







一共分为以下几步:
1. 删除/etc/kubernetes/文件夹下的所有文件
2. 删除$HOME/.kube文件夹
3. 删除/var/lib/etcd文件夹
3. 删除/var/lib/etcd文件夹
rm -rf /etc/kubernetes/* rm -rf ~/.kube/* rm -rf /var/lib/etcd/*
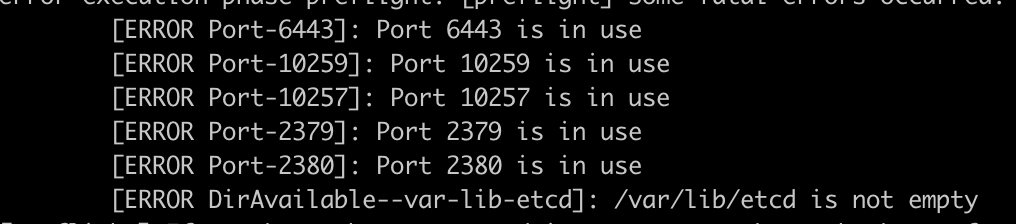
4. 停用端口号, 把下面的这些端口号都停用就ok
lsof -i:6443|grep -v "PID"|awk '{print "kill -9",$2}'|sh
lsof -i:10259|grep -v "PID"|awk '{print "kill -9",$2}'|sh
lsof -i:10257|grep -v "PID"|awk '{print "kill -9",$2}'|sh
lsof -i:2379|grep -v "PID"|awk '{print "kill -9",$2}'|sh
lsof -i:2380|grep -v "PID"|awk '{print "kill -9",$2}'|sh
lsof -i:10250|grep -v "PID"|awk '{print "kill -9",$2}'|sh
















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









