







 本文介绍了Linux中的awk命令,它作为一种强大的文本格式化工具,支持条件判断、数组和循环。文章详细讲解了awk的语法、参数设置、生命周期、预定义变量、执行流程,包括BEGIN和END模式的使用,并通过实例演示了如何利用awk进行文本处理和打印操作。此外,还提到了awk中的函数和不同类型的表达式,如正则表达式和比较表达式。
本文介绍了Linux中的awk命令,它作为一种强大的文本格式化工具,支持条件判断、数组和循环。文章详细讲解了awk的语法、参数设置、生命周期、预定义变量、执行流程,包括BEGIN和END模式的使用,并通过实例演示了如何利用awk进行文本处理和打印操作。此外,还提到了awk中的函数和不同类型的表达式,如正则表达式和比较表达式。
awk是一种报告生成器,拥有强大的文本格式化能力
我们可以用awk命令将文本整理成我们想要的样子,比如把一些文本整理成“表的样子”然后在展示出来,也就是“文本格式化的能力”
awk支持条件判断,数组,循环等功能,所以我们把awk理解成一门脚本语言解释器
1.awk语法:awk 参数 处理规则 操作对象
2.参数:
-F:指定文本分隔符(默认是以空格作为分隔符)
案例:取出最后一串字符
awk '{print $NF}' 9.ttx

案例二:指定‘f’字符为分隔符

3.awk的生命周期
grep,sed,awk他们的生命周期都是独一行处理一行,直到处理完成。
1.接受一行作为输入
2.把刚刚读入进来的文本进行分解
3.使用处理规则处理文本
4.输入一行,赋值给$0,直到处理完成
5.把处理完成之后所有的数据交给END{}来再次处理
4.awk中的预定义变量
$0:代表当前行
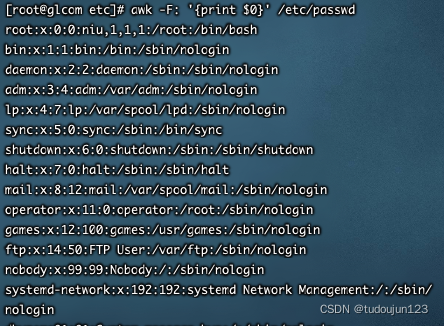
打印当前行
$N:代表第n列
eg:打印/etc/passwd中的第2列

NF:记录当前行的字段数,或者分割的段数

NR:用来记录行号,不是内部文本的行号,只是相当于索引
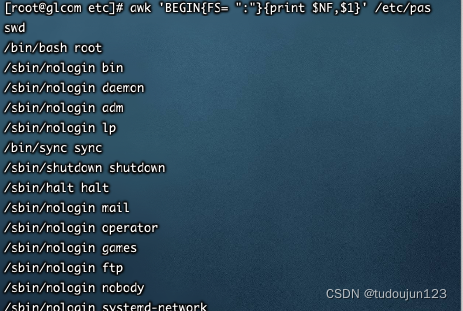
FS:指定分割符,默认是空格,fs的优先级高于-f
eg:以:为分隔符,就行分割
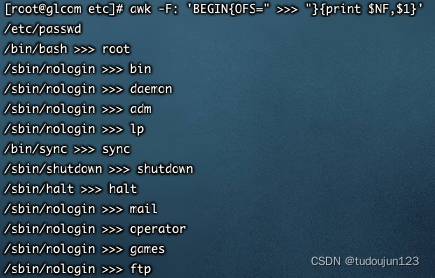
OFS:指定打印分隔符
5.awk执行流程
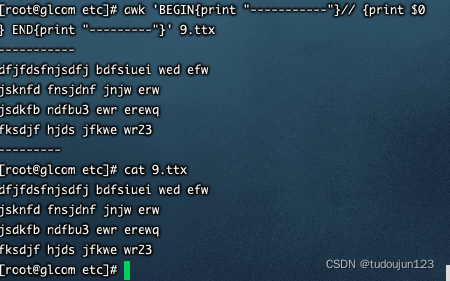
BEGIN{}:第一步执行
//:下一步
{}:循环
END{}:最后执行
可随意搭配,没有强制要求怎么搭配,执行顺序如上
AWK 包含两种特殊的模式:BEGIN 和 END。
BEGIN 模式指定了处理文本之前需要执行的操作:
END 模式指定了处理完所有行之后所需要执行的操作:
什么意思呢?光说不练不容易理解,我们来看一些小例子,先从BEGIN模式开始,示例如下
上述写法表示,在开始处理test文件中的文本之前,先执行打印动作,输出的内容为"aaa","bbb".
也就是说,上述示例中,虽然指定了test文件作为输入源,但是在开始处理test文本之前,需要先执行BEGIN模式指定的"打印"操作
既然还没有开始逐行处理test文件中的文本,那么是不是根本就不需要指定test文件呢,我们来试试。
经过实验发现,还真是,我们并没有给定任何输入来源,awk就直接输出信息了,因为,BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作,而上述示例没有给定任何输入源,但是awk还是会先执行BEGIN模式指定的"打印"动作,打印完成后,发现并没有文本可以处理,于是就只完成了"打印 aaa bbb"的操作。
这个时候,如果我们想要awk先执行BEGIN模式指定的动作,再根据执我们自定义的动作去操作文本,该怎么办呢?示例如下

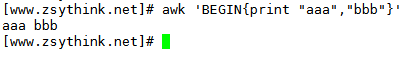
6.awk中的函数
print:打印
printf: 格式化打印
7.awk中的定位
正则表达式
比较表达式
要求打印属组ID大于属主ID的行
逻辑表达式
算术表达式
范围表达式


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









