







 本文介绍了程序分别在Linux和Hadoop环境中的运行步骤。在Linux中,需新建目录和文件,编写内容并添加执行权限后运行;在Hadoop环境中,要新建run.sh文件,配置相关信息,添加权限,上传文件,运行脚本并查看保存结果。
本文介绍了程序分别在Linux和Hadoop环境中的运行步骤。在Linux中,需新建目录和文件,编写内容并添加执行权限后运行;在Hadoop环境中,要新建run.sh文件,配置相关信息,添加权限,上传文件,运行脚本并查看保存结果。
目录
零、码仙励志
年轻人不要老想着天上会掉馅饼,要脚踏实地,也许地上会捡到钱呢?
一、在Linux中运行
首先在Linux中新建下面的目录,里面什么也不要放,然后进入到目录
/home/hadoopuser/mydoc/py

然后在里面创建一个ddd.txt文件
![]()
里面编写下面内容
aaa
bbb
aaa
bbb
ddd
ccc
ddd
接着新建mapper.py文件
![]()
里面编写下面内容
#!/usr/bin/env python
# encoding=utf-8
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
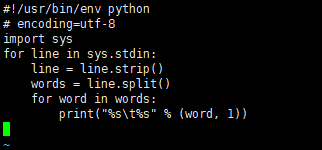
接着新建reduce.py文件
![]()
里面编写下面内容
#!/usr/bin/env python
# encoding=utf-8
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word
if word == current_word: #不要忘记最后的输出
print("%s\t%s" % (current_word, current_count))
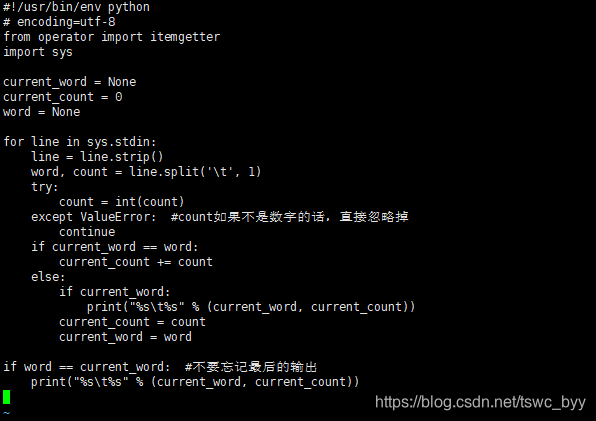
此时一共有三个文件
![]()
接着给mapper.py添加执行权限
chmod 777 mapper.py ![]()
接着给reduce.py添加执行权限
chmod 777 reduce.py![]()
接下来开始运行
mapper.py程序运行
more ddd.txt | python ./mapper.py
排序运行
more ddd.txt | python ./mapper.py | sort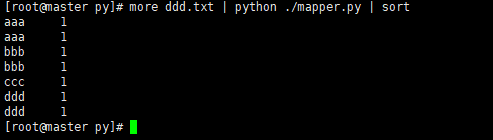
more ddd.txt | python ./mapper.py | sort -k1,1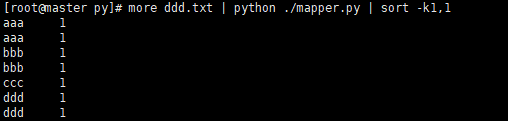
俩个程序同时运行
more ddd.txt | python ./mapper.py | sort -k1,1 | ./reduce.py
二、在Hadoop环境中运行
还是在这个目录下,新建一个run.sh文件
里面的内容如下
hadoop jar /opt/hadoop/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.5.jar \
-file /home/hadoopuser/mydoc/py/mapper.py -mapper /home/hadoopuser/mydoc/py/mapper.py \
-file /home/hadoopuser/mydoc/py/reduce.py -reducer /home/hadoopuser/mydoc/py/reduce.py \
-input /tmp/py/input/* -output /tmp/py/output
第一行配置的是hadoop-streaming-2.7.5.jar所在的位置,根据你的具体情况修改
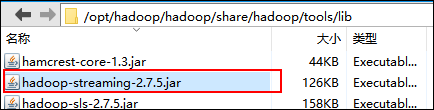
我的环境是根据下面这篇博客搭建的
然后给run.sh添加可执行权限
chmod 777 run.sh![]()
接着在hdfs环境下新建文件夹
hdfs dfs -mkdir -p /tmp/py/input![]()
然后把ddd.txt上传进去
hdfs dfs -put ddd.txt /tmp/py/input![]()
接着运行run.sh
source run.sh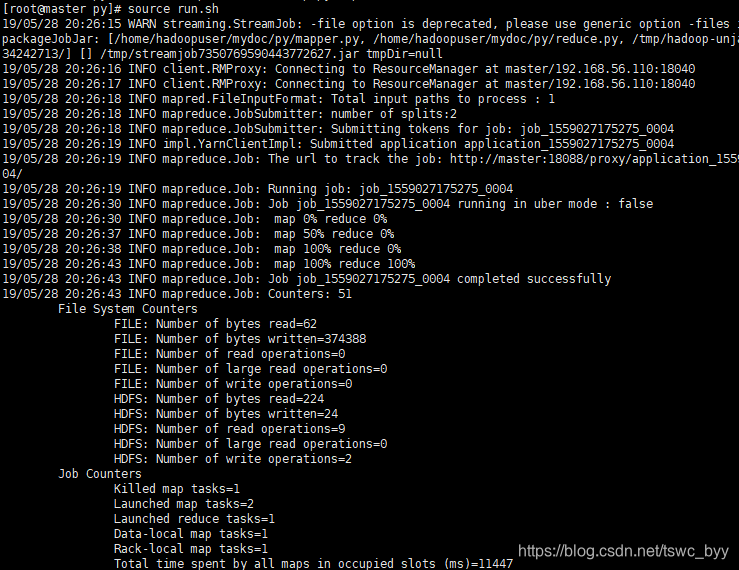
接着查看生成的文件
hdfs dfs -ls /tmp/py/output
其中part-00000就是运行结果,打开看一下
hdfs dfs -cat /tmp/py/output/part-00000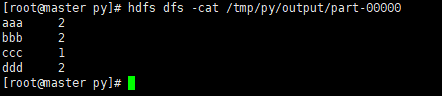
然后把运行结果保存到本地
hdfs dfs -get /tmp/py/output/part-00000 /home/hadoopuser/mydoc/py![]()
查看是否保存成功




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









