






nfgen的修改
工欲善其事,必先利其器。
最近在做nfdump-nfcapd的测试,需要以网卡线速度(10Gbit/s)发netflow的UDP数据包,需要支持netflow v5、v9,最好能自己设置速率。然而网上Linux环境的netflow生成器不是花里胡哨达不到线速度,就是只支持netflow v9,导致测试的时候很是憋屈。
这天看着开源工具nfgen的代码陷入沉思:这不就是在发固定的报文吗?我自己修改一下不就好了。
nfgen代码分析
程序以C++实现,代码其实也就几百行,不如在分析的同时也精进一下对各种概念的理解。
代码之外的
在看代码之前,先看看代码之外的东西,保持好奇:
CMake
首先是CMakeLists.txt,内容如下;
cmake_minimum_required(VERSION 2.8)
project(nfgen)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_FLAGS -pthread)
add_executable(nfgen main.cpp Worker.cpp Worker.h Timer.cpp Timer.h)
在执行完cmake CMakeLists.txt后,多出了CMakeFiles文件夹、CMakeCache.txt、cmake_install.cmake和Makefile几个文件。
第一个疑问就是:为什么不直接用Makefile,cmake不会多此一举吗?我的xdp-learning就是直接用Makefile,只不过都是C,所以,cmake是什么?之前编译记得总在用。
Googling…
CMake,全称Cross platform Make,是“一个开源的跨平台自动化建构系统”,它并不直接建构出最终的软件,而是产生标准的“建构档”,如Unix的Makefile,然后再根据后续的建构方式去建构软件。配置文件CMakeLists.txt(学名叫组态档)之于CMake,就如 Makefile之于Make。
所以,CMake不如叫做“建构档生成器”,通过平台无关的CMakeLists.txt、用户的平台生成本地化的Makefile文件(或者其他名称的建构档),做到“Write once, run everywhere”,解决了跨平台、Makefile编写麻烦等问题。
Linux下使用CMake的一般流程:
- 编写CMakeLists.txt;
- 执行
cmake PATH或ccmake PATH,PATH为CMakeLists.txt所在目录,当然直接指定CMakeLists.txt也是可以的; - 根据生成的Makefile再make;
一般是把CMakeLists.txt放在工程目录下,使用时先创建一个build文件夹,好存放CMake生成的中间文件。
……
暂时就知道这么多吧;后面遇到了再看。
代码风格
初看代码第一个注意到的是有些变量会在前/后加上下划线,查了查是C++的代码风格,表示是私有成员变量,Google开源项目风格指南里面也是这样的。
代码风格这个问题之前在紫金山做实习项目的时候就了解过了,当时的Vue项目甚至做了一个代码风格检查器,每次编译项目不符合代码风格会报错。
看了看阿里、腾讯、字节跳动的代码,似乎也有类似的代码风格,多学习吧。
mutex
应为mutual exclusion,互斥量。是C++标准库里面的一个类,定义在<mutex>头文件中
设想A和B两个人都想上厕所,然而厕所只有一间。在厕所没有门和锁的时候,两个人都随时可以进去,也许真人会说一声不好意思就退出来等待,但如果是没有感情的线程可就不一样了。因此厕所加上了门锁,A和B任一人先进去以后就能锁上门,另一人必须等待门锁打开才能进去。现在把两个人想象成两个线程,把厕所换成线程要它们修改的同一数据,这个门锁就是mutex的作用——在多个线程访问同一数据时防止冲突,这个厕所就叫临界域(critical region)。
show me the code:
下面是参考网上资料写的简单的程序,my_money会被t1和t2两个线程修改;
#include <iostream>
#include <thread>
using namespace std;
int my_money = 0;
void addMoney(int money) {
for (int i = 0; i < money; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
my_money++;
}
}
int main() {
std::thread t1(addMoney, 10000);
std::thread t2(addMoney, 10000);
t1.join();
t2.join();
cout << my_money << endl;
return 0;
}
如果没有多线程编程经验,结果想当然应该是两万,但是实际运行结果是小于两万的,也可以自行尝试一下。
我的钱呢?
自增操作my_money++并不是原子操作,而是多条汇编指令完成的,我们通过反汇编拿到汇编码:
my_money++;
73e: 8b 05 d0 08 20 00 mov 0x2008d0(%rip),%eax # 201014 <my_money>
744: 83 c0 01 add $0x1,%eax
747: 89 05 c7 08 20 00 mov %eax,0x2008c7(%rip) # 201014 <my_money>
可以看到,自增操作首先将my_money的值赋给%eax累加寄存器,再将%eax加1,最后将%eax的值赋给my_money;
可是,为什么两次(%rip)寻址不一样啊?问题不断……
既然两个线程一起在进行my_money的自增,便有机会出现两者一起读取my_money(如100),寄存器加1以后再赋给my_money都是101,但我们期待的结果是102。而我们又在每次线程自增前休眠了1毫秒,使得这种情况更易发生,从而出现错误。
这时候就需要用到mutex:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
int my_money = 0;
std::mutex mtx;
void addMoney(int money) {
for (int i = 0; i < money; i++) {
mtx.lock();
std::this_thread::sleep_for(std::chrono::milliseconds(1));
my_money++;
mtx.unlock();
}
}
int main() {
std::thread t1(addMoney, 10000);
std::thread t2(addMoney, 10000);
t1.join();
t2.join();
cout << my_money << endl;
return 0;
}
mutex中还有多种类,可以完成一些更复杂的功能,后续有需要继续探索吧。以及等一个mutex的原理解释。
atomic
C++的原子类型,需要头文件<automic>;
避免多线程冲突的;和mutex机制一样吗?——不太一样。
首先说结果:在多线程情况下,且临界区操作不复杂时,如单个基础数据,尽量使用原子操作来代替锁机制以提高效率;当需要对复杂代码块进行数据安全保护的时候,则使用mutex锁机制。
直接代码比较一下两种机制,在Ubuntu虚拟机上跑的:
/*********************************************************************************
* atomic
*/
#include <iostream>
#include <thread>
#include <atomic>
#include <time.h>
using namespace std;
std::atomic_int my_money(0);
void addMoney(int money) {
for (int i = 0; i < money; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
my_money++;
}
}
int main() {
clock_t start,end;
start = clock();
std::thread t1(addMoney, 10000);
std::thread t2(addMoney, 10000);
t1.join();
t2.join();
cout << my_money << endl;
end = clock();
cout << "atomic time spent: " << (double)(end-start) / CLOCKS_PER_SEC << " s" << endl;
return 0;
}
/*********************************************************************************
* mutex
*/
#include <iostream>
#include <thread>
#include <mutex>
#include <time.h>
using namespace std;
int my_money = 0;
std::mutex mtx;
void addMoney(int money) {
for (int i = 0; i < money; i++) {
mtx.lock();
std::this_thread::sleep_for(std::chrono::milliseconds(1));
my_money++;
mtx.unlock();
}
}
int main() {
clock_t start,end;
start = clock();
std::thread t1(addMoney, 10000);
std::thread t2(addMoney, 10000);
t1.join();
t2.join();
cout << my_money << endl;
end = clock();
cout << "mutex time spent:" << (double)(end-start) / CLOCKS_PER_SEC << endl;
return 0;
}
两种执行结果:
wp@ubuntu:~/Documents/test$ ./mutex_test
20000
Time spent:38.7539 s
wp@ubuntu:~/Documents/test$ ./atomic_test
20000
Time spent:19.1301 s
上代码
虽然代码量很小,但也先把握总体架构:
关键类:Worker和Timer
关键类
Worker
class Worker {
public:
Worker();
Worker(char *dest, u_short port, mutex *mtx, atomic_ulong *requests);
void Run();
private:
char *dest_;
u_short port_;
std::mutex *mtx_;
std::atomic_ulong *requests_;
void safe_cout(const string &msg);
};
void Worker::Run() {
int sd;
struct sockaddr_in addr{};
if ((sd = socket(AF_INET, SOCK_DGRAM, 0)) < 0) {
safe_cout("Error: Creating socket.");
exit(EXIT_FAILURE);
}
addr.sin_family = AF_INET;
addr.sin_port = htons ((short) (size_t) port_);
addr.sin_addr.s_addr = inet_addr(dest_);
while (true) {
if (sendto(sd, &cflow_cap, sizeof(cflow_cap), 0,
(struct sockaddr *) &addr, sizeof(addr)) < 0) {
safe_cout("Error: Sent failed.");
exit(EXIT_FAILURE);
}
// cout << "1234567890" << endl; // 回答为什么需要safe_cout
requests_->fetch_add(1);
}
close(sd);
}
void Worker::safe_cout(const string &msg) {
lock_guard<mutex> lock(*mtx_); // lock_guard会加锁,在超出其作用域时进行unlock,也就是运行完safe_out以后,所以这里不加锁会导致出错时输出错乱?可是临界域是哪里?哪里会发生线程冲突?是指多个线程同时cout到terminal吗?try?——确实
cout << msg;
}
/* 构造函数还能这么写的吗 */
Worker::Worker(char *dest, u_short port, mutex *mtx, atomic_ulong *requests) : dest_(dest), port_(port),
mtx_(mtx), requests_(requests) {}
给自己提问:
- mutex是做什么用的?目测是开多进程运行Run,让这多个Run进程共享某个资源?什么资源?
见mutex。
回到本文,nfgen中mutex的唯一用处就是在Worker中的safe_cout,如此又到了这个问题:为什么要safe_cout。 std::不是用了using namespace std就可以不加了吗?
确实删了也不影响,但查了一下还真有一些冲突问题:
比如C++17添加了一种新类型std::byte,而Windows头文件里自带一种类型byte,本身是不冲突的,但是一旦用了using namespace std,以前的代码很多都会发生命名冲突。此外还有其他冲突问题,总之在头文件里面就尽量别用吧,在cpp源文件里面用倒是不影响。- atomic_ulong是什么?还有为什么它满篇都是ulong这种,是C++自带的简写吗?
u_long看起来是linux头文件里面的东西,至于atomic_ulong,是C++的atomic相关的东西。即所谓“原子类型”,具体作用是访问不会导致数据的竞争,还是和多线程相关的东西。 - 为什么需要
safe_cout?
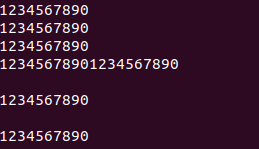
之前一直觉得临界域只是对某变量写入出现冲突,这里的临界域可以说是多个线程同时对terminal进行cout发生冲突,cout也不是原子操作——他们可能写到一起;在上面注释掉的cout << "1234567890" << endl;一句,就是不加锁的后果,执行时会发现线程打印冲突:
- 第二个带参构造函数,还能这么写?
这是C++的一种特性,后面跟初始化成员列表,但还是不太清楚该什么时候用,以及这么写有没有什么额外问题;至少看起来效率很高,还省LOC;
Timer
class Timer {
public:
explicit Timer(std::atomic_ulong *requests);
void Start();
private:
std::atomic_ulong *requests_;
string get_iso8601_timestamp();
};
程序流程:指定线程数量,开多线程跑Worker的Run函数;开Timer线程对发送的请求进行计数,每1秒在终端显示;
大体流程结构就这么简单,还有一个run workers不知道是做什么的。
入口很明显的情况下就直接看入口函数吧?main:
但又感觉应该先看关键结构体?或者并行?还是程序太简单了。
#include <iostream>
#include <thread>
#include "Worker.h"
#include "Timer.h"
using namespace std;
u_int _NUM_THREADS = 3; // 下划线
u_short _NF_PORT = 9995;
int main(int argc, char *argv[]) {
u_int num_threads_ = _NUM_THREADS;
u_short port_ = _NF_PORT;
char *dest_;
mutex mtx_;
atomic_ulong requests_(0);
// handle options
if (argc < 2) {
cout << "Usage: " << argv[0] << " [-t num_threads (" << _NUM_THREADS << ")] [-p port (" << _NF_PORT
<< ")] target_ip" << endl;
return -1;
}
int opt;
char *endptr;
while ((opt = getopt(argc, argv, "t:p:")) != EOF) {
switch (opt) {
case 't':
num_threads_ = (u_int) strtol(optarg, &endptr, 0);
if (num_threads_ == 0) {
cout << "Invalid num_threads: " << endptr << endl;
return EXIT_FAILURE;
}
break;
case 'p':
port_ = (u_int) strtol(optarg, &endptr, 0);
if (port_ == 0) {
cout << "Invalid port: " << endptr << endl;
return EXIT_FAILURE;
}
break;
default:
cout << "Usage: " << argv[0] << " [-t num_threads (" << _NUM_THREADS << ")] [-p port (" << _NF_PORT
<< ")] target_ip" << endl;
return EXIT_FAILURE;
}
}
if (!argv[optind]) {
cout << "Error: destination missing" << endl;
return EXIT_FAILURE;
} else {
dest_ = argv[optind];
}
// create worker threads
thread *thWorker;
thWorker = new thread[num_threads_];
for (u_int i = 0; i < num_threads_; i++) {
thWorker[i] = thread(&Worker::Run, Worker(dest_, port_, &mtx_, &requests_));
}
// timer thread
cout << "Timestamp, Requests/s" << endl;
thread th_timer(&Timer::Start, Timer(&requests_));
// run workers
for (u_int i = 0; i < num_threads_; i++) {
thWorker[i].join();
}
return EXIT_SUCCESS;
}
转载请注明出处。


















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











