






一,开始配置
目的:为master,slave1,slave2三个镜像配置hadoop的高可用性
警告:本文实验性目的,如需高安全性或在非安全环境下搭建请查阅官方文档。本文只为在实验环境下简单快速填鸭式的搭建实验性的hadoop HA来帮助新手快速上手并理解基础概念。
| NameNode | ZkFc | DataNode | JournalNode | ResourceManager | zk集群 | |
|---|---|---|---|---|---|---|
| master | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |
| slave1 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |
| slave2 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
这是搭建完成后每个镜像所要运行的服务
二,NameNode
NameNode负责管理这个整个集群元数据和集群管理,以及命名空间,在master节点中运行。为了防止单点故障,利用zookeeper在slave2中也设立了一个NameNode用于保证高可靠,在一个NameNode停止工作时进行替换,在原NameNode正常工作过程中保持同步数据。
NameNode同时只能有一个提供例如web的客户端服务,处于Active状态,另一个为Standby(直译为跟随)就是同步状态。NameNode提供服务,两个NameNode存储的元数据是实时同步的,当Active的NameNode出现问题时,通过zk实时切换到Standby的NameNode上,并将Standby改为Active状态。
客户端通过连接zk的代理来确定当时是哪个NameNode处于服务状态。
三,ZKFC
ZKFC在每个节点上都会开启,监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群。本质为开启一个zk自己的namenode去实时汇报状态,是一个临时节点,临时节点特征是客户端的 连接断开后就会把znode删掉,所以当ZKFC失效时,也会导致切换NameNode。
DataNode会将心跳信息和Block块,汇报信息同时发送给NameNode,但DataNode只会接受Active NameNode发来的 文件读写命令。
四,JournalNode
JournalNode 节点作为 Active 节点和 Standby 节点的中间节点,它为两个节点解决了数据的同步的问题。首先 Active 节点会将元数据发送给 JournalNode 节点,然后 Standby 节点会从 JournalNode 节点获取需要同步的元数据。即使 Standby 节点故障了、产生问题了,在它恢复正常状态后,也可以从 JournalNode 节点中同步相应的数据。这就要求 JournalNode 节点需要有持久化的功能来保证元数据不丢。
配置步骤
一,前置
1,启动vm虚拟机这里使用centos7
2,配置网络
输入命令
vi /etc/sysconfig/network-scripts/ifcfg-en33修改如下几个字段(这里的IPADDR后面的IP要按照自己的所需要的IP来就进行适当修改,我这里以172.16.1.244为例子)
BOOTPROTO="static" IPADDR=172.16.1.244 NETMASK=255.255.255.0 GATEWAY=172.16.1.1修改后输入
systemctl restart network3,一般要关闭防火墙
systemctl stop firewalld systemctl disable firewalld4,关闭SElinux
setenforce 0这里每次都要关闭或者改配置文件永久关闭看你自己
二,更新安装软件
1,更新系统
yum update yum install -y yum-utils device-mapper-persistent-data lvm2这里会跳很多东西,中间如果有
Is this ok [y/N]:就用英文输入法输入y表示同意
2,安装dockeryum install docker这个一样记得输入y同意
3,启动docker服务systemctl enable docker systemctl start docker
4,验证一下docker是否正常安装docker version
正常会跳出版本
三,开始配置docker
1,拉取centos7的容器
docker pull daocloud.io/centos:7 docker images(这个命令用来看本地所有镜像)
2,创建一个叫做netgroup的子网docker network create --subnet=172.19.0.0/16 netgroup3,创建在一个虚拟局域网内容器,使用的是上一步的netgroup
这里建立三个(master,slave1,slave2)
docker run -itd --privileged -v /sys/fs/cgroup:/sys/fs/cgroup --name master -h master --network netgroup --ip 172.19.0.2 -p 8088:8088 -p 9870:9870 -p 9820:9820 daocloud.io/centos:7 /usr/sbin/init这个是名为master的容器,将容器内的端口映射到主机上,分别将容器内的 8088、9870 和 9820 端口映射到主机上的相同端口,配置了特权访问、网络设置、主机名、IP 地址、端口映射等选项。
下面创建另外两个容器
docker run -itd --privileged -v /sys/fs/cgroup:/sys/fs/cgroup --name slave1 -h slave1 --network netgroup --ip 172.19.0.3 daocloud.io/centos:7 /usr/sbin/initdocker run -itd --privileged -v /sys/fs/cgroup:/sys/fs/cgroup --name slave2 -h slave2 --network netgroup --ip 172.19.0.4 daocloud.io/centos:7 /usr/sbin/init
四,使用远程ssh进入liunx配置所需要的程序
1,用MobaXterm接入你的服务器连接你刚才的修改过的IP(我的就是172.16.1.244)
2,创建三个分开来的ssh界面分别进入master,slave1和slave2容器
进入master
docker exec -it master /bin/bash
同理去建立slave1和slave2的界面并进入容器
3,分别查看ip,如果你是按照我写的顺序去创建容器,那么ip应该分别是
172.19.0.2 master 172.19.0.3 slave1 172.19.0.4 slave2如果不确定就输入
hostname -i去查看一下,记住这写ip以方便发现问题进行溯源
4,部署Openssh(所有容器都要执行一遍)
yum -y install openssh openssh-server openssh-clients启动sshd服务(所有容器都要执行一遍)
systemctl start sshd systemctl enable sshd更改root密码(所有容器都要执行一遍)
passwd root
记住你设置的密码,建议全部一样,不执行这步可能会导致ssh加密出现问题
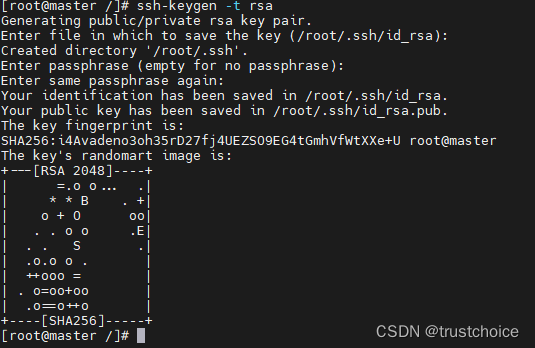
为每一个容器都输入
ssh-keygen -t rsa
中间所有的询问让你输入东西全部回车跳过,因为是实验环境所以不考虑安全性,如果是生产环境请查阅官方文档获得支持
使用私钥对应的公钥进行SSH连接时的验证(每一个都要运行一遍)
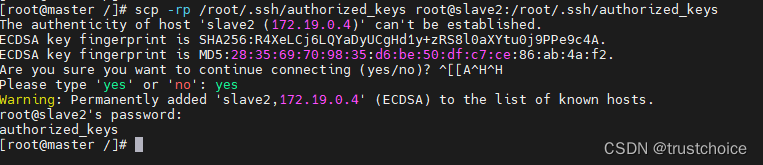
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys在master执行
scp -rp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys scp -rp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys
先输入yes同意,然后输入你当初设定的密码
在slave1执行
scp -rp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys scp -rp /root/.ssh/authorized_keys root@master:/root/.ssh/authorized_keys同样输入yes然后输入你设定的密码(同master)
在slave2执行
scp -rp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys scp -rp /root/.ssh/authorized_keys root@master:/root/.ssh/authorized_keys同样输入yes然后输入你设定的密码(同master)
五,配置hadoop还有jdk
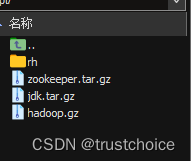
这些是你所要的文件,去网上下到你的windows电脑上
全部重命名为下列形式
然后传输到
这个opt文件夹里面
然后在主机里面输入
docker cp /opt/ master:/再进入到master这个容器里面,进入opt文件夹(cd opt)
可以看到有文件了
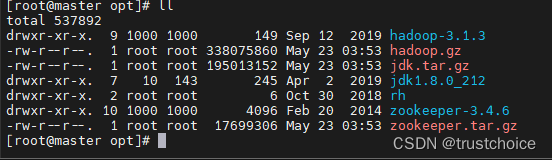
然后解压缩文件
tar -zxvf /opt/jdk.tar.gz -C /opt/ tar -zxvf /opt/hadoop.gz -C /opt/ tar -zxvf /opt/zookeeper.tar.gz -C /opt/解压完成后
配置环境变量
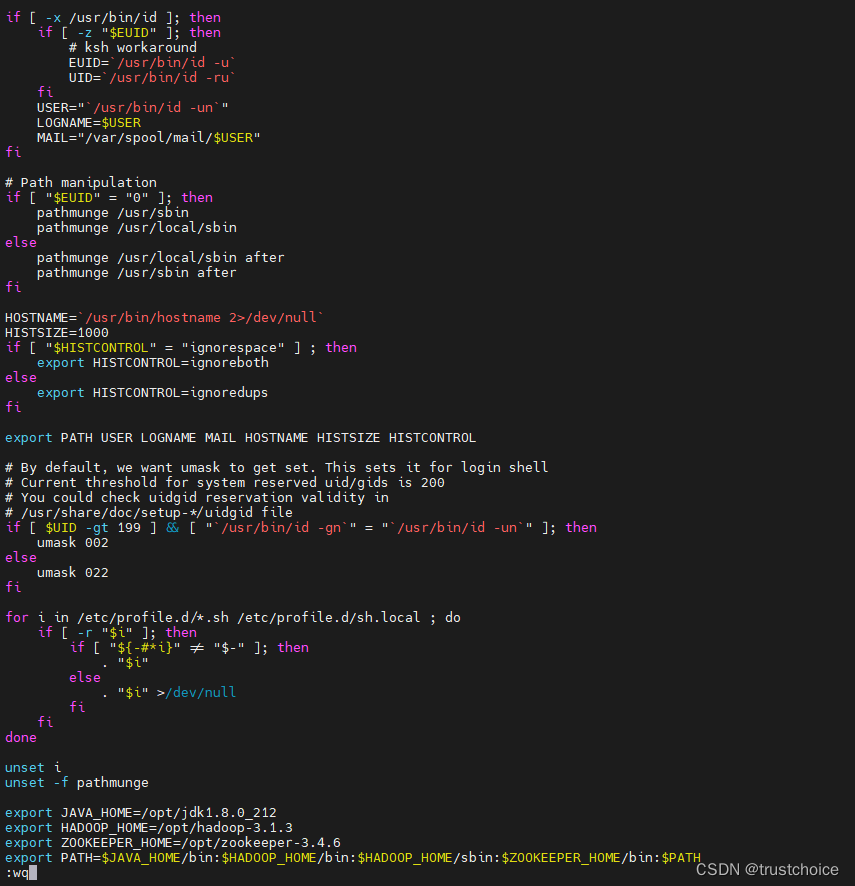
vi /etc/profile进入后在最下面输入
export JAVA_HOME=/opt/jdk1.8.0_212 export HADOOP_HOME=/opt/hadoop-3.1.3 export ZOOKEEPER_HOME=/opt/zookeeper-3.4.6 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$PATH
如图所示
然后刷新文件
source /etc/profile
六,配置zookeeper
创建zookeeper的data目录
mkdir -p /opt/zookeeper-3.4.6/data cp /opt/zookeeper-3.4.6/conf/zoo_sample.cfg zoo.cfg然后为创建myid文件
touch /opt/zookeeper-3.4.6/data/myid然后修改zoo.cfg文件
vi /opt/zookeeper-3.4.6/conf/zoo.cfg在末尾加上
dataDir=/opt/zookeeper-3.4.6/data server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888
七,搭建HDFS HA
配置Hadoop-env.sh
vi /opt/hadoop-3.1.3/etc/hadoop/hadoop-env.sh在该文件底部加上
export JAVA_HOME=/opt/jdk1.8.0_212 export HADOOP_HOME=/opt/hadoop-3.1.3 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root修改works中的namenode节点
vi /opt/hadoop-3.1.3/etc/hadoop/workers打开应该是
这个样子
删掉localhost
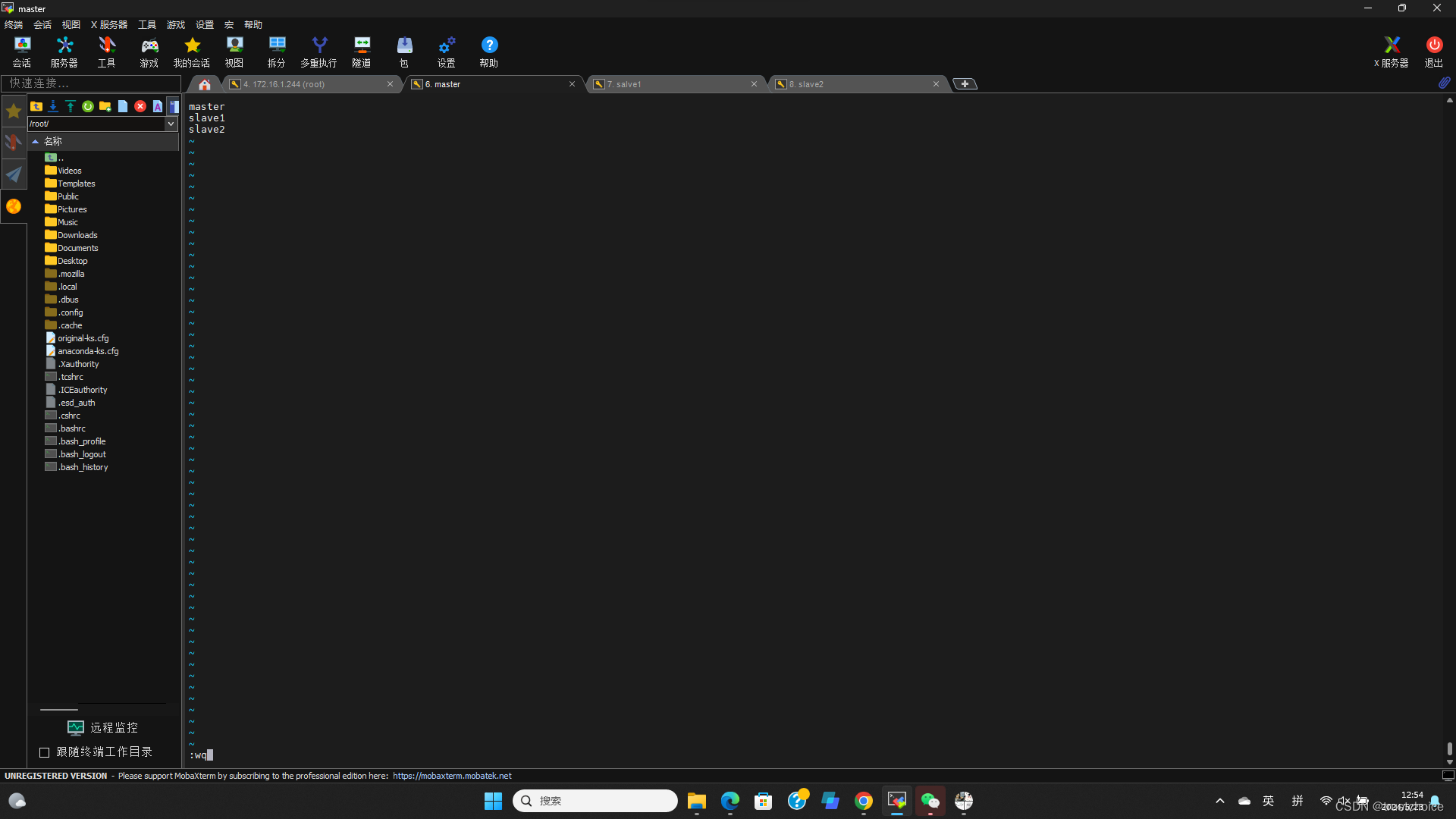
加入
master slave1 slave2
修改成这个样子
然后修改core-site.xml这个文件
vi core-site.xml在<configuration>和</configuration>添加下列文本
<!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定hadoop数据的存储 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-3.1.3/data</value> </property> <!--指定每个zookeeper服务器的位置和客户端端口号--> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <!-- 解决HDFS web页面上删除、创建文件权限不足的问题 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>root</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>root</value> </property>修改hdfs-site.xml文件
vi hdfs-site.xml在<configuration>和</configuration>添加下列文本
<configuration> <!--集群名称--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--集群中NameNode节点--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--NameNode RPC通讯地址--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>master:9820</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>slave2:9820</value> </property> <!--NameNode http通讯地址--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>master:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>slave2:9870</value> </property> <!--NameNode元数据在JournalNode上存放的位置--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;slave1:8485;slave2:8485/my_cluster</value> </property> <!--JournalNode数据存放目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop-3.1.3/data/journal/data</value> </property> <!--启用nn故障自动转移--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--访问代理类:client用于确定哪个NameNode为Active--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置隔离机制,即同一时刻只能有一台服务器对外响应--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--使用隔离机制时需要ssh秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--隔离的超时时间--> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>修改mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>修改yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
八,分发配置并补全修改部分差异
为slave1和slave2配置环境变量
scp /etc/profile root@slave1:/etc/ scp /etc/profile root@slave2:/etc/传输结束后记得(每一个都要执行)
source /etc/profile配置myid
vi /opt/zookeeper-3.4.6/data/myid ##master填写1,slave1的myid中填写2,slave2中填写3
以上就是配置全部过程,下面检验是否成功配置
首先启动ZK集群(每个都要启动)
zkServer.sh start可以输入jps验证是否启动
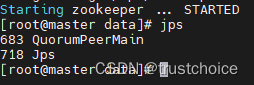
然后启动journal node(每个容器都要启动)
hdfs --daemon start journalnode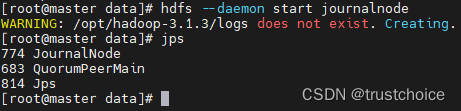
格式化hdfs
hdfs namenode -format
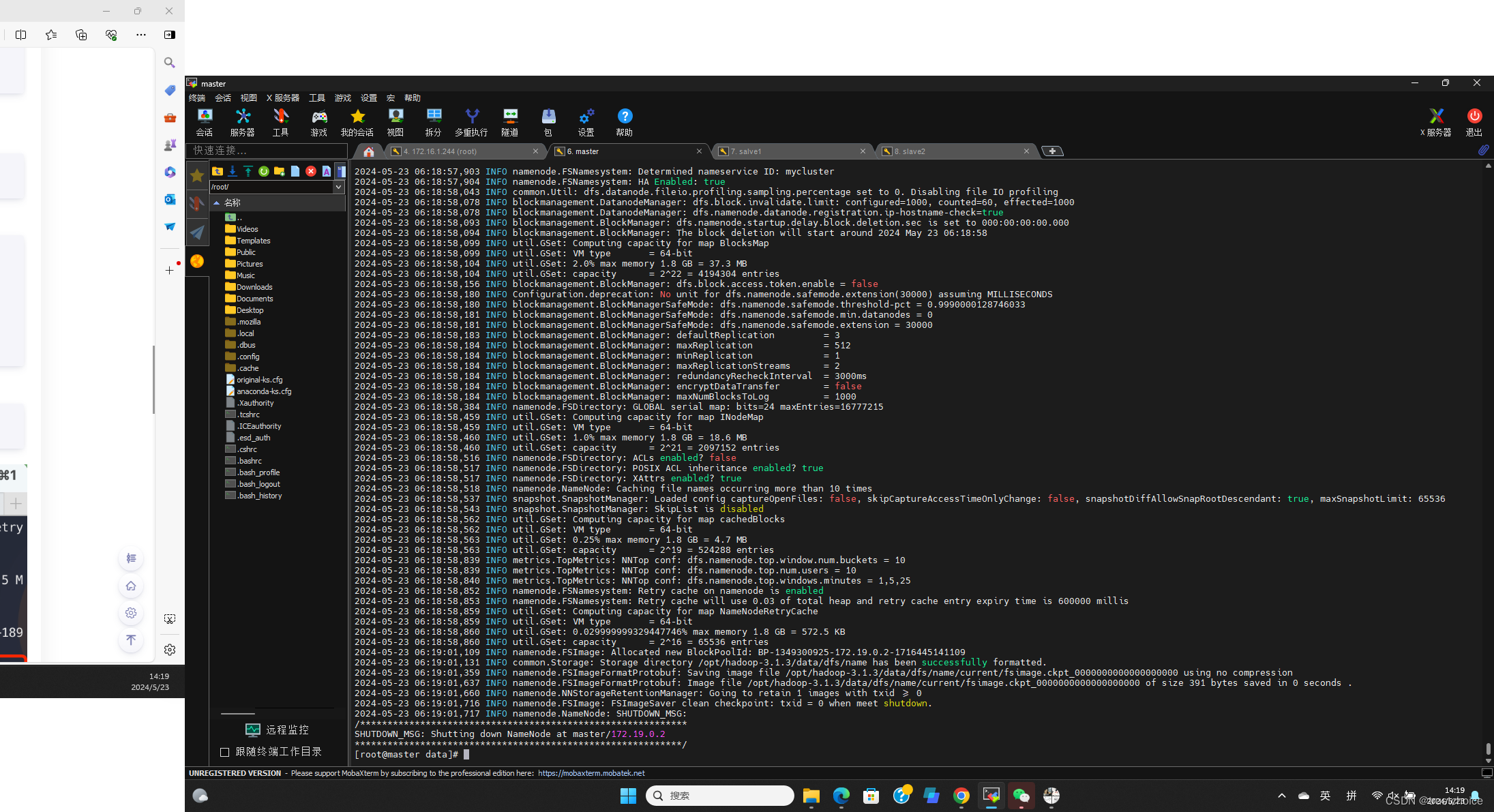
格式化成功
尝试在master上启动namenode
hdfs --daemon start namenode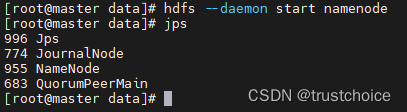
成功
在slave2上进行同步数据
hdfs namenode -bootstrapStandby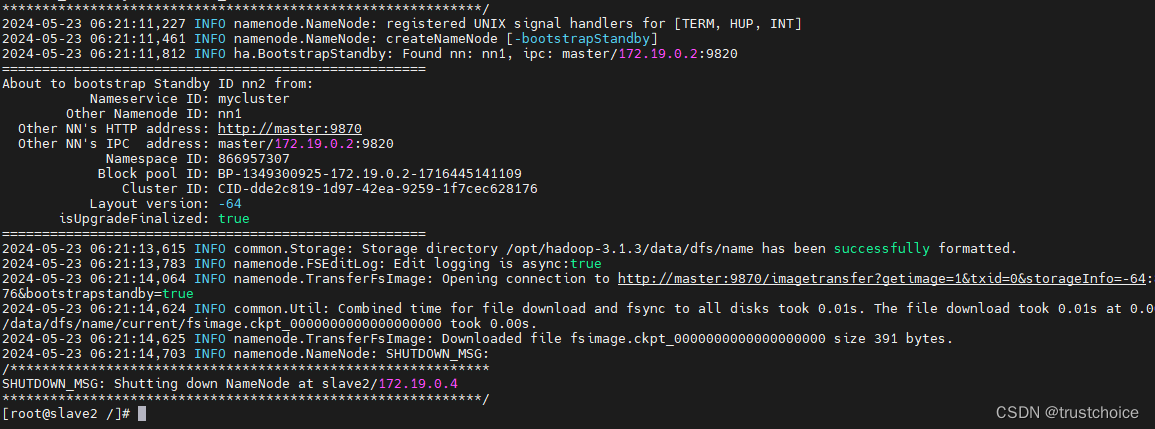
成功
然后启动namenode(在slave2上)
hdfs --daemon start namenode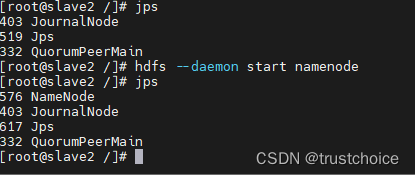
很明显成功了
我们格式化一下zkfc然后启动剩下的datanode(在master上执行)
hdfs zkfc -formatZK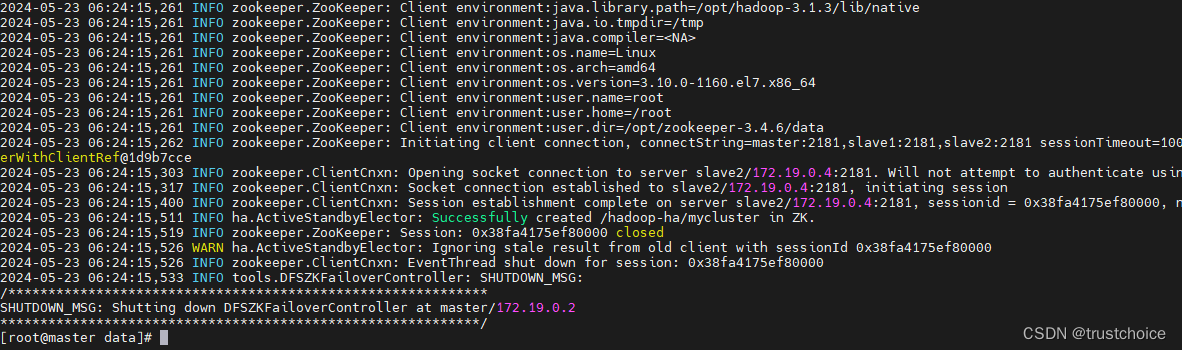
成功
在master上启动hadoop集群试一下
start-all.sh
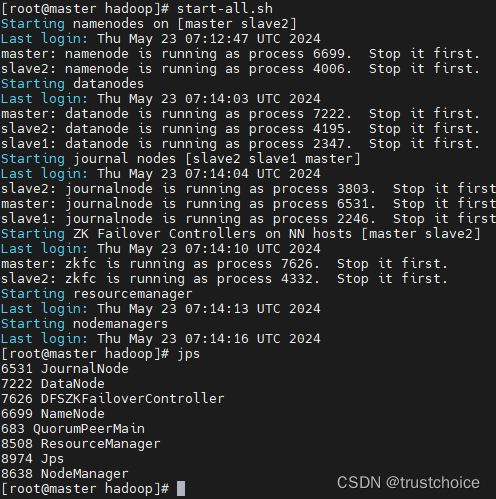
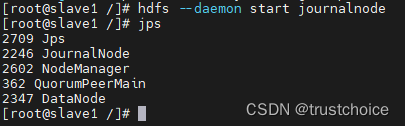
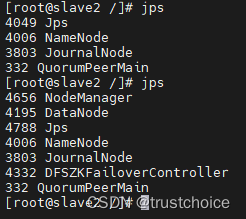
全部启动了
部分命令,表格来源于网络。转载需要注明出处
来源
Hadoop3 HDFS HA 高可用搭建及测试 - shine-rainbow - 博客园 (cnblogs.com)
csdn hadoop配置相关文档,
百度百科















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









