







写在最前:本文将简单介绍一下Mdict词典文件的解析,只是我一点浅显的理解,如有不对,请各位大佬多多指正,侵删
前言
Mdict是一种较为广泛使用的电子词典,主要包含mdx和mdd两种格式,mdx中记录的是单词和单词释义,内容以html格式存放,mdd中存放的则是与之配套的资源文件,图片、音频等等,mdx和mdd两种文件内部的结构基本相同,只存在细微的差别(下文会详细介绍),本文只针对2.0版本的词典文件解析。
参考项目
https://github.com/Tuo-ZHANG/mdict-jni-query-library
https://github.com/csarron/mdict-analysis
一、mdx词典解析
mdx文件的内部结构如下:
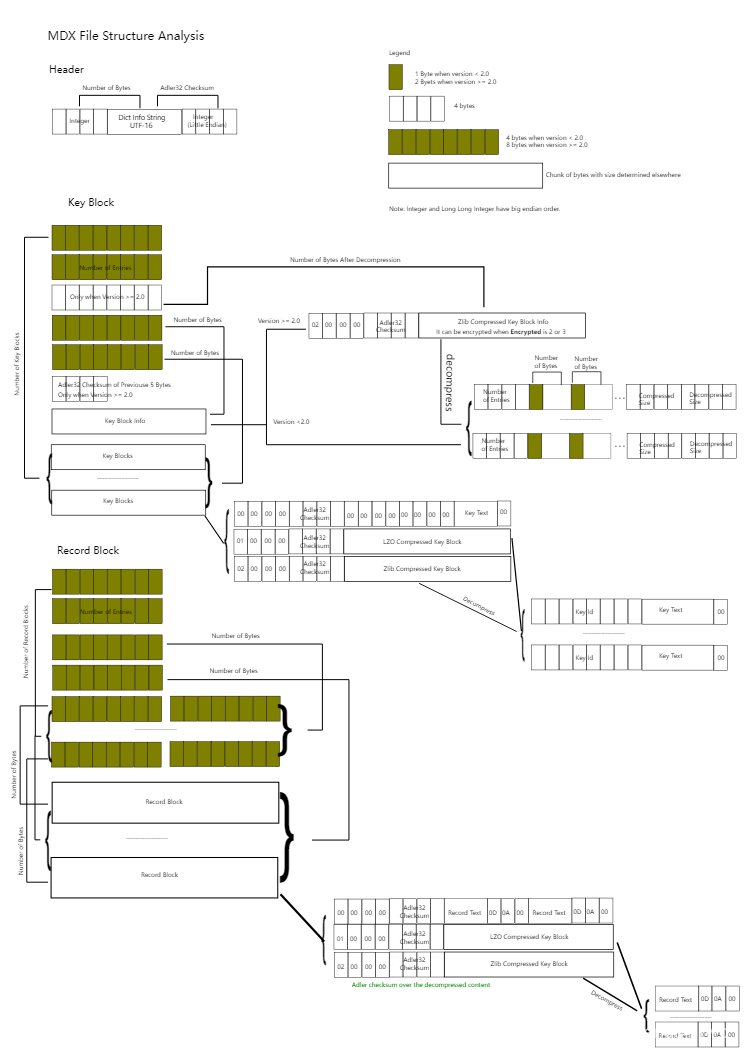
词典解析
解析关键逻辑为
bool Mdict::init() {
/* indexing... */
bool bRet = this->read_header();
if(bRet)
{
this->printhead();
this->read_key_block_header();
this->read_key_block_info();
this->read_record_block_header();
// this->decode_record_block();
// TODO delete this this->decode_record_block(); // very slow!!!
}
return bRet;
}
read_header,读取header信息,文件起始,前四个字节存放了词典的info信息的长度,根据info长度按字节读取info信息,可以得到类似这种格式的内容
"<Dictionary GeneratedByEngineVersion=\"2.0\" RequiredEngineVersion=\"2.0\" Format=\"Html\" KeyCaseSensitive=\"No\" StripKey=\"Yes\" Encrypted=\"2\" RegisterBy=\"EMail\" Description=\"<font size=5 color=red>1122͋test</font>\" Title=\"1122͋\"xQ\"xQ\"Q\"\" Encoding=\"UTF-8\" CreationDate=\"2022-9-22\" Compact=\"No\" Compat=\"No\" Left2Right=\"Yes\" DataSourceFormat=\"107\" StyleSheet=\"\"/>\r\n"
然后再读取各字段值,为后续解析做准备,GeneratedByEngineVersion即为词典的版本值,暂时只考虑2.0版本的词典解析
read_key_block_header,读取mdx的Entries数量,keyblock info信息,keyblock数量
read_key_block_info,主要实现keyblock info和keyblock数据的解码
read_record_block_header,读取record header信息record block信息
单词搜索
单词搜索关键代码
std::string Mdict::lookup(const std::string word) {
try {
// search word in key block info list
long idx = this->reduce0(_s(word), 0, this->key_block_info_list.size());
// std::cout << "==> lookup idx " << idx << std::endl;
if (idx >= 0) {
// decode key block by block id
std::vector<key_list_item*> tlist =
this->decode_key_block_by_block_id(idx);
// reduce word id from key list item vector to get the word index of key
// list
// long word_id = reduce1(tlist, word);
key_list_item * pItem = nullptr;
pItem = key_item_map[word];
if (/*word_id >= 0*/pItem != nullptr) {
// reduce search the record block index by word record start offset
unsigned long record_block_idx = reduce2(pItem->record_start);
// decode recode by record index
auto vec = decode_record_block_by_rid(record_block_idx);
// for(auto it= vec.begin(); it != vec.end(); ++it){
// std::cout<<"word: "<<(*it).first<<" \n def:
// "<<(*it).second<<std::endl;
// }
// reduce the definition by word
std::string def = reduce3(vec, word);
if(m_bIsMddFile)
{
//若当前解析的是mdd格式的词典文件,则将查询的资源文件的内容写入本地文件
bool bRet = createResourceFile(word, def);
if(!bRet)
std::cout << "create local resource file failed, the filen name is : " << word << std::endl;
}
//释放内存
for(auto tItem : key_item_map)
{
delete tItem.second;
tItem.second = nullptr;
}
key_item_map.clear();
return def;
}
}
} catch (std::exception& e) {
std::cout << "==> lookup error" << e.what() << std::endl;
}
return std::string();
}
大体逻辑是在词典初始化时得到的缓存列表key_block_info_list中搜索单词,判断单词对应的key block索引idx,然后对该key block解码,然后再用解码得到的key_list_item列表用二分法查找是否存在这个单词(但是这种查找方式要求词典中单词的存放顺序是有序的,按字母排列的,所以我这里改成了key_item_map键值对的方式),最后再藉由找到的item的record_block_idx索引,进一步的解码,找到对应的单词释义并返回,至此单词查询完成。
二、mdd词典解析
mdd文件的内部结构如下:

可以看到结构和mdx基本一致,解析流程也可以基本代码复用,但需要注意的是,mdx的编码一般是utf-8,解析也是以此字段值解析,而mdd则是须以utf-16解析,或可以特殊处理一下。
bool Mdict::read_header() {
...
// ---------- encoding ------------
if (headinfo.find("Encoding") != headinfo.end() ||
headinfo["Encoding"] == "" || headinfo["Encoding"] == "UTF-8") {
this->encoding = ENCODING_UTF8;
} else if (headinfo["Encoding"] == "GBK" ||
headinfo["Encoding"] == "GB2312") {
this->encoding = ENCODING_GB18030;
} else if (headinfo["Encoding"] == "Big5" || headinfo["Encoding"] == "BIG5") {
this->encoding = ENCODING_BIG5;
} else if (headinfo["Encoding"] == "utf16" ||
headinfo["Encoding"] == "utf-16") {
this->encoding = ENCODING_UTF16;
} else {
this->encoding = ENCODING_UTF8;
}
if(m_bIsMddFile)
{
//mdd词典文件需用UTF16编码解析
this->encoding = ENCODING_UTF16;
}
...
其他
缓存key_list时,split_key_block函数也许特殊处理一下
if (this->encoding == 1 /* ENCODING_UTF16 */) {
// TODO
// throw std::runtime_error("NOT SUPPORT UTF16 YET");
if(bHandleMdd && m_bIsMddFile)
{
key_text = le_bin_utf16_to_utf8(
(const char*)key_block, (key_start_idx + this->number_width),
static_cast<unsigned long>(key_end_idx - key_start_idx -
this->number_width));
}
else
key_text = be_bin_to_utf8(
(const char*)key_block, (key_start_idx + this->number_width),
static_cast<unsigned long>(key_end_idx - key_start_idx -
this->number_width));
} else if (this->encoding == 0 /* ENCODING_UTF8 */) {
key_text = be_bin_to_utf8(
(const char*)key_block, (key_start_idx + this->number_width),
static_cast<unsigned long>(key_end_idx - key_start_idx -
this->number_width));
}
key_text 单词文本的转码使用le_bin_utf16_to_utf8方法代替
std::string le_bin_utf16_to_utf8(const char* bytes, int offset, int len) {
std::u16string u16;
{
std::string strByte;
for(int i = 0; i < len * sizeof(char); i++)
{
const char * tChar = bytes + offset * sizeof(char) + i;
strByte.append(tChar);
}
u16 = u"";
char16_t c16str[3] = u"\0";
mbstate_t mbs;
for (const auto& it: strByte){
memset (&mbs, 0, sizeof (mbs));//set shift state to the initial state
memmove(c16str, u"\0\0\0", 3);
mbrtoc16 (c16str, &it, 3, &mbs);
u16.append(std::u16string(c16str));
}//for
}
// std::string u8 = conv16.to_bytes(u16);
std::string u8 = std::wstring_convert<std::codecvt_utf8_utf16<char16_t>, char16_t>{}.to_bytes(u16);
// if (len > 0) std::free(cbytes);
return u8;
}
与mdx的单词查询不同,mdd的key_text不是单词,而是资源文件名,即,mdd的查询须以资源文件名称搜索,如上文的单词搜索代码所示,对mdd文件特殊处理,最后查询到的def不再是单词释义,而是资源文件的内容
std::string def = reduce3(vec, word);
if(m_bIsMddFile)
{
//若当前解析的是mdd格式的词典文件,则将查询的资源文件的内容写入本地文件
bool bRet = createResourceFile(word, def);
if(!bRet)
std::cout << "create local resource file failed, the filen name is : " << word << std::endl;
}
createResourceFile可自行实现
题外话
若有mdx、mdd词典加解密需求,或可考虑用AES的CFB模式(加密前后字段长度不变)加密词典的前四个字节然后覆写这四个字节的方式实现,因为前四个字节存放的是header info的长度信息,如果这个值获取不正确,后续解析应该无法继续执行了,需解密的时候再解密前四个字节(但不覆写回去)读取到正确的值即可。
void Mdict::encryptMdict()
{
char* head_size_buf = (char*)std::calloc(4, sizeof(char));
readfile(0, 4, head_size_buf);
// 加密词典文件的前四个字节,以达到文件加密的效果
// 采用AES的CFB模式加密,以保证加密前后字段长度不变化
unsigned char tmpChar[DECRYPTBYTELEN] = {0};
for(int i = 0; i < DECRYPTBYTELEN; i++)
{
unsigned char tCh = *(head_size_buf + i);
tmpChar[i] = tCh;
}
AESModeOfOperation moo;
unsigned char iv[] = { 103,35,148,239,76,213,47,119,255,222,123,176,106,134,98,92 };
unsigned char key[] = { 143,194,34,218,145,208,230,143,124,245,96,206,145,92,255,85 };
unsigned char encryptOutput[DECRYPTBYTELEN] = { 0 };
moo.set_key(key);
moo.set_mode(MODE_CFB);
moo.set_iv(iv);
moo.Encrypt(tmpChar, DECRYPTBYTELEN, encryptOutput);
//加密完的字段覆写到词典文件中
std::fstream writeFile(filename, std::ios::in | std::ios::out);
writeFile << encryptOutput;
writeFile.close();
std::free(head_size_buf);
}

















 4723
4723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









