






 文章讲述了如何在ChatGPT中使用prompt引导其编写正则表达式,以实现文本匹配功能,包括识别首字母大写单词、限定字符长度和单词末尾标点。作者通过实例演示了这些功能,并展示了如何通过Python验证其有效性。
文章讲述了如何在ChatGPT中使用prompt引导其编写正则表达式,以实现文本匹配功能,包括识别首字母大写单词、限定字符长度和单词末尾标点。作者通过实例演示了这些功能,并展示了如何通过Python验证其有效性。
### 背景介绍
ChatGPT是一个基于OpenAI的GPT(Generative Pre-trained Transformer)模型的变种,它是一个强大的自然语言处理(NLP)工具。GPT系列模型的主要特点是预训练和生成能力,能够根据输入的文本生成具有连贯性和合理性的输出文本。ChatGPT特别针对对话式应用进行了优化。它经过在大规模文本数据上进行预训练,并通过阅读大量的对话数据来学习对话风格和语言表达。因此,它可以用于许多自然语言处理任务,如对话生成、问答系统、文本摘要、语言翻译等。
Prompt是用户向模型提供任务指导和输入信息的方式,它直接影响了模型生成的回答或结果的质量和准确性。一个好的prompt可以引导模型产生有用、合理且符合预期的回答,而一个不合适或模糊的prompt可能导致模型输出错误、无关或混乱的内容。
- 任务说明:在ChatGPT中编写和使用正则表达式,以实现文本匹配和模式提取的功能。
- 待匹配文本:
Enron Dataset: Over half a million anonymized emails from over 100 users. It’s one of the few publically available collections of “real” emails available for study and training sets.
Google Blogger Corpus: Nearly 700,000 blog posts from blogger.com. The meat of the blogs contain commonly occurring English words, at least 200 of them in each entry.
SMS Spam Collection: Excellent dataset focused on spam. Nearly 6000 messages tagged as legitimate or spam messages with a useful subset extracted directly from Grumbletext.
Recommender Systems Datasets: Datasets from a variety of sources, including fitness tracking, video games, song data, and social media. Labels include star ratings, time stamps, social networks, and images.
Project Gutenberg: Extensive collection of book texts. These are public domain and available in a variety of languages, spanning a long period of time.
- 实践步骤:
- 编写prompt让ChatGPT写一个能识别首字母大写单词的正则。
- 编写prompt让ChatGPT写一个能识别首字母大写且字符个数小于10的正则。
- 编写prompt让ChatGPT写一个能识别单词末尾为标点符号的正则。
- 上述实验过程进行截图,通过Python代码验证ChatGPT输出正则的有效性。
1.编写prompt让ChatGPT写一个能识别首字母大写单词的正则。
输入: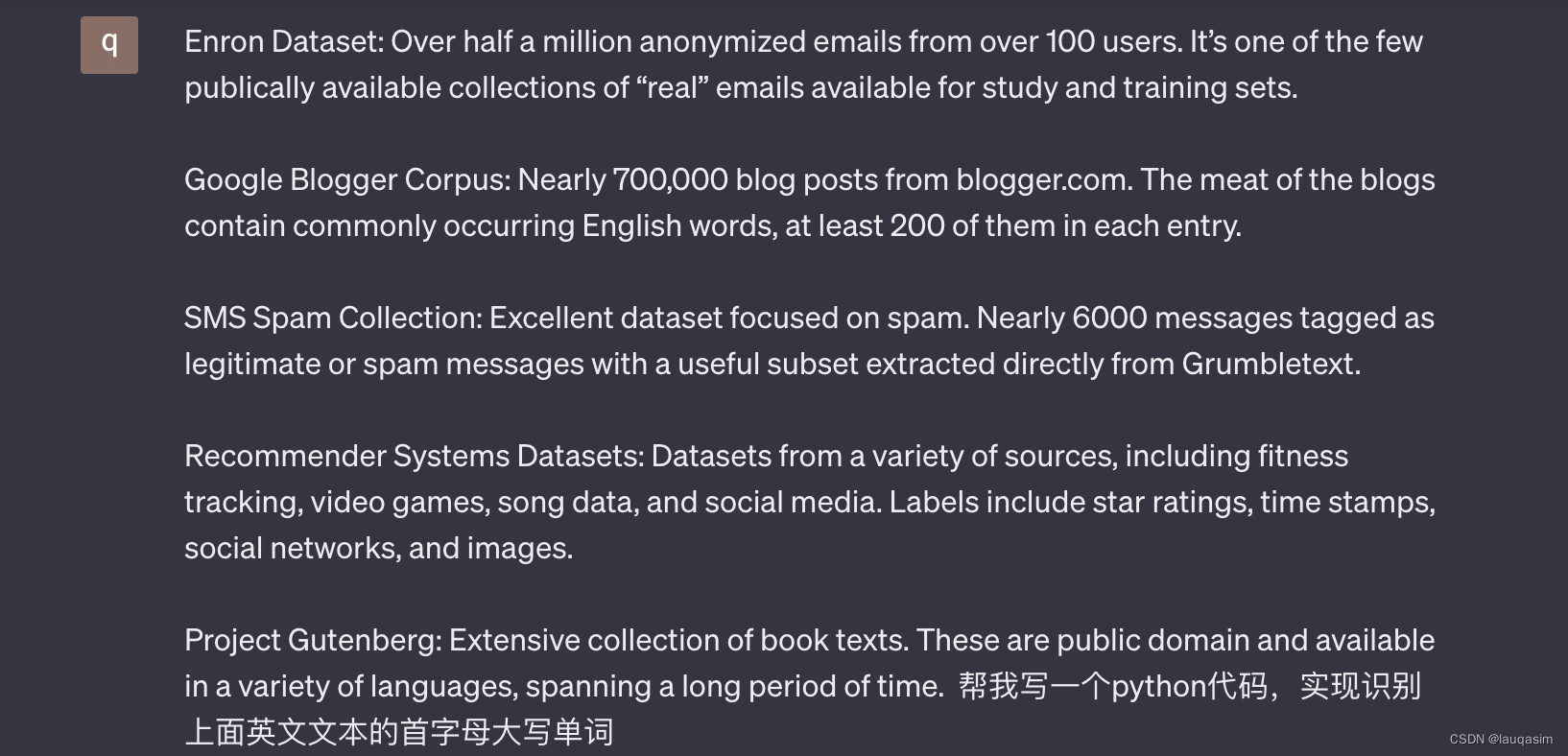
ChatGPT输出:
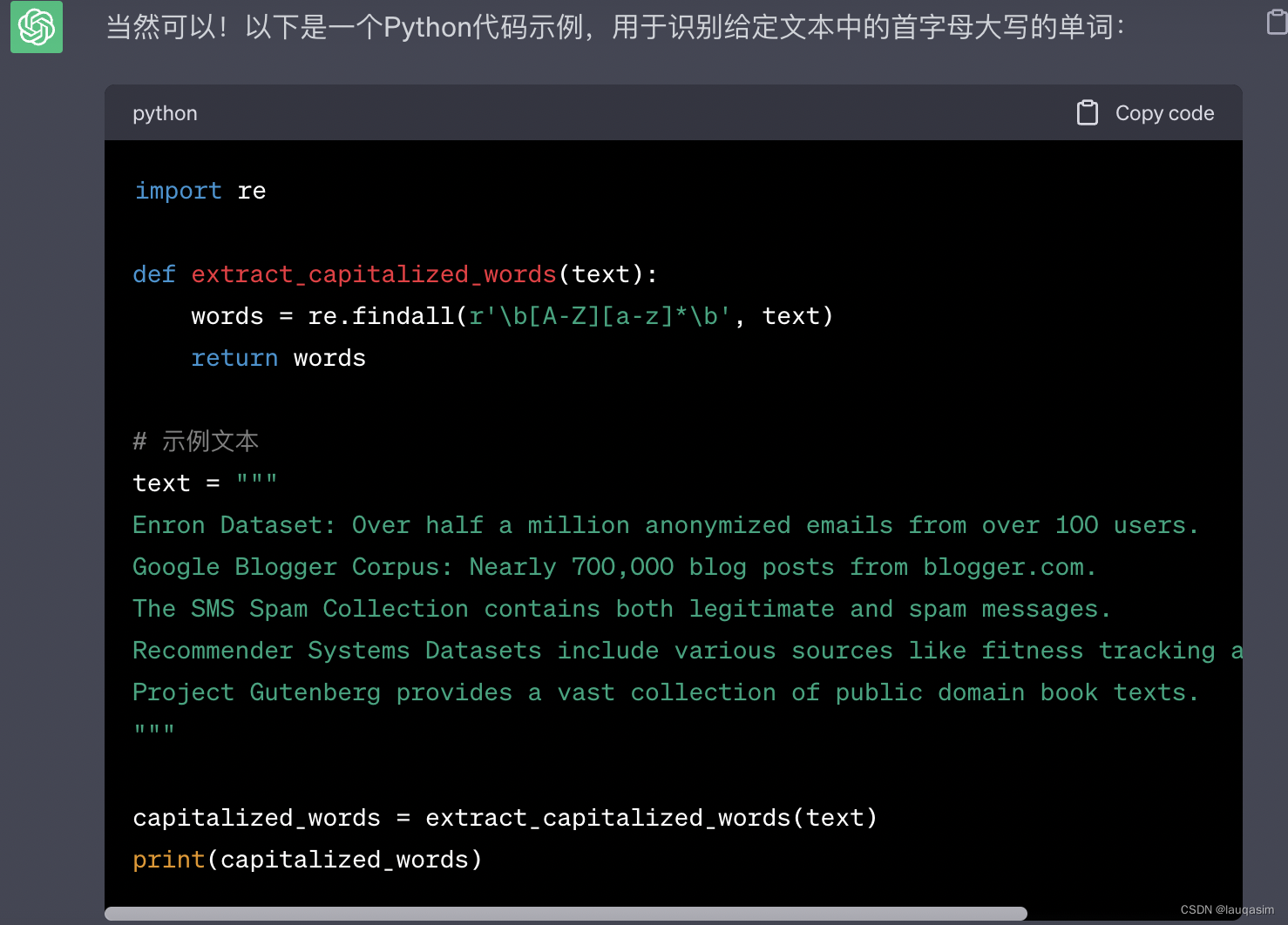
将代码copy到vs code中运行:
import re
def extract_capitalized_words(text):
words = re.findall(r'\b[A-Z][a-z]*\b', text)
return words
# 示例文本
text = """
Enron Dataset: Over half a million anonymized emails from over 100 users.
Google Blogger Corpus: Nearly 700,000 blog posts from blogger.com.
The SMS Spam Collection contains both legitimate and spam messages.
Recommender Systems Datasets include various sources like fitness tracking and social media.
Project Gutenberg provides a vast collection of public domain book texts.
"""
capitalized_words = extract_capitalized_words(text)
print(capitalized_words)
结果为:
['Enron', 'Dataset', 'Over', 'Google', 'Blogger', 'Corpus', 'Nearly', 'The', 'Spam', 'Collection', 'Recommender', 'Systems', 'Datasets', 'Project', 'Gutenberg']
表现不错
2.编写prompt让ChatGPT写一个能识别首字母大写且字符个数小于10的正则。
输入和输出
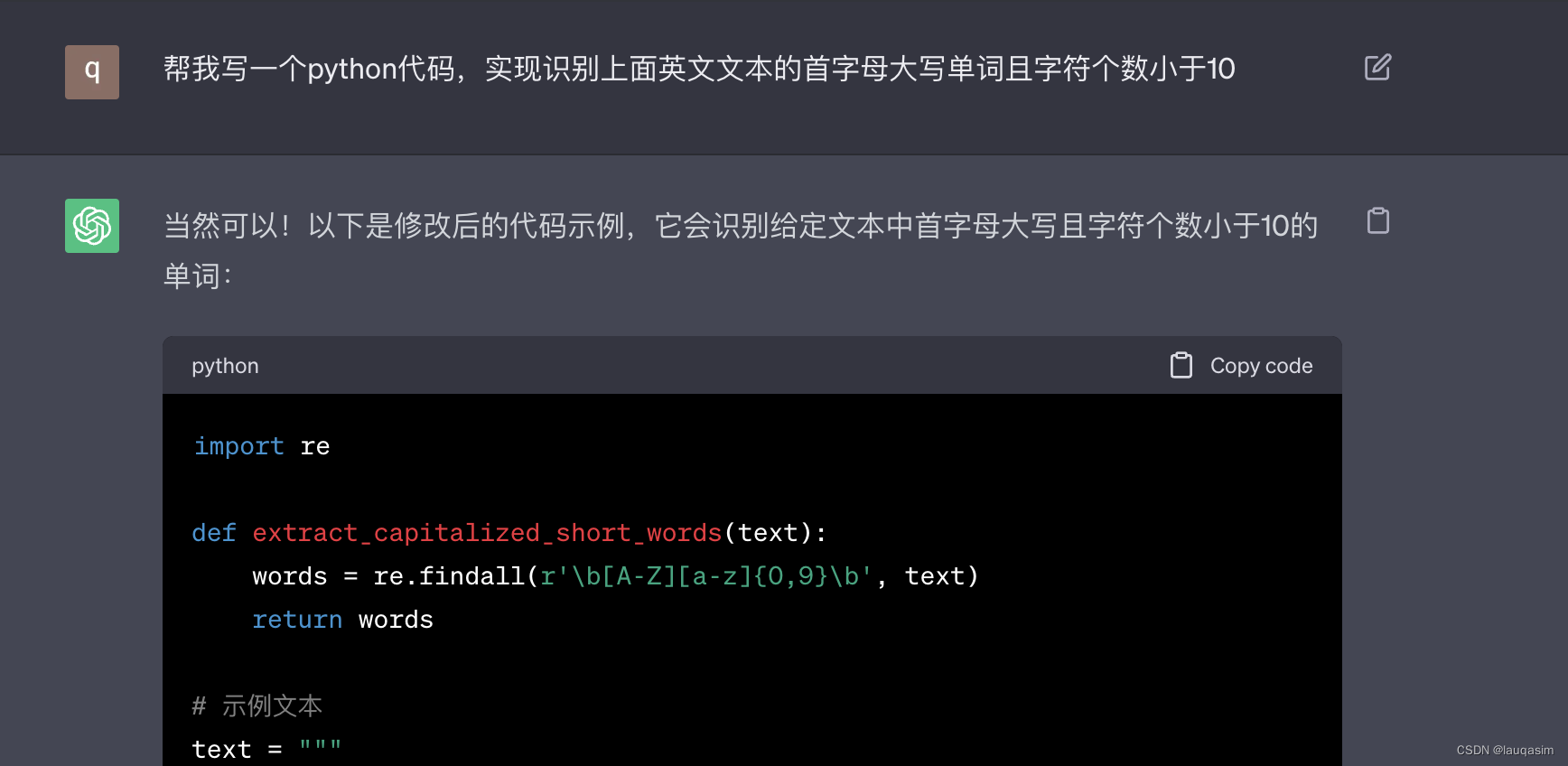
copy到vs code运行
import re
def extract_capitalized_short_words(text):
words = re.findall(r'\b[A-Z][a-z]{0,9}\b', text)
return words
# 示例文本
text = """
Enron Dataset: Over half a million anonymized emails from over 100 users.
Google Blogger Corpus: Nearly 700,000 blog posts from blogger.com.
The SMS Spam Collection contains both legitimate and spam messages.
Recommender Systems Datasets include fitness tracking and social media.
Project Gutenberg provides a vast collection of public domain book texts.
"""
capitalized_short_words = extract_capitalized_short_words(text)
print(capitalized_short_words)
结果:
['Enron', 'Dataset', 'Over', 'Google', 'Blogger', 'Corpus', 'Nearly', 'The', 'Spam', 'Collection', 'Systems', 'Datasets', 'Project', 'Gutenberg']
靠谱
3.编写prompt让ChatGPT写一个能识别单词末尾为标点符号的正则。
输入:

import re
text = """
Enron Dataset: Over half a million anonymized emails from over 100 users. It’s one of the few publically available collections of “real” emails available for study and training sets.
Google Blogger Corpus: Nearly 700,000 blog posts from blogger.com. The meat of the blogs contain commonly occurring English words, at least 200 of them in each entry.
SMS Spam Collection: Excellent dataset focused on spam. Nearly 6000 messages tagged as legitimate or spam messages with a useful subset extracted directly from Grumbletext.
Recommender Systems Datasets: Datasets from a variety of sources, including fitness tracking, video games, song data, and social media. Labels include star ratings, time stamps, social networks, and images.
Project Gutenberg: Extensive collection of book texts. These are public domain and available in a variety of languages, spanning a long period of time.
"""
# 使用正则表达式匹配以标点符号结尾的单词
pattern = r'\b\w+,\s'
matches = re.findall(pattern, text)
# 去除匹配结果中的逗号和空格
matched_words = [match.rstrip(', ') for match in matches]
print(matched_words)
考虑的不够详细
再次输入:
你没有考虑到单词边界为回车换行符的情况,也没有考虑到其他符号的情况(:;'<>,.)
import re
text = """
Enron Dataset: Over half a million anonymized emails from over 100 users. It’s one of the few publically available collections of “real” emails available for study and training sets.
Google Blogger Corpus: Nearly 700,000 blog posts from blogger.com. The meat of the blogs contain commonly occurring English words, at least 200 of them in each entry.
SMS Spam Collection: Excellent dataset focused on spam. Nearly 6000 messages tagged as legitimate or spam messages with a useful subset extracted directly from Grumbletext.
Recommender Systems Datasets: Datasets from a variety of sources, including fitness tracking, video games, song data, and social media. Labels include star ratings, time stamps, social networks, and images.
Project Gutenberg: Extensive collection of book texts. These are public domain and available in a variety of languages, spanning a long period of time.
"""
# 使用正则表达式匹配以标点符号结尾的单词
pattern = r'\b\w+[,:;\'<>\."”\n]\s'
matches = re.findall(pattern, text)
# 去除匹配结果中的标点符号和空格
matched_words = [re.sub(r'[,:;\'<>\."”\n]\s$', '', match) for match in matches]
print(matched_words)
输出:
['Dataset', 'users', 'real', 'sets', 'Corpus', 'com', 'words', 'entry', 'Collection', 'spam', 'Grumbletext', 'Datasets', 'sources', 'tracking', 'games', 'data', 'media', 'ratings', 'stamps', 'networks', 'images', 'Gutenberg', 'texts', 'languages', 'time']
差不离!
4.上述实验过程进行截图,通过Python代码验证ChatGPT输出正则的有效性。
如上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









