







这篇文章接介绍一种非常简单的监督学习算法:朴素贝叶斯。简单到根本不用构建分类器,只需要计算概率就行了。因为这个算法就是一个基本的概率公式推导出来的
公式的推导(周志华机器学习)


公式的推导(模式识别)

下面根据一个实例介绍
朴素贝叶斯如何用于文本分类

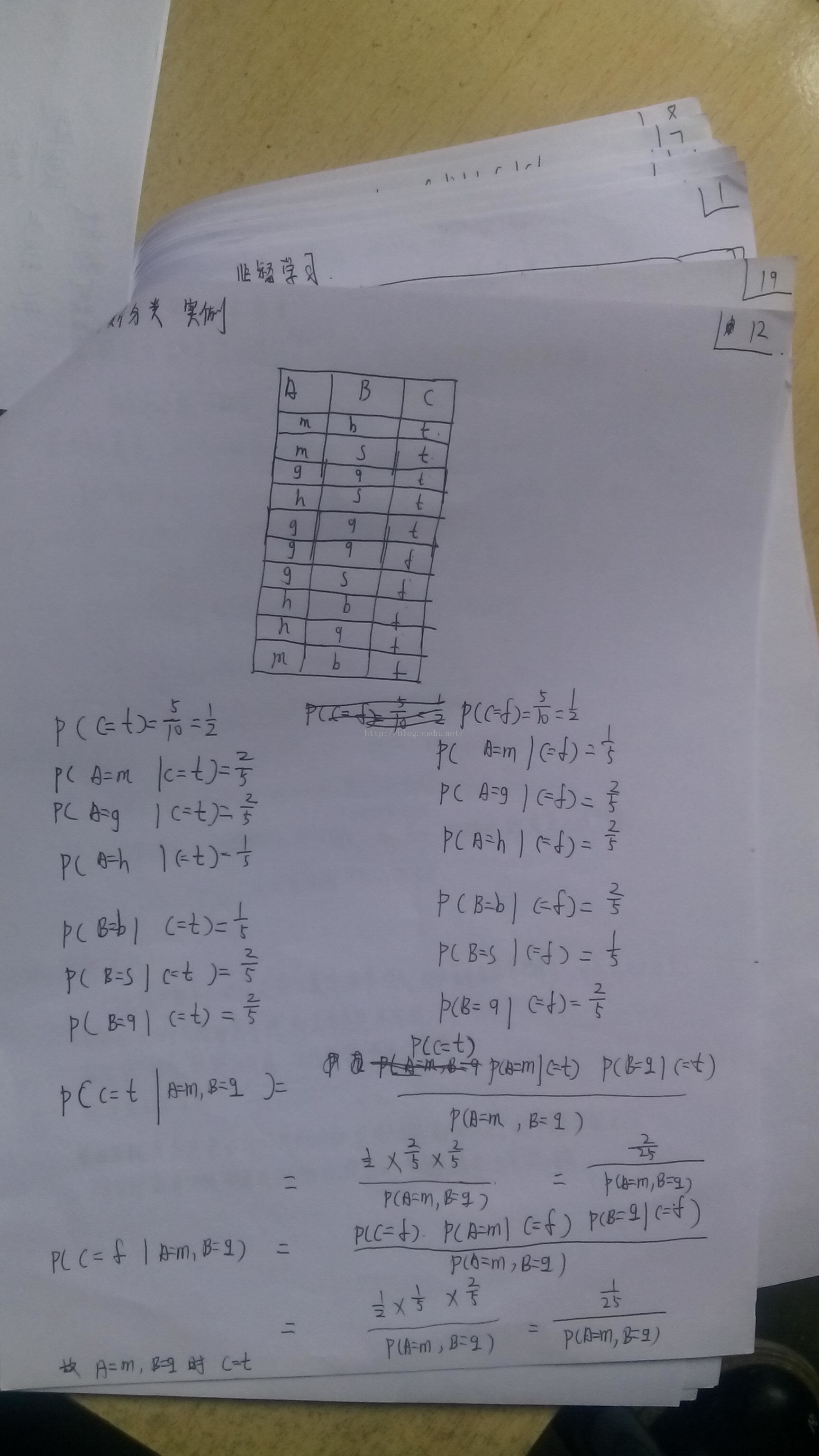
再来一个实例介绍

朴素贝叶斯数据
m b t
m s t
g q t
h s t
g q t
g q f
g s f
h b f
h q f
m b f朴素贝叶斯代码
#encoding=utf-8
raw_file=open("raw_data")
raw_list=raw_file.readlines()
map_list=[]#利用二维数组保存所有数据
predict_record=["m","q"]
for ele in raw_list:
list1=ele.strip().split(" ")
map_list.append(list1)
#三个字段分别有哪些值如C字段有 t和f
a_list=[]
a_set=()
b_list=[]
b_set=()
c_list=[]
c_set=()
for ele in map_list:
a_list.append(ele[0])
b_list.append(ele[1])
c_list.append(ele[2])
a_set=set(a_list)
b_set=set(b_list)
c_set=set(c_list)
#获取概率值 p(C=c1) p(C=c2)等
list_t=[]
list_f=[]
for ele in map_list:
if (ele[2]).strip() == "t":
list_t.append(ele)
if (ele[2]).strip() == "f":
list_f.append(ele)
pro_t= float(len(list_t)) / float(len(map_list))
pro_f= float(len(list_f)) / float(len(map_list))
#获取概率值 p(A=m | C=t) p(B=q | C=t) p(A=m | C=f) p(B=q | C=f)
list_mt=[]
list_qt=[]
list_mf=[]
list_qf=[]
for ele in list_t:
if ele[0] == predict_record[0] :
list_mt.append(ele)
if ele[1] == predict_record[1]:
list_qt.append(ele)
for ele in list_f:
if ele[0] == predict_record[0] :
list_mf.append(ele)
if ele[1] == predict_record[1]:
list_qf.append(ele)
pro_mt=float(len(list_mt)) / float(len(list_t))
pro_qt=float(len(list_qt)) / float(len(list_t))
pro_mf=float(len(list_mf)) / float(len(list_f))
pro_qf=float(len(list_qf)) / float(len(list_f))
#计算p(C=t | A=m,B=q) p(C=f | A=m,B=q)
pro_mq=1.0#由于p(A=m,B=q)不影响计算,所以设为常数1
pro_tmq= ( pro_t * pro_mt * pro_qt ) / pro_mq
pro_fmq= ( pro_f * pro_mf * pro_qf) / pro_mq
if pro_tmq > pro_fmq:
print "t\n"
elif pro_tmq < pro_fmq:
print "f\n"
elif pro_tmq == pro_fmq:
print "the probility is the same,choose another method"
else:
print "error"
朴素贝叶斯文本分类数据
1;Chinese Beijing Chinese;yes
2;Chinese Chinese Shanghai;yes
3;Chinese Macao;yes
4;Tokyo Japan Chinese;no朴素贝叶斯文本分类代码
#encoding=utf-8
list_sample=["Chinese","Chinese","Chinese","Tokyo","Japan"]#需要预测的文本
#读取源数据
raw_data=open("raw_data","r+")
list_raw=raw_data.readlines()
list_all=[]
set_all=()
list_yes=[]
list_yes_all_word=[]
list_no=[]
list_no_all_word=[]
#进行格式转换
for ele in list_raw:
list_id_words_tag=ele.split(";")
#print list1[0],":",list1[1],":",list1[2]
list_words=list_id_words_tag[1].strip().split(" ")
#获取所有文本中的所有单词
for word in list_words:
list_all.append(word)
#筛选出yes和no的文本
tag=list_id_words_tag[2].strip()
if tag == "yes":
list_yes.append(list_words)
if tag == "no":
list_no.append(list_words)
set_all=set(list_all)
#获取laplance平滑参数
#为防止分子出现0,分子加上laplance平滑系数L=1,为防止分母为0,分母加上所有文本中的不同的单词总数
yes_words_number=0
no_words_number=0
for ele in list_yes:
yes_words_number = yes_words_number + len(ele)
for ele in list_no:
no_words_number = no_words_number + len(ele)
L1=1
L2=len(set_all)
#统计sample中每个单词在yes和no中出现的次数
sample_word_yes_number_dict={}
sample_word_no_number_dict={}
for sample_word in list_sample:#sample中每个word,对于每个word,都要遍历list_yes 和 list_no
#初始化字典
sample_word_yes_number_dict[sample_word] = 0
sample_word_no_number_dict[sample_word] = 0
#sample中的每个单词在yes中出现的次数
for words in list_yes:#属于yes的文本
for word in words:#每个文本中的word
if word == sample_word:#如果该文本中的该单词与sample中的该单词一致,则该单词对应的数量 +1
sample_word_yes_number_dict[sample_word] = sample_word_yes_number_dict[sample_word] + 1
# sample中的每个单词在no中出现的次数
for words in list_no: # 属于no的文本
for word in words: # 每个文本中的word
if word == sample_word: # 如果该文本中的该单词与sample中的该单词一致,则该单词对应的数量 +1
sample_word_no_number_dict[sample_word] = sample_word_no_number_dict[sample_word] + 1
# for ele in sample_word_no_number_dict:
# print ele,sample_word_no_number_dict[ele]
#开始计算该文本分别属于yes和no的概率
pro_yes=1.0
pro_no=1.0
for word in list_sample:
#计算该文本属于yes的概率
yes_result1=float(sample_word_yes_number_dict[word] + L1)#分子
yes_result2=float( yes_words_number + L2)#分母
yes_result3=yes_result1 / yes_result2#分子/分母
pro_yes = pro_yes * yes_result3#连乘
#计算该文本属于no的概率
no_result1 = float(sample_word_no_number_dict[word] + L1) # 分子
no_result2 = float(no_words_number + L2) # 分母
no_result3 = no_result1 / no_result2 # 分子/分母
pro_no = pro_no * no_result3 # 连乘
#最后概率还要乘yes和no的比例
word_length = float(yes_words_number + no_words_number)
yes_words_number=float(yes_words_number)
pro_yes = pro_yes * yes_words_number / word_length
no_words_number=float(no_words_number)
pro_no = pro_no * no_words_number / word_length
#通过比较概率大小,得出sample文本属于哪个类别
if pro_yes > pro_no:
print "yes"
elif pro_yes < pro_no:
print "no"
elif pro_yes == pro_no:
print "the probility is the same"
else:
print "error"














 9462
9462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









