







文章目录
1. 确认数据库名称和要导出的数据表名称
以数据库biyesheji和数据表app01_classnames为例。
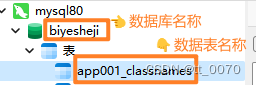
2. 在Navicat中查询表结构
1. 在Navicat中新建查询文件
右键单击自己的数据库名,找到“新建查询”,单击新建。
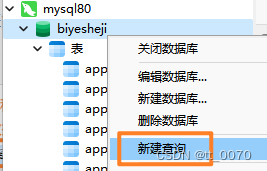
会生成一个空白的查询文件。
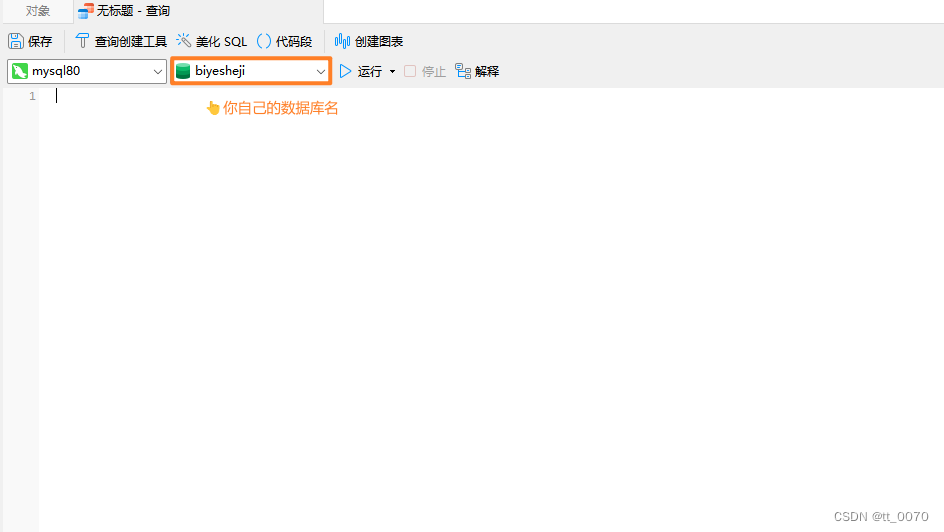
2. 执行查询文件
- 将以下的代码复制进新建好的查询文件中,并将注释标注的位置修改数据库名称和数据表名称
代码部分参考
SELECT
COLUMN_NAME 列名,
COLUMN_COMMENT 备注(字段含义),
COLUMN_TYPE 数据类型,
DATA_TYPE 字段类型,
CHARACTER_MAXIMUM_LENGTH 长度,
IS_NULLABLE 是否为空,
COLUMN_DEFAULT 默认值
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
table_schema = 'biyesheji' -- 👈修改为自己的数据库名称
AND
table_name = 'app001_classnames' -- 👈修改为要导出的数据表名称
- 点击“保存”按钮,将文件保存在对应的数据库中,以防文件丢失。
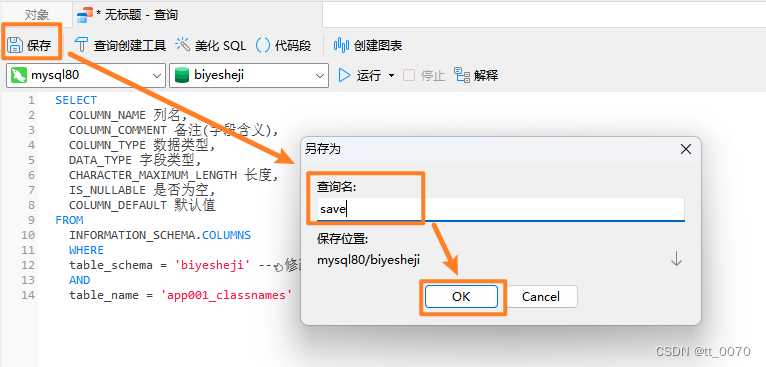
- 点击“运行”按钮,即可得到查询结果如下图。
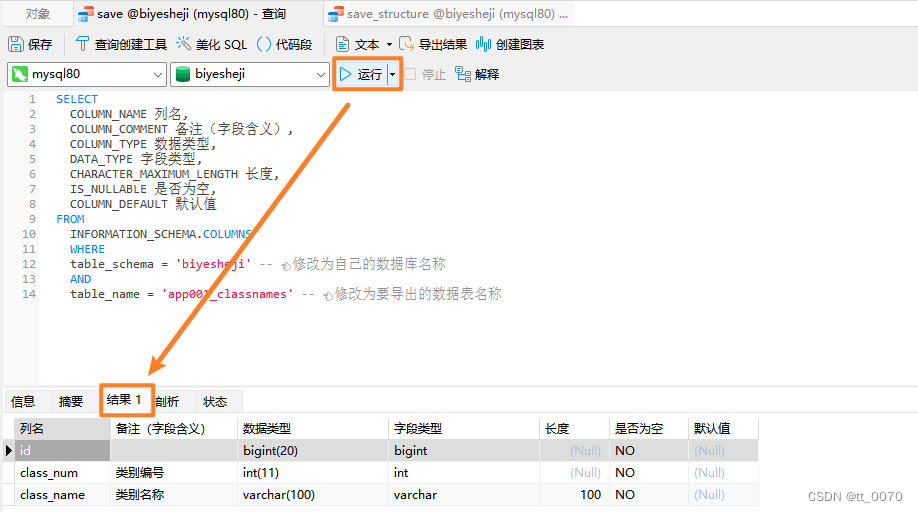
3. 在word中创建一个三线表
1. 在word中插入一个表格
在word中点击“插入”,选择“表格”,根据实际情况创建表格。
本例中,查询结果为7*4:

那么我们就新建一个7*4大小的表格:

2. 将表格样式更改为三线表
💠在选中表格之后,word的顶部导航栏会出现“表设计”选项,点击即可。

- 全选表格,按照下图中的步骤依次点击“边框”→“无框线”→“上框线”→“下框线”

此时,表格样式如下图,只有上框线和下框线。
- 选择“边框刷”,在第一行下方绘制一条横线,如下图所示。
- 绘制完成后即可得到三线表,如下图。
4. 将查询结果导入word三线表
💠小问题:从Navicat的查询结果复制粘贴的时候,只能复制到数据内容,表头那一行目前只能自己手动输入(不过一般而言,一篇论文中要写的数据库表结构会有很多张,只需要自己手动输入一次表头,其余的也直接复制即可,也还算是比较省事)
💠要是大佬们还有别的好办法,欢迎在评论区讨论😊
-
手动输入表头

-
在Navicat中全选要复制的数据,Ctrl+C复制

-
全选表格中的空白位置,Ctrl+V粘贴

-
结果如下图。

-
此时的表格样式可能不太美观,根据自己的需求调整即可,简单调整后如下图。

由此,将数据表结构从Navicat中导入word三线表就完成了。

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









