在分组后计算,having一定在聚合函数后计算,order by一定在 having后排序。这个执行顺序是不变的。
注意: group by后面的顺序不同,表示的意义也相同,不过由于都是表示唯一的分组情况,所以 颠倒顺序行数还是一样的。
如把 job_id 和 department_id的顺序颠倒一下,其实还是一样的,都是这么多唯一的数据。
SQL> select job_id, department_id, sum(salary) from employees group by job_i
d , department_id order by department_id;
JOB_ID DEPARTMENT_ID SUM(SALARY)
---------- ------------- -----------
AD_ASST 10 4400
MK_MAN 20 13000
MK_REP 20 6000
PU_CLERK 30 13900
PU_MAN 30 11000
HR_REP 40 6500
SH_CLERK 50 64300
ST_CLERK 50 55700
ST_MAN 50 36400
IT_PROG 60 28800
PR_REP 70 10000
JOB_ID DEPARTMENT_ID SUM(SALARY)
---------- ------------- -----------
SA_MAN 80 61000
SA_REP 80 243500
AD_PRES 90 24000
AD_VP 90 34000
FI_ACCOUNT 100 39600
FI_MGR 100 12000
AC_ACCOUNT 110 8300
AC_MGR 110 12000
SA_REP 7000
已选择20行。
select column,group_function from table
[where condition]
[group by group_by_expression]
[having group_function]
order by column
执行顺序,先执行where之句,再执行 group by子句,再执行 select 后的group_function
再执行 having 顺序,,最后再执行order by 这是这个语句的执行顺序。
where语句是不能包括 group_function的 因为 先执行where。















 1731
1731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









