







1.2.3 加权快速合并算法
快速合并算法仍然有他的局限性,因为查找根节点的次数并不是固定的,如果出现极端情况那么任然会出现计算较多的次数。假定输入对按照1-2, 2-3, 3-4, 4-5......的次序出现,然么N-1个数对形成的树为一条直线。其中N指向N-1,N-1指向N-2以此类推。要查找N最下面的节点,则需要N-1次遍历。那么查找M个对象的查找操作次数必定大于MN/2。
优化:使用另一组数组保存节点的计数,则会使效率获得巨大提升,称之为加权快速合并算法。
#include <stdio.h>
#define N (10)
int main()
{
int i, p, q, j;
int id[N];
int sz[N];//表示前N的对象,所保存的节点
//初始化对象集合中元素的初始值
for (i = 0; i < N; i++)
{
id[i] = i;
sz[i] = 1;
}
//循环读入整数对
while (scanf("%d-%d", &p, &q) == 2)
{
//读取p根节点
for (i = p; i != id[i]; i = id[i])
{
}
for (j = q; j != id[j]; j = id[j]);
if (i == j)
{
//p和q的根节点相同
continue;
}
if (sz[i] < sz[j])
{
id[i] = j;
sz[j] += sz[i];
}
else
{
id[j] = i;
sz[i] += sz[j];
}
//因为p-q是新对,所以输出这个对
printf("New pair: %d-%d\n", p, q);
}
return 0;
}加权合并中的sz[N]保存的连接节点的数量,通过使用这个新的数据结构完成原先的算法的优化。
1.2.4 压缩路径加权合并法 —— 等分路径压缩
#include <stdio.h>
#define N (10)
int main()
{
int i, p, q, j;
int id[N];
int sz[N];//表示前N的对象,所保存的节点
//初始化对象集合中元素的初始值
for (i = 0; i < N; i++)
{
id[i] = i;
sz[i] = 1;
}
//循环读入整数对
while (scanf("%d-%d", &p, &q) == 2)
{
//读取p根节点
for (i = p; i != id[i]; i = id[i])
{
id[i] = id[id[i]];
}
for (j = q; j != id[j]; j = id[j])
{
id[j] = id[id[j]];
}
if (i == j)
{
//p和q的根节点相同
continue;
}
if (sz[i] < sz[j])
{
id[i] = j;
sz[j] += sz[i];
}
else
{
id[j] = i;
sz[i] += sz[j];
}
//因为p-q是新对,所以输出这个对
printf("New pair: %d-%d\n", p, q);
}
return 0;
}再次优化,使得每棵树都是尽量扁平的。
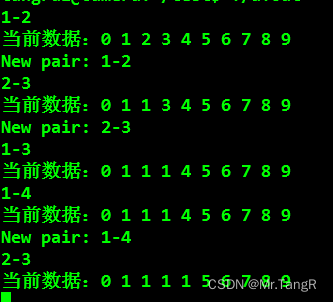
看似是和快速查找法类似的数据变化过程,但是由于是找根节点的方式判断是否有链接,所以效率变高。
通俗理解:就是利用查找根节点这一相对简单的判断方式,但是通过扁平化的树分支来代替原先的较长的分支。提高执行效率。















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









