









1.CPU利用率过高,代码定位
找到CPU利用率持续比较高的进程, 命令:top
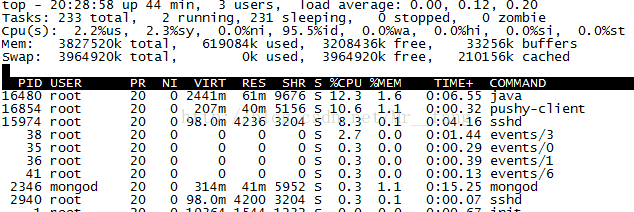
找到CPU使用率较高的线程ID(TID):
命令:ps p 16480 -L -o pcpu,pid,tid,time,tname,cmd
此处为:16498
将获取的线程号(十进制数)转换成十六进制
printf "%x\n" 16498
结果:4072
结合进程号和线程号,利用jstack查到异常代码所在行
jstack -l <pid> | grep <thread-hex-id> -A 10 命令显示出错的堆栈信息,如下图:
jstack -l 16480| grep 0x4072 -A 10
-A 10 参数用来指定显示行数,否则只会显示一行信息。
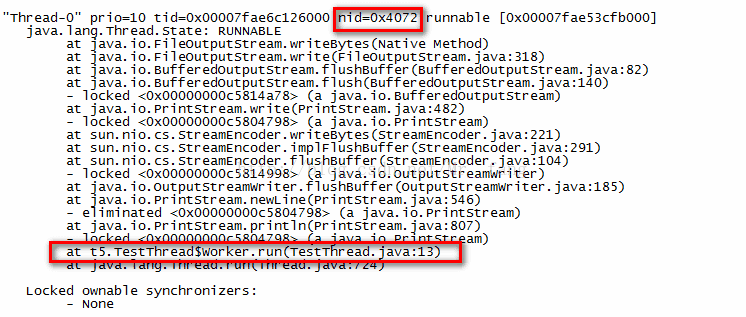
可以看到在代码的第13行有问题。也就是说是这一句导致cpu占用过高,在优化时,就可以针对这一部分代码进行优化
2.响应时间过长,代码定位及问题解决
问题的起因是笔者在一轮性能测试的中,发现某协议的响应时间很长,去观察哨兵监控里的javamethod监控可以看到以下结果:
onMessage是该协议的总入口,可以看到该协议平均耗时为352.11ms,观察其他耗时方法可以看到updateUserForeignId耗时307.75ms,那么可以认为该方法的响应时间慢是该协议的最主要性能瓶颈,这时候我们应该看看该方法究竟做了哪些操作导致响应时间过长:
从哨兵监控中可以看到userStorage.updateUserForeignId方法耗时122.86ms,userStorage.updateForeignIdPegging方法耗时71.33ms,这两个方法有成为了SessionProcessHelper.updateUserForeignId方法的主要耗时点,基于对代码的熟悉程度xxxStroge方法都是一些数据库的操作,那么现在可以初步的认为数据库的相关操作可能是问题的根源所在,为了清楚的展示问题,我们先选择一个逻辑较简单的方法分析一下,从上面的哨兵方法监控里可以看到updateSession方法耗时34.88ms,查看该方法代码:
可以看到方法只是有一个简单的dao层的操作,通过查看dao层方法可知该方法仅仅是一个update操作,按常理来说这样的操作需要三十多毫秒的耗时,显然是偏长了,既然如此,我们继续求根溯源利用哨兵的mqlcolletor来验证一下该方法底层的sql操作究竟耗时多少毫秒。此处省略通过dao层方法查找sql语句的过程,直接来看结果:
从这里可以看到底层sql响应时间是1.62ms,而dao层方法耗时高达34.88ms,这里显然有问题的,这里我们首先需要排查一下压测机,数据库的各资源指标是否到达瓶颈(在之前的性能测试中发现过类似的问题最后发现是数据库机器的磁盘util接近100%,该机器性能较差导致出现该问题,后期更换数据库机器解决了问题),通过检查这些指标可以发现cpu,内存,网络,磁盘各项指标均保持在正常水平。
问题到这里,貌似没有什么进展了,这时候就到了jstack登场了。在Java应用的性能测试中,很多性能问题可以通过观察线程堆栈来发现,Jstack是JVM自带dump线程堆栈的工具,很轻量易用,并且执行时不会对性能造成很大的影响。灵活的使用jstack可以发现很多隐秘的性能问题,是定位问题不可多得的好帮手。这里推荐一下我们组内小宝哥的一篇关于jstack使用姿势的一篇ks:巧用jstack定位性能问题
我们来jstack一下,查看在测试执行的过程中,各线程所做的操作和线程状态,可以看到以下状态:
在所有的24个线程中,多执行几次jstack可以发现大约有十个左右的线程处于waitting状态,该状态表明该线程正在执行obj.wait()方法,放弃了 Monitor,进入 “Wait Set”队列,为什么阻塞住呢,继续往下看堆栈信息,可以看到该线程正在做borrowobject操作,可以大概看到这里是一个数据库连接池的相关操作,具体到究竟是干什么的可以查看一些数据库连接池的资料:dbcp源码解读与对象池原理剖析 https://blog.csdn.net/suixinm/article/details/41761019
简单的说一下,数据库连接的使用过程:创建一个池对象工厂, 将该工厂注入到对象池中, 当要取池对象, 调用borrowObject, 当要归还池对象时, 调用returnObject, 销毁池对象调用clear(), 如果要连池对象工厂也一起销毁, 则调用close()。从这里可以很明显的看到该线程waitting的原因是没有获取到连接池里的连接对象,那么很容易就可以想象的到导致该问题的原因是数据库连接池比够用导致的,于是将连接池的大小从10修改到了50,继续执行一轮测试得到了以下结果:
可以看到updateSession方法从34.88ms下降到20.13ms,虽然耗时下降了14ms,但是距离sql耗时的1.64ms仍然有差距,沿着刚刚的思路,我们继续jstack一下,看看当前的线程状态又是如何:
在24个线程中平均下来会有十个左右的blocked状态,继续往下阅读可以发现,该线程是blocked在了log4j.Category.callAppenders上,显然可以发现这是个log4j的问题,那究竟为何会阻塞在这里呢,查看资料可以找到callAppenders的源码(具体的log4j相关资料可以看这里:Log4j 1.x版引发线程blocked死锁问题):
/**
Call the appenders in the hierrachy starting at
this. If no appenders could be found, emit a
warning.
This method calls all the appenders inherited from the
hierarchy circumventing any evaluation of whether to log or not
to log the particular log request.
@param event the event to log.
*/
public void callAppenders(LoggingEvent event) {
int writes = 0;
for(Category c = this; c != null; c=c.parent) {
// Protected against simultaneous call to addAppender, removeAppender,...
synchronized(c) {
if(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if(!c.additive) {
break;
}
}
}
if(writes == 0) {
repository.emitNoAppenderWarning(this);
}
}
我们从上面可以看出在该方法中有个synchronized同步锁,同步锁就会导致线程竞争,那么在大并发情况下将会出现性能问题,同会引起线程BLOCKED问题。那么如何优化log4j使其执行时间尽量短,防止线程阻塞呢,推荐一下我们组候姐的一篇文章:log4j不同配置对性能的影响 当前我们解决该问题的方式是去掉log4j配置文件中打印行号的选项,然后再执行一轮测试可以看到如下结果:
可以看到响应updateSession响应时间又下降了一半到了11.48ms的水平,优化到这里可以看到该dao层方法算是达到了一个正常水平,看总体的响应时间也从原先的352.11ms下降到109.19ms。可以认为解决了该协议的性能问题。 总结下来,可以发现一个典型性能问题的分析思路:发现性能问题-->查看压测机,服务器,数据库资源指标是否达到瓶颈点-->结合哨兵找到主要耗时方法-->查看耗时方法的具体代码逻辑-->具体问题具体分析(这里是结合jstack查看堆栈信息)-->条件允许范围内优化问题并验证问题。
3.使用java命令jps和jstack快速定位线程状态
线程状态定义
在线上项目中,当程序处于长时间停顿的时候,可以使用java提供的jstack命令跟踪正在执行方法的堆栈情况,jstack能够生成虚拟机当前时刻的线程堆栈情况。主要,监控线程的状态,判断出线程停顿的原因。例如,死锁,死循环,多个线程等待等等。线程的状态包括NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING,TERMINATED,其源码如下:
public enum State {
/**
* Thread state for a thread which has not yet started.
* 线程创建后尚未启动的线程处于这种状态
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* Runable包括了操作系统线程状态中的Running和Ready, 也就是处于此
状态的线程有可能正在执行, 也有可能正在等待着CPU为它分配执行时间
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* 线程被阻塞了, “阻塞状态”与“等待状态”的区别是: “阻塞状态”在等
待着获取到一个排他锁, 这个事件将在另外一个线程放弃这个锁的时候发生; 而“等待状
态”则是在等待一段时间, 或者唤醒动作的发生。 在程序等待进入同步区域的时候, 线程将
进入这种状态。
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* 无限期等待状态,处于这种状态的线程不会被分配CPU执行时间,它们要等待被
其他线程显式地唤醒
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* 线程等待被唤醒,处于这种状态的线程也不会被分配CPU执行时间, 不过无
须等待被其他线程显式地唤醒, 在一定时间之后它们会由系统自动唤醒
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* 线程已经执行结束
*/
TERMINATED;
}
线程之间的状态转换如图:
线程状态跟踪
在Java中,使用jps命令,查询正在运行的虚拟机java进程,一般显示信息就是,pid和进程名称。示例如下:
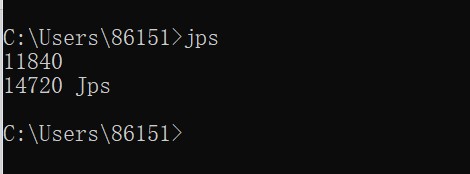
图-2
使用jstack [pid] 输出当前进程的堆栈信息。主要有两种使用方式,如下:
控制台输出堆栈信息 jstack pid,示例:

图-3
将堆栈信息输出到执行文件 jstack pid > file。示例,输出pid 11840的进程堆栈信息存储到dump11840文件中,执行命令jstack 11840 > C:\Users\86151\Desktop\dump11840。结果如下:

图-4

图-5
堆栈信息分析:示例堆栈信息如图:

图-6
- 线程名称,ApplicationImpl pooled thred 450。
- 线程优先级。
- tid十六进制地址。
- 线程十六进制地址。
- 线程当前状态,TIMED_WAITING。
- 线程当前执行的方法,park。
示例常见停顿场景
死锁场景
在线程嵌套的获取锁,就有可能产生死锁,如下给出死锁的代码示例,和堆栈信息。代码示例如下:
public class DeadLockDemo {
private static String a = "a";
private static String b = "b";
private void deadLock() {
Thread t1 = new Thread(() -> {
synchronized (a) {
System.out.println("get a lock thread " + Thread.currentThread().getName());
try {
// 延时2秒
Thread.sleep(2000L);
} catch (Exception e) {
}
synchronized (b) {
System.out.println("get b lock thread " + Thread.currentThread().getName());
}
}
});
Thread t2 = new Thread(() -> {
synchronized (b) {
System.out.println("get b lock thread " + Thread.currentThread().getName());
synchronized (a) {
System.out.println("get a lock thread " + Thread.currentThread().getName());
}
}
});
t1.start();
t2.start();
}
public static void main(String[] args) {
new DeadLockDemo().deadLock();
}
}
程序运行后,线程t1获取a的锁,线程t2获取b的锁。然后,当线程2尝试获取a的锁时,线程t1尝试获取b,由于此时a和b的锁都没有释放,就产生了死锁。执行的程序日志输出如下:

堆栈信息如下:

上图中,代码35行和代码24行引起了死锁。
长时间等待
线程长时间,分配不到cpu而进入等待状态。下面模拟一个线程在执行,大批量线程在等待的场景,示例代码如下:
public class LongWaitDemo {
private void longWait() {
for (int i = 0; i < 100; i++) {
Thread thread = new Thread(() -> {
while (true) {
System.out.println("executing thread " + Thread.currentThread().getName());
try {
// 延时2000秒
Thread.sleep(2000000L);
} catch (Exception e) {
}
}
});
thread.start();
}
Thread t2 = new Thread(() -> {
while (true) {
try {
// 延时1秒
Thread.sleep(1000L);
} catch (Exception e) {
}
System.out.println("executing thread " + Thread.currentThread().getName());
}
});
t2.start();
}
public static void main(String[] args) {
new LongWaitDemo().longWait();
}
}
跟踪其堆栈信息,会发现几乎全是TIMED_WAITING的状态的信息,如图:

4.tomcat应用无法启动
问题现象:环境搭建时,部署应用后tomcat无法启动,查看日志并无报错现象,直观感觉tomcat启动时好像卡在了哪里,所以我们希望看到tomcat启动时究竟发生了什么,导致启动无法完成,这时线程堆栈中的函数调用关系也许可以帮上忙,jstack得到对应tomcat应用的线程堆栈,如下:
"localhost-startStop-1" daemon prio=10 tid=0x0000000002da2000 nid=0x630b in Object.wait() [0x00007f1863538000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000007d6924800> (a org.apache.curator.framework.state.ConnectionStateManager)
at java.lang.Object.wait(Object.java:503)
at org.apache.curator.framework.state.ConnectionStateManager.blockUntilConnected(ConnectionStateManager.java:215)
- locked <0x00000007d6924800> (a org.apache.curator.framework.state.ConnectionStateManager)
at org.apache.curator.framework.imps.CuratorFrameworkImpl.blockUntilConnected(CuratorFrameworkImpl.java:223)
at org.apache.curator.framework.imps.CuratorFrameworkImpl.blockUntilConnected(CuratorFrameworkImpl.java:229)
at com.netease.kaola.kschedule.client.curator.CuratorSupport.initZK(CuratorSupport.java:81)
at com.netease.kaola.kschedule.client.curator.CuratorSupport.check(CuratorSupport.java:293)
- locked <0x00000007d64af060> (a java.lang.Class for com.netease.kaola.kschedule.client.curator.CuratorSupport)
at com.netease.kaola.kschedule.client.curator.CuratorSupport.checkExists(CuratorSupport.java:113)
at com.netease.kaola.kschedule.client.job.JobManagerImpl.isSchedulerStop(JobManagerImpl.java:218)
at com.netease.kaola.kschedule.client.job.JobManagerImpl.startScheduler(JobManagerImpl.java:134)
at com.netease.kaola.kschedule.client.KScheduleClientFactory.init(KScheduleClientFactory.java:90)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
...
问题分析:首先关注线程状态,是处于WATING(on object monitor),这时线程执行了Object.wait(),处于挂起状态,在等待被唤醒,而且这里并没有设置超时时间,所以只要线程没被唤醒,tomcat会一直等下去。但tomcat在等什么呢,查看函数调用信息可以看到“com.netease.kaola.kschedule.client.curator.CuratorSupport.initZK”,这个函数是kschedule启动时需要初始化zookeeper,应用启动就是卡在了这里。知道问题所在就好办, 查看kschedule的配置,发现zookeeper的ip用的是私有ip,与应用不通,更改成机房ip后问题解决。
数据库连接池不够用导致响应时间久
问题现象:在测试一个场景时,发现响应时间很长,日志也无报错现象,根据调用链逐级定位,发现80%的时间都是消耗在DAO层的方法上,这时首先考虑的是sql会不会有问题?于是找DBA同学帮忙抓sql看下,但DBA同学反映sql执行很快,执行计划也没有问题,那问题出现在哪里呢,找不到原因就看下线程堆栈,系统在dao层方法后做了什么?jstack线程堆栈如下:
"DubboServerHandler-10.165.184.51:20881-thread-200" daemon prio=10 tid=0x00007f2fd6208800 nid=0x504b waiting on condition [0x00007f2fc0280000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x000000078172f2c0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:226)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2082)
at com.alibaba.druid.pool.DruidDataSource.pollLast(DruidDataSource.java:1487)
at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1086)
at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:953)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4544)
at com.alibaba.druid.filter.logging.LogFilter.dataSource_getConnection(LogFilter.java:827)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:931)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:923)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:100)
at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:111)
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:77)
at org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:81)
at org.mybatis.spring.transaction.SpringManagedTransaction.getConnection(SpringManagedTransaction.java:67)
at org.apache.ibatis.executor.BaseExecutor.getConnection(BaseExecutor.java:279)
at org.apache.ibatis.executor.SimpleExecutor.prepareStatement(SimpleExecutor.java:72)
at org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:59)
...
问题分析:先关注线程状态,发现堆栈信息里大量的dubbo线程处于TIMED_WAITING状态,从“waiting on condition”可以看出系统在等待一个条件发生,这时的线程处于sleep状态,一般会有超时时间唤醒,一般出现TIMED_WAITING很正常,一些等待IO都会出现这种状态,但是大量的TIMED_WAITING就要找原因了,观察线程堆栈发现处于TIMED_WAITING状态的线程都在等待druid获取连接池的连接,这种现象很想连接池不够用了,于是增加数据库连接池的连接数,TPS直接提升了3倍。
线程阻塞导致响应变慢
问题现象:同样是在测试场景时发现响应时间变慢,并且响应时间的毛刺现象比较严重,依次排查系统可能的瓶颈点没有明显收获,这时jstack又排上用场了,先看线程堆栈:
"DubboServerHandler-10.165.184.34:20880-thread-199" daemon prio=10 tid=0x00007f3cb4196000 nid=0x6048 waiting for monitor entry [0x00007f3cabb79000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.log4j.Category.callAppenders(Category.java:204)
- waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
at org.apache.log4j.Category.forcedLog(Category.java:391)
at org.apache.log4j.Category.info(Category.java:666)
at netease.qp.spellcheck.Facade.logInfo(Facade.java:26)
at netease.qp.kaola.service.impl.SearchPhraseServiceImpl.getSearchGoodsResult(SearchPhraseServiceImpl.java:60)
at com.alibaba.dubbo.common.bytecode.Wrapper1.invokeMethod(Wrapper1.java)
at com.alibaba.dubbo.rpc.proxy.javassist.JavassistProxyFactory$1.doInvoke(JavassistProxyFactory.java:46)
at com.alibaba.dubbo.rpc.proxy.AbstractProxyInvoker.invoke(AbstractProxyInvoker.java:72)
at com.alibaba.dubbo.rpc.protocol.InvokerWrapper.invoke(InvokerWrapper.java:53)
at com.alibaba.dubbo.rpc.protocol.dubbo.filter.TraceFilter.invoke(TraceFilter.java:78)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.monitor.support.MonitorFilter.invoke(MonitorFilter.java:65)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.TimeoutFilter.invoke(TimeoutFilter.java:42)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.ExceptionFilter.invoke(ExceptionFilter.java:64)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.ContextFilter.invoke(ContextFilter.java:60)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.GenericFilter.invoke(GenericFilter.java:112)
...
问题分析:可以看到线程是处于BLOCKED状态的,这种状态我们需要重点关注,这时的线程是被阻塞的,进一步查看发现几乎所有的dubbo线程都处于block状态,都在“waiting to lock <0x000000078c312718>”,这个<0x000000078c312718>又是个什么鬼?
Line 57: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 119: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 169: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 207: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 257: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 295: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 345: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 407: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 588: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 686: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 790: - locked <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 840: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 954: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 995: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 1105: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 1143: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
Line 1197: - waiting to lock <0x000000078c312718> (a org.apache.log4j.spi.RootLogger)
...
通过排查发现这个锁是log4j拿到的,同时阻塞了其他线程通过log4j打日志,Google类似问题才知道是log4j的一个bug,可以通过升级log4j版本或者精简日志避免,知道原因后经过相应的处理,性能得到大幅度提升,这里安利一篇侯姐关于log4j优化的文章:http://doc.hz.netease.com/pages/viewpage.action?pageId=26313263















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









