







内容 来自《算法导论》《Introduction to algorithms》 作者CLRS
编辑by Touzani
http://blog.csdn.net/touzani/archive/2007/05/29/1628885.aspx
字符串匹配(String matching)
问题的形式定义: 假设文本(Text)是一个长度为n的数组T[1…n], 模式(Pattern)是一个长度为
m ≤
n.的数组P[1..m];. 又假设P和T中的元素都属于有限字母表 Σ 中的字符。 P 和T 常称为字符串。
如果0 ≤ s ≤ n – m 且T[s+1..s+m]=P[1…m], 则说P在T中出现且位移为s,此时成s为一个有效位移。
字符串匹配问题就变成在一个在一段制定的文本T中找出模式P的所有有效位移的问题。
下图给出了将要介绍的字符串匹配算法以及它们的预处理时间和匹配时间。
|
算法
|
预处理时间
|
匹配时间
|
|
|
||
|
朴素算法
|
0
|
O
((n - m + 1)m)
|
|
Rabin-Karp
|
Θ(m)
|
O
((n - m + 1)m)
|
|
有限自动机算法
|
O
(m |Σ|)
|
Θ(n)
|
|
KMP
算法
|
Θ(m)
|
Θ(n)
|
记号:
用Σ* 表示用字母表 Σ中的所有有限长度的字符串的集合
字符串x的长度用| x |表示。
wy表示两个字符串w和y的连接。| wy | = | x |+| y |
字符串前缀 后缀
如果某个字符串 y ∈ Σ*,使得x=wy 。则称w是x的前缀, 记为w � x 。 如果w是x的后缀,记为w � x
可以把字符串匹配问题描述为 找出0 ≤ s ≤ n-m 并满足P � Ts+m的所有位移s
1.)朴素的字符串匹配算法
NAIVE-STRING-MATCHER(T, P)
1 n ← length[T]
2 m ← length[P]
3 for s ← 0 to n - m
4 do if P[1 ‥ m] = T[s + 1 ‥ s + m] // 隐含着一个循环
5 then print "Pattern occurs with shift" s
4 do if P[1 ‥ m] = T[s + 1 ‥ s + m] // 隐含着一个循环
5 then print "Pattern occurs with shift" s
时间复杂度为
O((
n -
m + 1)
m), 如果
m =
�
n/2
�. 那么时间复杂度为 Θ(
n
2), 这个算法效率不高,原因在于对于s的一个值,获得的关于文本的信息在考虑s的其他值时完全被忽略了。
例如,如果 P=aaab,设s=0 是有效的,那么 s=1, 2, 3 就不可能是有效位移,因为T[4]=b.
2.) Rabin-Karp字符串匹配算法,
实际应用中,Rabin和Karp建议的字符串匹配算法能较好地运行,还可以归纳出有关问题地其他算法,如二维模式匹配。
假定字符集Σ ={0, 1, 2, ……, 9}, 每一个字符对应一个十进制数字
(一般情况, 假定每个字符是基数为d的表示法中的一个数字, d=|Σ|。)可以用一个长度为k的十进制数字来表示由k个连续字符组成的字符串.
因此,字符串"31415" 对应于十进制数31415
已知模式P[1..m],设p表示其相应十进制数地值,类似地, 对于给定的文本T[1..n]. 用
ts 表示长度为m的子字符串
T[
s + 1 ‥
s +
m](
s = 0, 1, . . . ,
n –
m),
ts =
p 当且仅当 [
s + 1 ‥
s +
m] =
P[1 ‥
m]; 因此s是有效位移当且仅当
ts =
p. (暂不考虑p和
ts 可能是很大的数的情况)。
可以用霍纳规则(Horner’s rule) 在Θ(m) 的时间内计算p的值
p = P[m] + 10 (P[m - 1] + 10(P[m - 2] + · · · + 10(P[2] + 10P[1]) )).
Horner’s rule
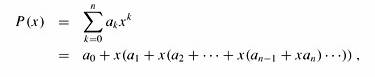
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









