







drop table if exists wzfll;
create table wzfll as
select
t.一级品种分类名称,
DENSE_RANK()over(order by t.一级品种分类名称 desc) as 一级品种分类名称排名,
t.二级品种分类名称,
DENSE_RANK()over(PARTITION by t.一级品种分类名称 ORDER BY t.一级品种分类名称,t.二级品种分类名称 desc) as 二级品种分类名称排名,
t.三级品种分类名称,
DENSE_RANK()over(PARTITION by t.一级品种分类名称,二级品种分类名称 ORDER BY t.一级品种分类名称,t.二级品种分类名称,t.三级品种分类名称 desc)三级品种分类名称排名,
t.四级品种分类名称,
DENSE_RANK()over(PARTITION by t.一级品种分类名称,二级品种分类名称,t.三级品种分类名称 ORDER BY t.一级品种分类名称,t.二级品种分类名称,t.三级品种分类名称,t.四级品种分类名称 desc) 四级品种分类名称排名
from
(select DISTINCT * from class) t
where 三级品种分类名称 is not null;
select * from wzfll;数据结构当然是画图最清楚啦~ 那就用深度遍历优先遍历一个分支
如下图是以上代码运行后的结果:
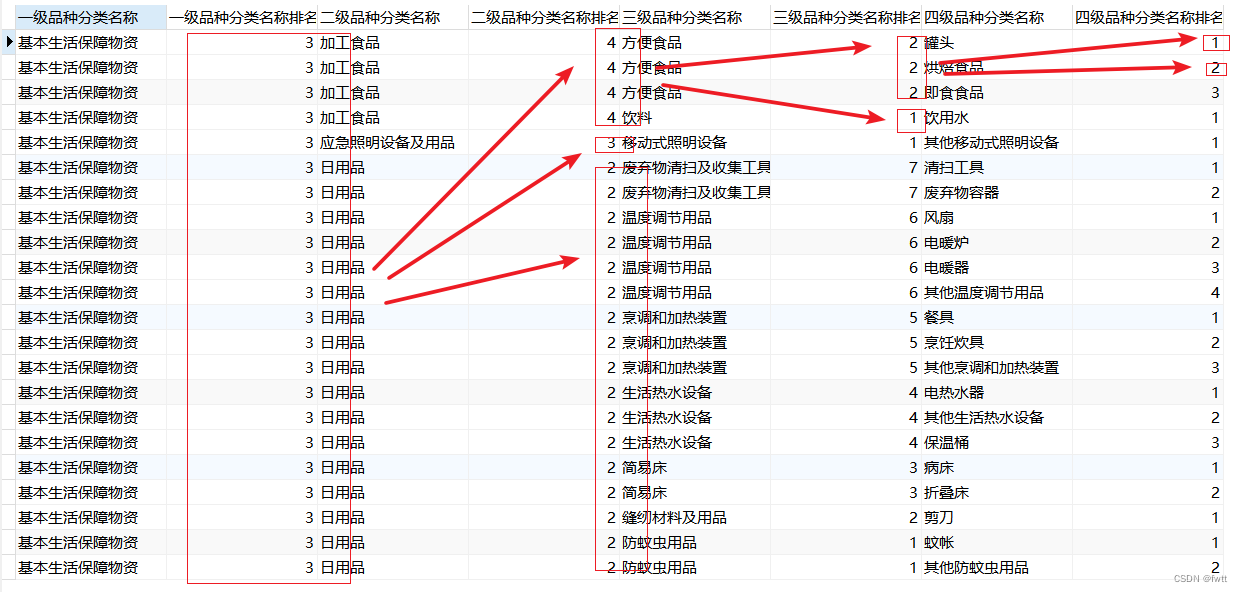















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









