







HashMap源码解析_jdk1.8(一)
哈希
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
常用数据结构查找/插入/删除性能比较。
-
数组
采用一段连续的存储单元来存储数据。
查找:时间复杂度
O(1)插入删除:时间复杂度
O(n),插入删除操作,涉及到数组元素的移动。 -
线性链表
查找:时间复杂度
O(n),需要遍历链表。插入删除:时间复杂度
O(1),仅需处理链表指针的指向。 -
二叉树
对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为
O(logn)。 -
哈希表
在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为
O(1)。哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
映射函数:
存储位置 = f(关键字)其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
哈希是通过对数据进行再压缩,提高效率的一种解决方法。但由于通过哈希函数产生的哈希值是有限的,而数据可能比较多,导致经过哈希函数处理后仍然有不同的数据对应相同的值。这时候就产生了哈希冲突(哈希碰撞)。
解决哈希冲突的方法:
-
开放地址方法
1). 线性探测:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
2). 再平方探测: 冲突发生时,在表的左右进行跳跃式探测,在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
3). 伪随机探测: 冲突发生时,通过随机函数随机生成一个数,直至不发生哈希冲突。
-
链式地址法(HashMap的哈希冲突解决方法)
将所有哈希地址为i的元素构成一个单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在链表中进行。
-
再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
-
建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
HashMap的数据结构
HashMap的底层主要是基于数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
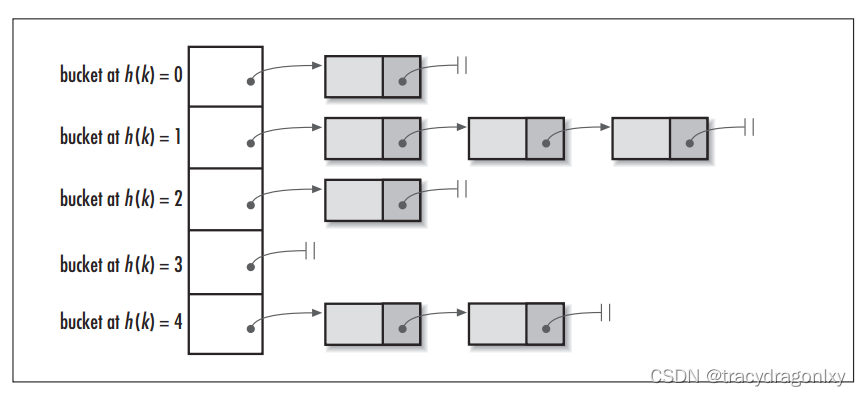
从上图看到,左边是个数组,数组的每个成员是一个链表。该数据结构所容纳的所有元素均包含一个指针,用于元素间的链接。
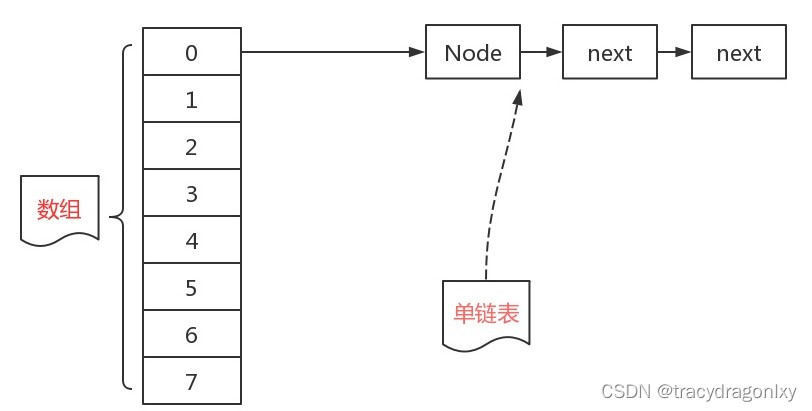
JDK1.7中HashMap的数据结构:数组+链表
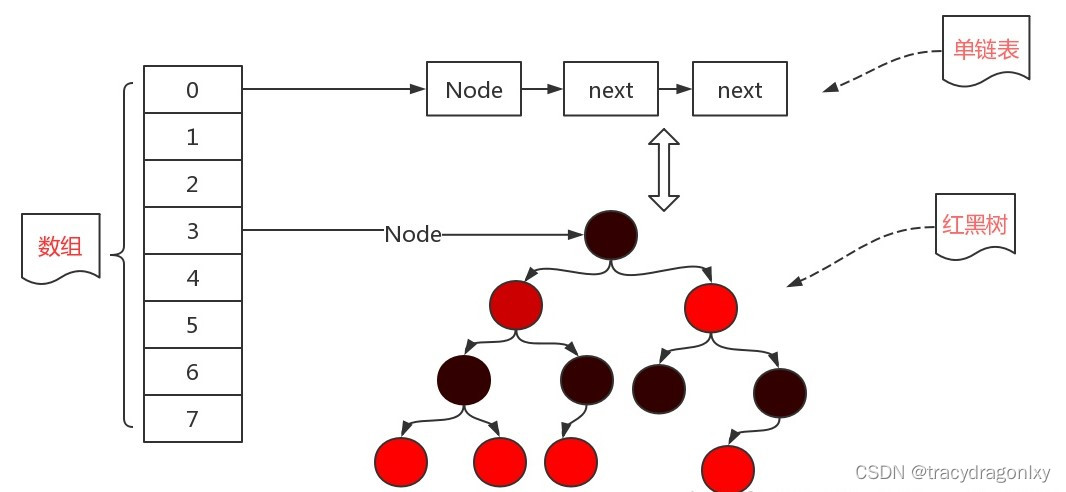
JDK1.8中HashMap的数据结构:数组+链表+红黑树,只有在链表的长度不小于8,而且数组的长度不小于64的时候才会将链表转化为红黑树。
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。Entry是HashMap中的一个静态内部类。代码如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
HashMap相关变量
HashMap类中有以下主要成员变量:
/**
* 默认初始容量 - 必须是2的幕数.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* node数组最大容量:2^30=1073741824.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认的负载因子,用来衡量HashMap满的程度。
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 将链表转换为树的阈值。当链表长度超过8时,链表就转换为红黑树。
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 树转链表阀值,小于等于6(tranfer时,lc、hc=0两个计数器分别++记录原bin、新binTreeNode数量,<=UNTREEIFY_THRESHOLD 则untreeify(lo))
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/* ---------------- Fields -------------- */
/**
* 存放node的数组,分配长度后,长度始终为2的幂
*/
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* 记录了Map中Key-Value对的个数
*/
transient int size;
/**
* 记录当前集合被修改(添加,删除)的次数
*
* 当我们使用迭代器或foreach遍历时,如果你在foreach遍历时,自动调用迭代器的迭代方法,
* 此时在遍历过程中调用了集合的add,remove方法时,modCount就会改变,
* 而迭代器记录的modCount是开始迭代之前的,如果两个不一致,就会报异常,
* 说明有两个线路(线程)同时操作集合。这种操作有风险,为了保证结果的正确性,
* 避免这样的情况发生,一旦发现modCount与expectedModCount不一致,立即保错。
*
* This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* 下一个要调整大小的大小值,当实际KV个数超过threshold时,HashMap会将容量扩容,threshold=capacity * load factor.
*/
int threshold;
/**
* The load factor for the hash table.
*/
final float loadFactor;
size和capacity
HashMap就像一个“桶”,那么capacity就是这个桶“当前”最多可以装多少元素,而size表示这个桶已经装了多少元素。
HashMap<Integer, Integer> map = new HashMap<>();
map.put(1, 1);
try {
Class<?> mapClass = map.getClass();
Method capacity = mapClass.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity: " + capacity.invoke(map));
Field size = mapClass.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size: " + size.get(map));
} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException | NoSuchFieldException e) {
e.printStackTrace();
}
}
capacity: 16
size: 1
我们定义了一个新的HashMap,向其中put了一个元素,然后通过反射的方式打印capacity和size。输出结果为:capacity : 16、size : 1
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(1->1、7->8、9->16)
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
public static void main(String[] args) {
HashMap<Integer, Integer> map1 = new HashMap<>(1);
HashMap<Integer, Integer> map2 = new HashMap<>(7);
HashMap<Integer, Integer> map3 = new HashMap<>(9);
demoCapacity(map1);
demoCapacity(map2);
demoCapacity(map3);
}
private static void demoCapacity(HashMap<Integer, Integer> map) {
try {
Class<?> mapClass = map.getClass();
Method capacity = mapClass.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity: " + capacity.invoke(map));
} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
}
capacity: 1
capacity: 8
capacity: 16
参考:
https://zhuanlan.zhihu.com/p/79219960
https://www.cnblogs.com/theRhyme/p/9404082.html#_lab2_1_1















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









