







Precondition
$ kubectl create ns gpu-operator
$ kubectl label --overwrite ns gpu-operator pod-security.kubernetes.io/enforce=privileged- Add the NVIDIA Helm repository:
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update- Install the Operator and specify configuration options:
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set <option-name>=<option-value>Pre-Installed NVIDIA Container Toolkit (but no drivers)
In this scenario, the NVIDIA Container Toolkit is already installed on the worker nodes that have GPUs.
- Configure toolkit to use the
rootdirectory of the driver installation as/run/nvidia/driver, because this is the path mounted by driver container.
$ sudo apt -y install nvidia-container-toolkit
$ nvidia-ctk runtime configure --runtime=crio
$ sudo sed -i 's/^#root/root/' /etc/nvidia-container-runtime/config.toml
$ sudo systemctl restart containerd kubelet- Install the Operator with the following options (which will provision a driver):
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set toolkit.enabled=falseIf the k8s node is not clean, go to Step 2
To disable operands from getting deployed on a GPU worker node, label the node with nvidia.com/gpu.deploy.operands=false.
$ kubectl label nodes $NODE nvidia.com/gpu.deploy.operands=false --overwrite
# Continue...
$ kubectl label nodes $NODE nvidia.com/gpu.deploy.operands=true --overwriteEmphasis !Emphasis !Emphasis !
Before label "nvidia.com/gpu.deploy.operands=true", to be install NVIDIADriver CRD
One Driver Type and Version on All Nodes
- Optional: Remove previously applied node labels.
- Create a file, such as
nvd-all.yaml, with contents like the following:
apiVersion: nvidia.com/v1alpha1
kind: NVIDIADriver
metadata:
name: demo-all
spec:
driverType: gpu
image: driver
imagePullPolicy: IfNotPresent
imagePullSecrets: []
manager: {}
rdma:
enabled: false
useHostMofed: false
gds:
enabled: false
repository: nvcr.io/nvidia
startupProbe:
failureThreshold: 120
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 60
usePrecompiled: false
version: 535.104.12Tip Because the manifest does not include a nodeSelector field, the driver custom resource selects all nodes in the cluster that have an NVIDIA GPU.
- Apply the manfiest:
$ kubectl apply -n gpu-operator -f nvd-all.yaml
Upgrading the NVIDIA GPU Operator
- Specify the Operator release tag in an environment variable:
$ export RELEASE_TAG=v23.9.2- Fetch the values from the chart:
$ helm show values nvidia/gpu-operator --version=$RELEASE_TAG > values-$RELEASE_TAG.yaml- Update the values file as needed.
- Upgrade the Operator:
$ helm upgrade $(helm ls -n gpu-operator | awk '{print $1}' | tail -n +2) nvidia/gpu-operator -n gpu-operator -f values-$RELEASE_TAG.yaml- Disabled auto_upgrade policy
# driver.upgradePolicy.autoUpgrade: falseExample Output
Release "gpu-operator" has been upgraded. Happy Helming!
NAME: gpu-operator
LAST DEPLOYED: Thu Apr 20 15:05:52 2023
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 2
TEST SUITE: NoneAbout Upgrading the GPU Driver
NVIDIA GPU Driver Custom Resource Definition — NVIDIA GPU Operator 24.3.0 documentation
- Optional: If you want to run more than one driver type or version in the cluster, label the worker nodes to identify the driver type and version to install on each node:Example
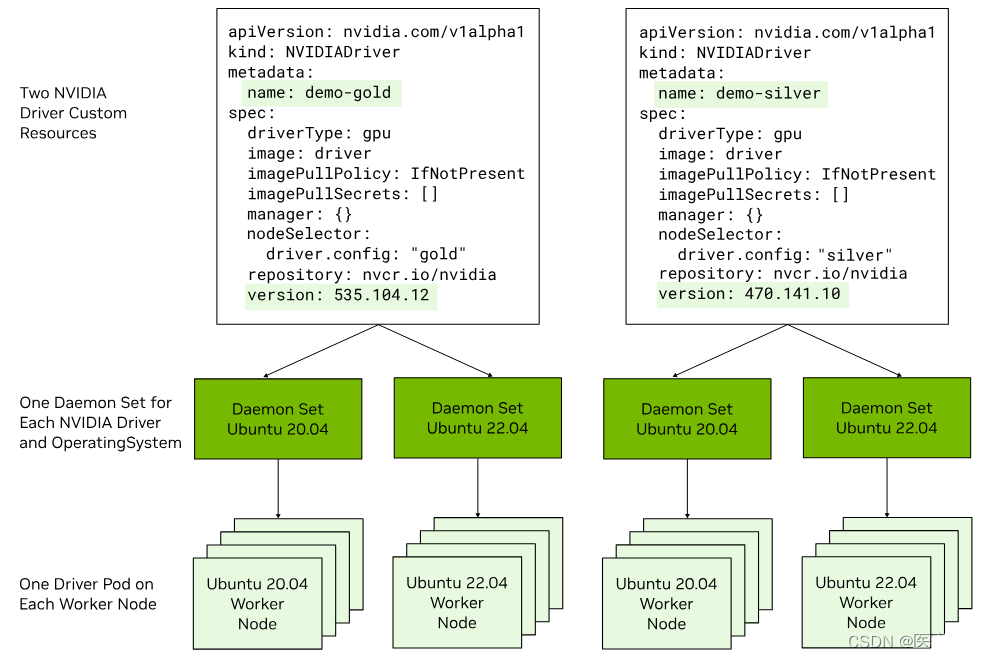
$ kubectl label node <node-name> --overwrite driver.version=525.125.06
- To use a mix of driver types, such as vGPU, label nodes for the driver type.
- To use a mix of driver versions, label the nodes for the different versions.
- To use a mix of conventional drivers and precompiled driver containers, label the nodes for the different types.<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1480
1480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











