






1.目的:自回归系统隐式地模拟了持续时间,但在鲁棒性和持续时间可控性方面存在某些不足。非自回归系统在训练过程中需要文本和语音之间的显式对齐信息,并预测语言单元(如phone)的持续时间,这可能会损害它们的自然性,因此提出GCT,一种完全非自回归TTS模型,消除了对文本和语音监控之间显式对齐信息以及phone级持续时间预测的需求
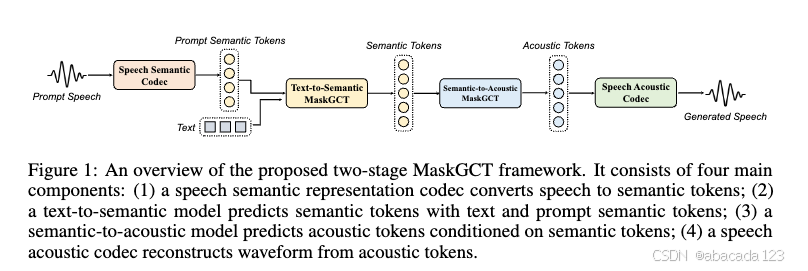
2.模型:两阶段模型
1)text-to-semantic (T2S) mode:使用text token 和speech token作为前缀,用icl来预测mask的语义token:文本来预测从语音自监督学习中提取的语义标记
2)semantic-to-acoustic (S2A) mode:使用语义token预测基于rvq产生的带prompt的mask的声学token
3)训练:MaskGCT学会根据给定的条件和prompt预测被掩盖的语义或声学标记;推理:模型以并行模式生成指定长度的token


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









