






文章目录
一、概念
1.1类比现实生活


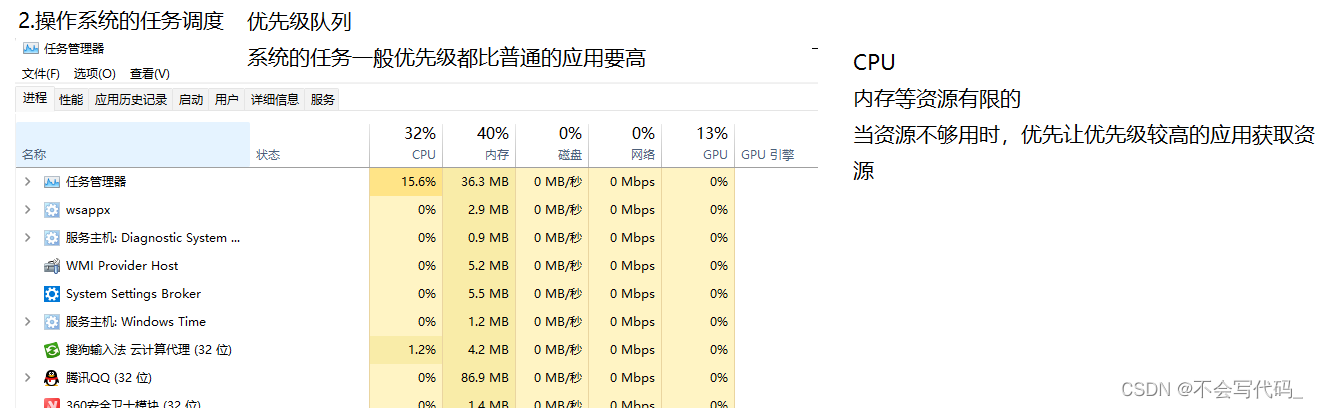
1.2与普通队列区别

二、基于二叉树的堆的特点
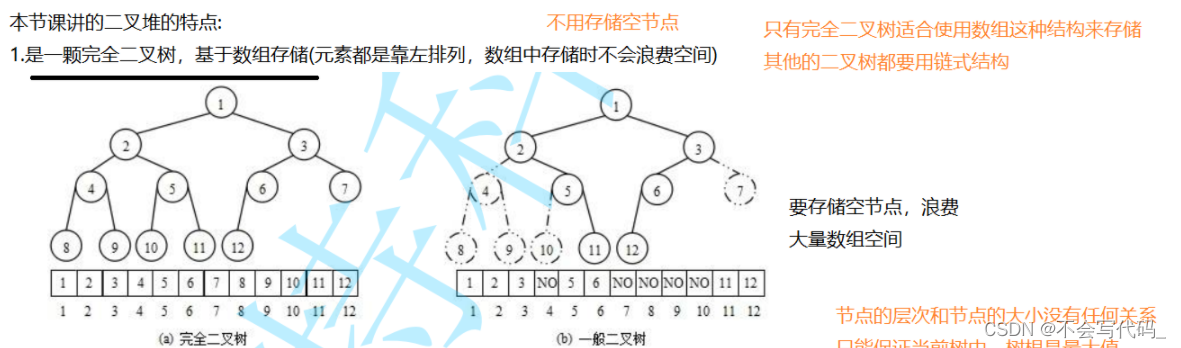
2.1关于存储结构
完全二叉树一般采用数组结构存储
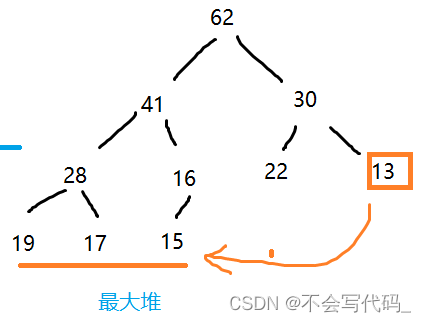
2.2关于节点值

是否层次越高,根的节点值一定越大?

2.3关于节点的编号
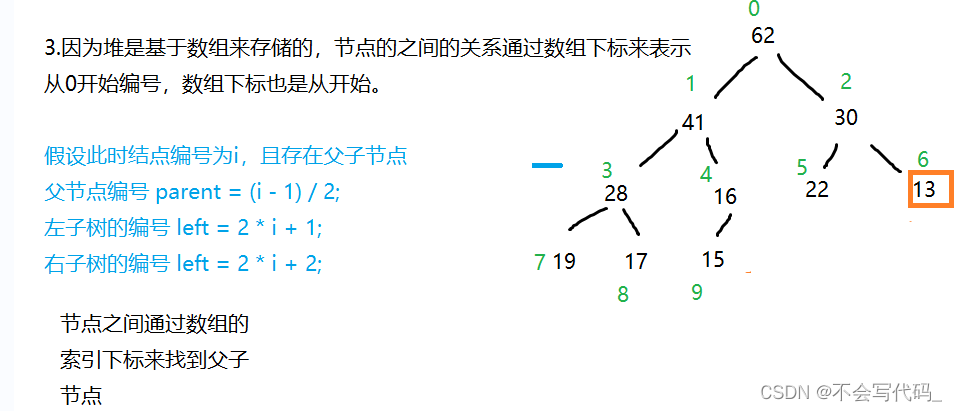
2.4判断堆的条件

三、堆的三大核心操作
代码示例如下
/**
* 基于动态数组实现最大堆
* @author hide_on_bush
* @date 2022/6/24
**/
public class MaxHeap {
//动态数组存储元素
private List<Integer> data;
//当前堆中元素个数
private int size;
public boolean isEmpty(){
return size==0;
}
public int getSize(){
return size;
}
/**
* 找到节点k对应的父节点索引
* */
private int parent(int k){
return (k-1)>>1;
}
/**
* 找到节点k对应的左子树索引
* */
private int leftChild(int k) {
return (k<<1)+1;
}
/**
* 找到节点k对应的右子树索引
* */
private int rightChild(int k) {
return (k<<1)+2;
}
}
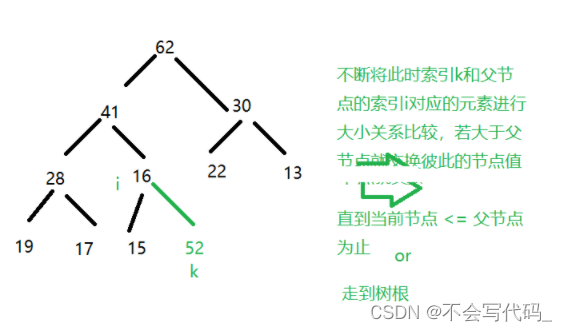
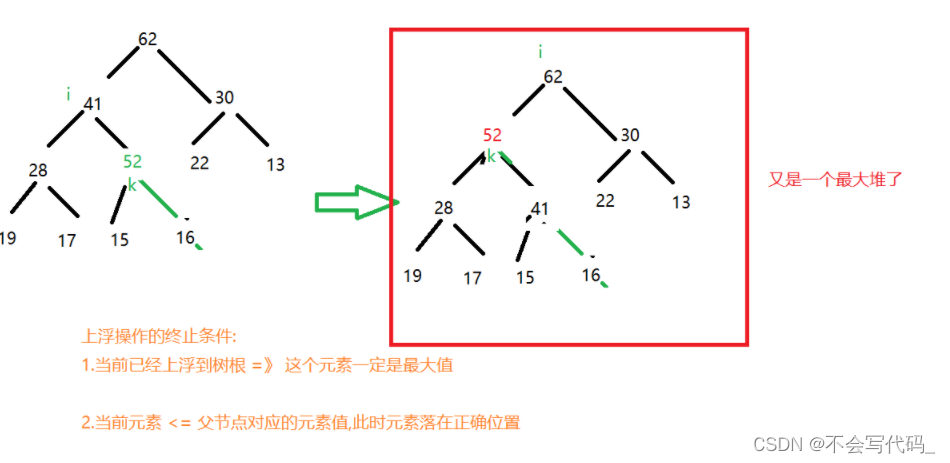
3.1堆中添加元素 siftUp
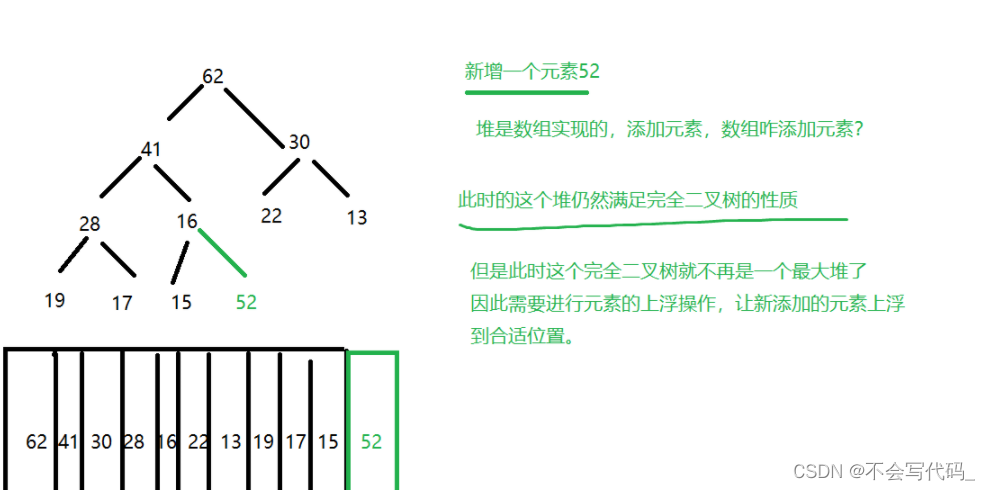
新增元素的变化过程:
对应代码:
易错点提示:1.动态数组获取元素只能调用方法,不能简单的data[索引值]
2.交换元素也不能使用交换三连,而是调用方法
//添加元素siftUp
public void add(int val){
//动态数组add方法默认是尾插法
data.add(val);
size++;
//添加完元素进行上浮操作
siftUp(size-1);
}
private void siftUp(int i) {
//上浮操作的两个终止条件
//1.已上浮到根节点的位置
//2.当前索引的节点值大于当前索引的父节点值
while(i>0&& data.get(i) > data.get(parent(i))){
swap(i,parent(i));
i=parent(i);
}
}
//交换元素
private void swap(int i, int parent) {
int child=data.get(i);
int parentVal=data.get(parent);
data.set(i,parentVal);
data.set(parent,child);
}
总结:

3.2 最大堆获取最大值
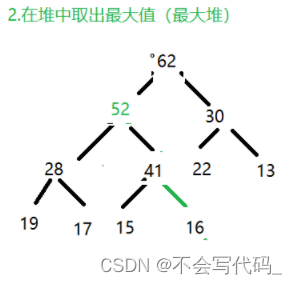

核心思路:

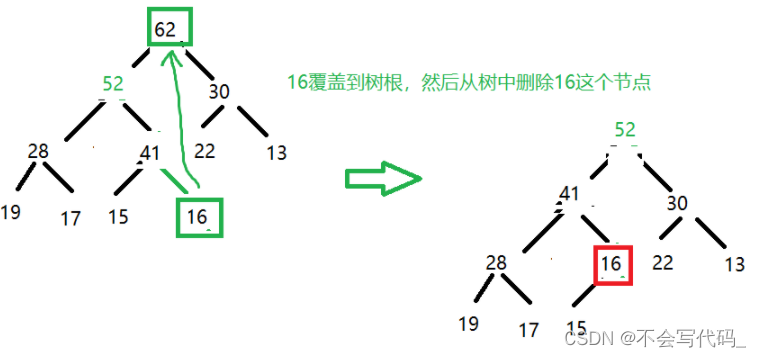

/**
* 取出堆中最大值
* */
public int extractMax(){
if(size==0){
throw new NoSuchElementException("heap is empty!");
}
//取出最大值,根节点
int max=data.get(0);
//将数组末尾顶到堆顶
data.set(0, data.get(size-1));
//删除堆中末尾元素
data.remove(size-1);
size--;
//将末尾元素进行下沉操作
siftDown(0);
return max;
}
private void siftDown(int i) {
//判断是否存在左子树
while(leftChild(i)<size){
int j=leftChild(i);
//此时存在右子树,且值比左子树大
if(j+1<size&&data.get(j+1)>data.get(j)){
j++;
}
//此时索引位置一定对应左右子树最大值的索引
if(data.get(i)>= data.get(j)){
//当前元素大于左右子树最大值,元素下沉结束
break;
}else{
swap(i,j);
i=j;
}
}
}
//交换元素
private void swap(int i, int parent) {
int child=data.get(i);
int parentVal=data.get(parent);
data.set(i,parentVal);
data.set(parent,child);
}
3.3 堆化 heapify(重点掌握思想)

第一种方法:构建一个新的最大堆,直接调用最大堆的add方法
时间复杂度为:nlogn,n代表遍历原数组,logn代表在二叉树中添加元素
空间复杂度为:O(n),因为开辟了新的空间

第二种方法:原地堆化
核心思想:从最后一个非叶子节点开始进行siftDown操作
原因依次从最后一棵子树开始调整为最大堆的子最大堆
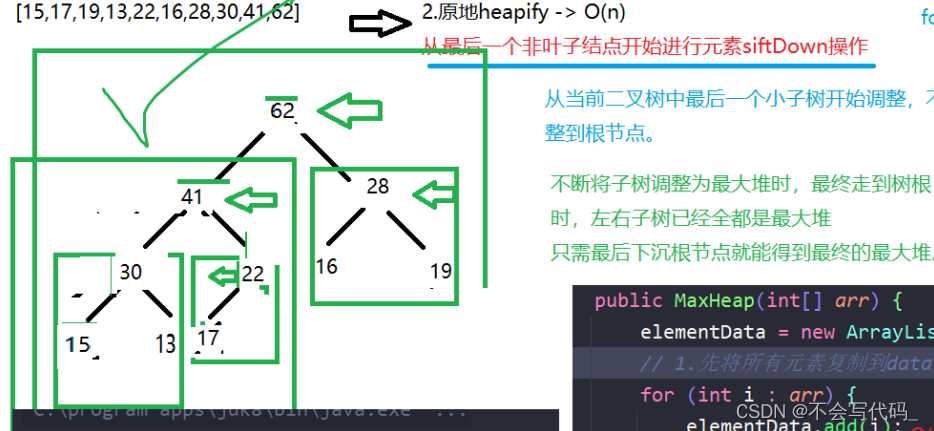
注意事项:自底向上建堆是一个时间复杂度近似O(n)的方法

//原地堆化
public MaxHeap(int[] arr){
//将所有元素复制到data
data=new ArrayList<>(arr.length);
for (int i:arr){
data.add(i);
size++;
}
//从最后一个非叶子节点进行下沉操作
//没有parent方法就(size-1-1)/2
for (int i = parent(size-1); i >=0 ; i--) {
siftDown(i);
}
}
3.3 拓展:java对象比较方法
java大小关系比较:

comparaTo接口弊端
每次根据需求就必须更改源代码,因为不同场景下大小关系是不确定的

comparator接口
每次不同的需求就创建关于这个类的不同的比较器,实现不同的需求

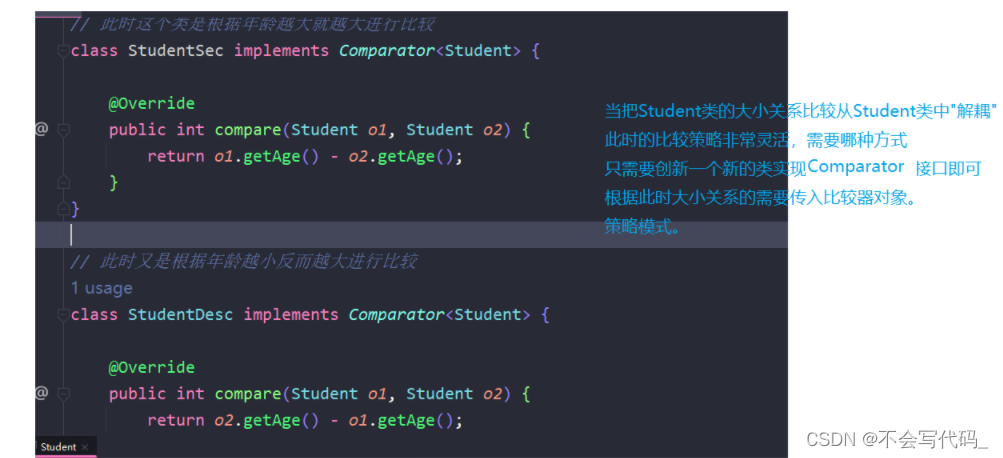
核心思想:不碰原来写过的代码,需要怎么比较就新创建一个类,一个类就是一种比较方法。对其它比较方法不影响
//这个类是根据年龄越大就越大进行比较
class StudentSec implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o1.getAge()-o2.getAge();
}
}
//这个类是根据是年龄越大反而越小的类
class StudentDesc implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o2.getAge()-o1.getAge();
}
}
public class Student {
private int age;
private String name;
public int getAge() {
return age;
}
public Student(int age) {
this.age = age;
}
public Student(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
public static void main(String[] args) {
Student[] students=new Student[]{
new Student(19,"may"),
new Student(20,"rose"),
new Student(21,"jack")
};
//得到一个按年龄升序数组
//student这个类不具备可比较的能力,传入比较器
Arrays.sort(students,new StudentSec());
System.out.println(Arrays.toString(students));
//按年龄降序的数组
Arrays.sort(students,new StudentDesc());
System.out.println(Arrays.toString(students));
}
}
四、基于堆的优先级队列的应用
4.1TopK问题(重点掌握)
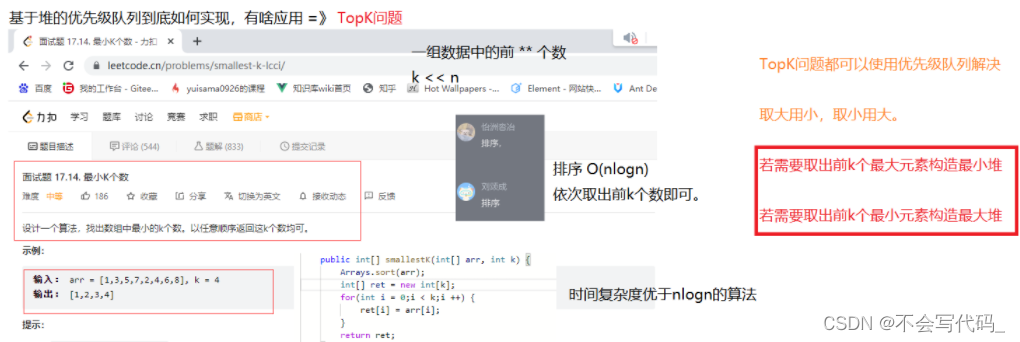
第一种方法的时间复杂度是nlogn:仅供参考,不推荐使用
//时间复杂度为nlogn的算法
public int[] smallestTop4(int[] data,int k){
Arrays.sort(data);
int[] ret=new int[k];
for (int i = 0; i < k; i++) {
ret[i]=data[i];
}
return ret;
}
第二种方法时间复杂度近似O(n)但还是nlogk(重点掌握):

注意事项:1.边界条件有两个,一个判断数组为空,还有一个判断k==0
2.jdk默认的优先级队列是最小堆,要传入比较器对象变成最大堆
/**
* 最小k个数
* @author hide_on_bush
* @date 2022/5/22
*/
public class Num17_14SmallestK {
public int[] smallestK(int[] arr, int k) {
int[] ret = new int[k];
//边界条件别忘记k=0
if(arr.length==0||k==0){
return ret;
}
//内部类传入一个比较器对象,因为JDK默认最小堆
//传入比较器后默认值越大反而越小排在队列之前
Queue<Integer> queue=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
//遍历数组集合
for (int i = 0; i < arr.length; i++) {
if(queue.size()<k){
queue.offer(arr[i]);
}else{
int max=queue.peek();
if(arr[i]<max){
queue.poll();
queue.offer(arr[i]);
}
}
}
int i=0;
while(!queue.isEmpty()){
ret[i++]=queue.poll();
}
return ret;
}
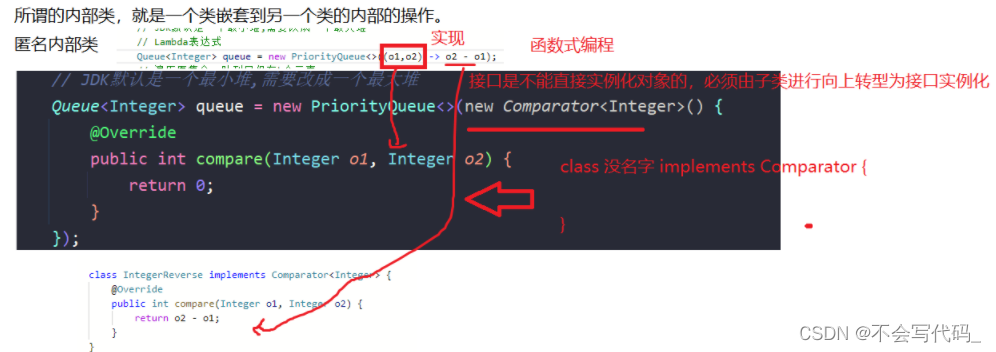
拓展:内部类(匿名内部类)
实际上就是 class 无引用名称=new 接口(向上转型)
4.2 leetcode347号问题
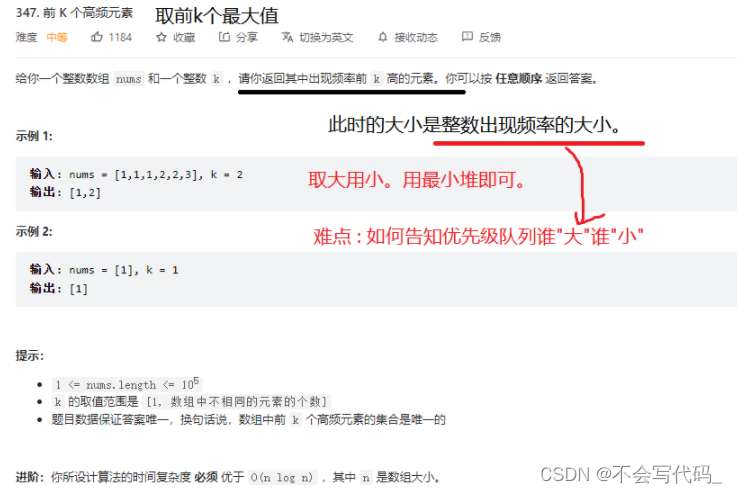
难点:

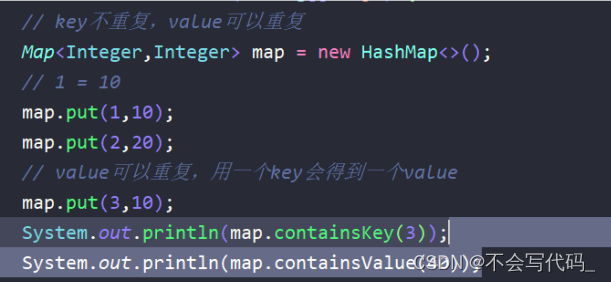
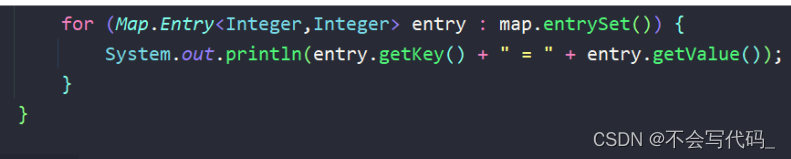
补充支持:Map集合遍历方法

核心思路:
1.原数组扫描,将出现的元素和元素出现的频次保存到map集合
2.再扫描Map集合,将结果放入优先级队列中(最小堆)
3.遍历队列,将最大频次结果依次出队
几个关键点:
1.使用map是为了方便记录键值对
2.使用自定义类是为了方便保存在队列中
/**
* @author hide_on_bush
* @date 2022/6/27
*/
//在优先级队列中添加该元素对象即可
class Freq implements Comparable<Freq>{
//数组出现的元素
int key;
//key出现的次数
int value;
public Freq(int key, int value) {
this.key = key;
this.value = value;
}
@Override
public int compareTo(Freq o) {
//谁出现的频次越大就越大
return this.value-o.value;
}
}
public class Num347_TopKK {
public int[] topKFrequent(int[] nums, int k) {
//返回的结果集
int[] data=new int[k];
//1.先扫描原数组,将出现元素保存到map集合,保存的是entry对象
Map<Integer,Integer> map=new HashMap<>();
for (int i:nums) {
if(map.containsKey(i)){
//此时元素i出现过,频次++
//获取该元素i出现的频次
int times=map.get(i);
map.put(i,times+1);
}else{
//第一次出现,将元素保存map集合,频次设置为1
map.put(i,1);
}
}
//2.遍历map集合,找出频次最高的k次个元素保存到优先级队列中
Queue<Freq> queue=new PriorityQueue<>();
for(Map.Entry<Integer,Integer> entry:map.entrySet()){
if(queue.size()<k){
queue.offer(new Freq(entry.getKey(),entry.getValue()));
}else{
//判断当前元素和堆顶元素出现的频次
//当前元素出现频次大于堆顶元素的频次,入队
Freq freq= queue.peek();
if(entry.getValue()> freq.value){
queue.poll();
queue.offer(new Freq(entry.getKey(), entry.getValue()));
}
}
}
//此时队列保存出现频次最高的k个元素
int index=0;
while (!queue.isEmpty()) {
data[index++] =queue.poll().key;
}
return data;
}
}
注意事项:每次出队或者入队需要Freq对象,而不是简单的把key或者value数值简单的输出
4.3leetcode373 最小对元素
添加链接描述
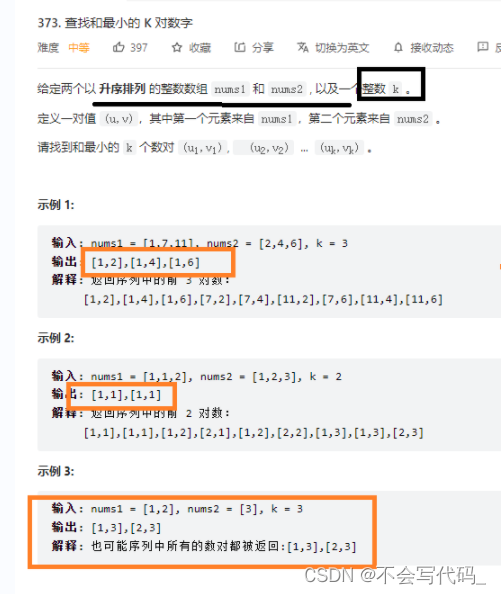
注意事项:1.优先级队列保存的还是一对数(最大堆)

2.循环终止条件:应该是k和数组长度两者的最小值,因为这是有序排序,最小值一定是在k之前或者数组长度之前(在谁之前看两者大小关系)



/**
* 和最小的k个数对 - 用最大堆
* @author yuisama
* @date 2022/05/18 19:39
**/
public class Num373_KSmallestPairs {
public List<List<Integer>> kSmallestPairs(int[] nums1, int[] nums2, int k) {
// 1.创建优先级队列,其中队列中保存Pair对象,传入比较器,和越小反而越大
Queue<Pair> queue = new PriorityQueue<>(new Comparator<Pair>() {
//最大堆,反而最上面的值越大
@Override
public int compare(Pair o1, Pair o2) {
return (o2.u + o2.v) - (o1.u + o1.v);
}
});
// 2.遍历两个数组,其中u来自第一个数组,v来自第二个数组
// 队列中保存了和最小的k个数对
for (int i = 0; i < Math.min(nums1.length,k); i++) {
for (int j = 0; j < Math.min(nums2.length,k); j++) {
if (queue.size() < k) {
queue.offer(new Pair(nums1[i],nums2[j]));
}else {
int add = nums1[i] + nums2[j];
Pair pair = queue.peek();
if (add < (pair.u + pair.v)) {
queue.poll();
queue.offer(new Pair(nums1[i],nums2[j]));
}
}
}
}
// 3.此时队列中就保存了和最小的前k个Pair对象,取出其中u和v即可
List<List<Integer>> ret = new ArrayList<>();
while (!queue.isEmpty()) {
List<Integer> temp = new ArrayList<>();
Pair pair = queue.poll();
temp.add(pair.u);
temp.add(pair.v);
ret.add(temp);
}
return ret;
}
}
//保存在优先级队列中的对象
class Pair {
// 来自数组1
int u;
// 来自数组2
int v;
public Pair(int u, int v) {
this.u = u;
this.v = v;
}
}
4.5原地堆排序
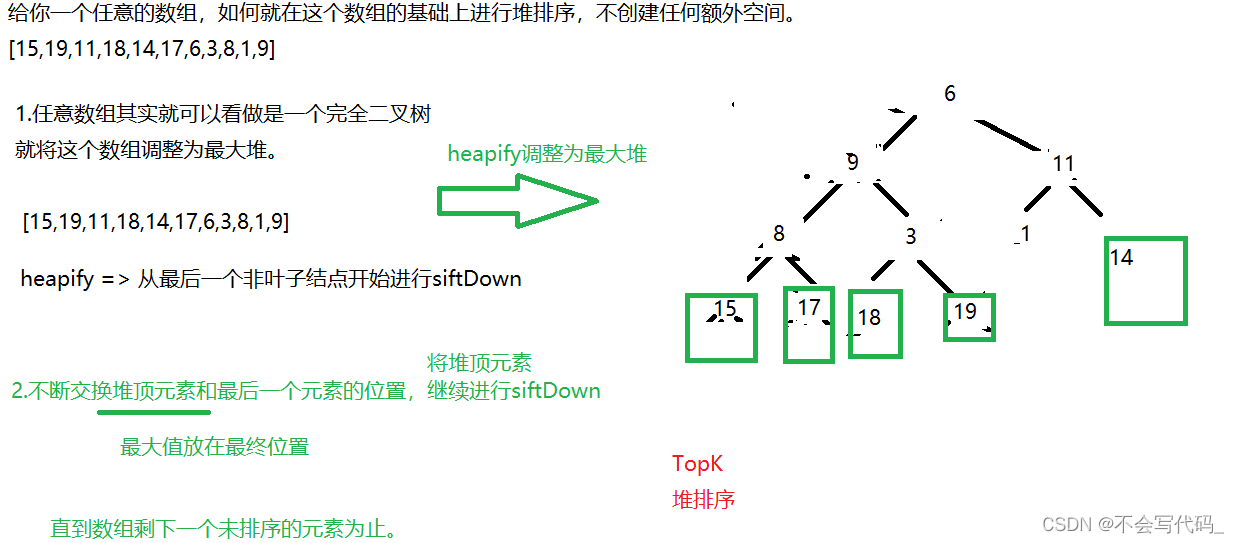
不使用最小堆的原因:层次的深度和大小无关,最小堆按编号顺序不一定是升序
/**
* 七大排序
* @author yuisama
* @date 2022/05/18 20:21
**/
public class SevenSort {
public static void main(String[] args) {
int[] arr = {19,27,13,22,3,1,6,5,4,2,110,65,70,98,72};
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
// 原地堆排序
public static void heapSort(int[] arr) {
// 1.先将任意数组进行heapify调整为最大堆
for (int i = (arr.length - 1 - 1) / 2; i >= 0; i--) {
siftDown(arr,i,arr.length);
}
// 2.不断交换堆顶元素到数组末尾,每交换一个元素,就有一个元素落在了最终位置
for (int i = arr.length - 1; i > 0; i--) {
// arr[i] 就是未排序数组的最大值,交换末尾
swap(arr,0,i);
siftDown(arr,0,i);
}
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 元素下沉操作
* @param arr
* @param i 下沉的索引
* @param length 数组的长度
*/
private static void siftDown(int[] arr, int i, int length) {
while (2 * i + 1 < length) {
int j = 2 * i + 1;
if (j + 1 < length && arr[j + 1] > arr[j]) {
j = j + 1;
}
if (arr[i] >arr[j]) {
break;
}else {
swap(arr,i,j);
i = j;
}
}
}
}















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









