






 本文详细描述了如何在Windows上下载Spark安装包,将其上传至虚拟机,配置环境变量如JAVA_HOME和HADOOP_HOME,设置Spark配置文件(如spark-env.sh,workers,spark-defaults.conf),以及启动Hadoop集群和Spark服务的过程。
本文详细描述了如何在Windows上下载Spark安装包,将其上传至虚拟机,配置环境变量如JAVA_HOME和HADOOP_HOME,设置Spark配置文件(如spark-env.sh,workers,spark-defaults.conf),以及启动Hadoop集群和Spark服务的过程。
在Spark官网选择对应版本的Spark安装包并下载至Windows本地路径
Apache Spark™ - Unified Engine for large-scale data analytics
将Spark安装包上传至虚拟机的/opt目录下
我运用的工具为Xtp 7

将Spark安装包解压至/usr/local目录下

切换至Spark安装目录的/conf下
配置spark-env.sh文件:复制spark-env.sh.template文件并重命名为spark-env.sh,打开spark-env.sh,并添加代码

export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64/jre
export HADOOP_HOME=/usr/local/hadoop3
//写自己的JAVA_HOME HADOOP_HOME
export SPARK_MASTER_IP=master
export SPARK_LOCAL_IP=master
export HADOOP_CONF_DIR=$HADOOP_HOME
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_EXECUTOR_CORES=1
export SPARK_WORKER_INSTANCES=1
配置workers文件:复制workers.template文件并重命名为workers,删除原有代码,添加以下代码
slave1
slave2 //克隆的两个虚拟机名称
配置spark-defaults.conf文件:复制spark-defaults.conf.template文件并重命名为spark-defaults.conf,打开并加上以下代码
spark.master spark://Master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Master:9000/spark-logs
spark.history.fs.logDirectory hdfs://Master:8020/sparl-logs
在主节点(master节点)中,将配置好的Spark安装目录复制到子节点的/usr/local目录下

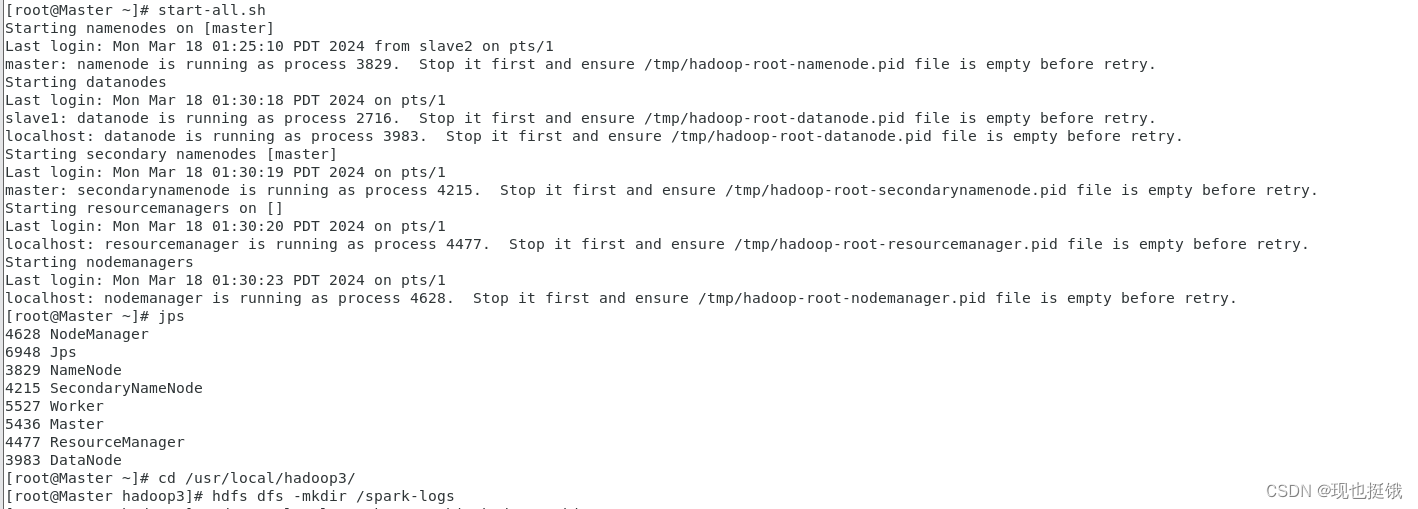
启动hadoop集群,并创建/spark-logs目录,通过命令jps查看进程
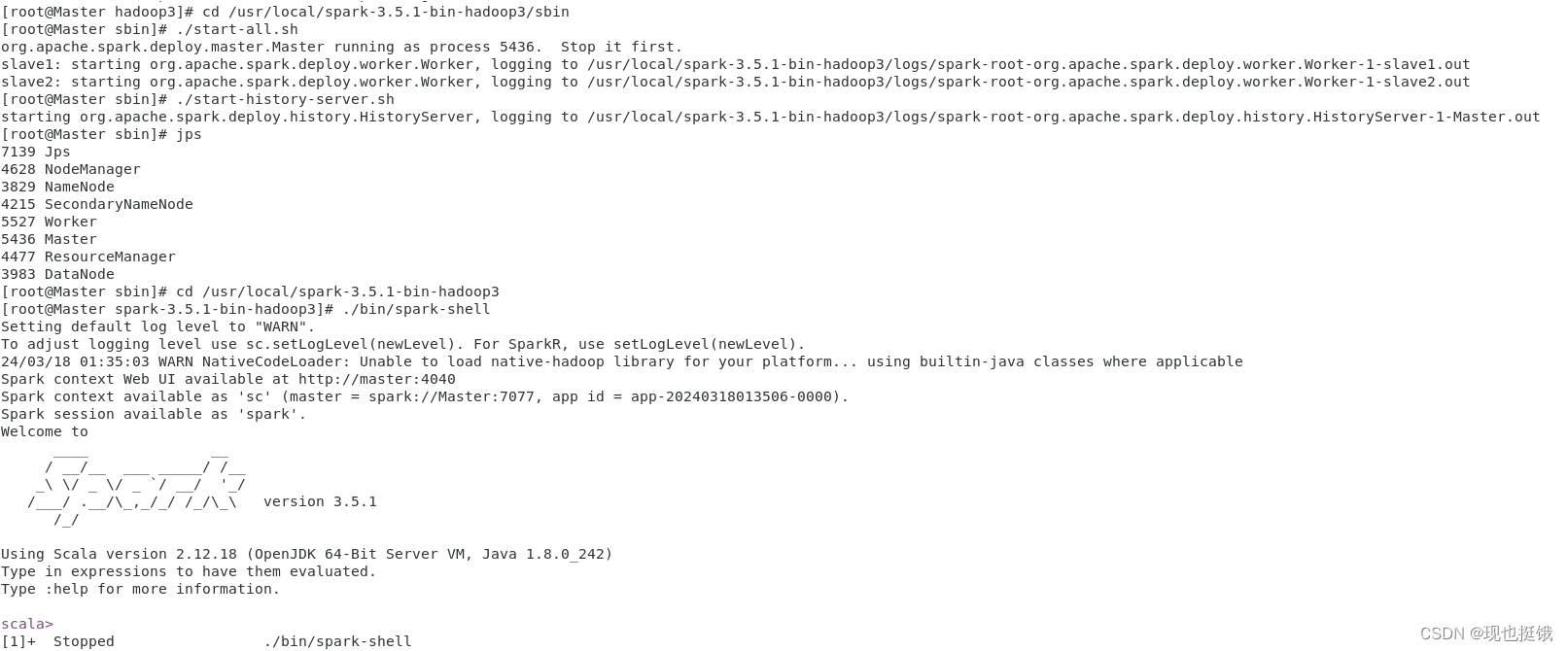
启动Spark集群















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









