







ZipList
我们都知道Dict中是数组加链表的方式实现的,但是链表是一个个指针指向,内存不连续且指针还需要占据一定的空间,那么由此redis引出一个ZipList压缩列表
ZipList是一个特俗的“双端链表”,由一系列特殊编码的的连续内存块组成。可以在任意一端进行压入和弹出操作,并且该操作的时间复杂度是O(1)的。(是没有指针的)
既然这种数据结构没有指针,那么是如何实现压入和弹出操作的
数据结构如下:
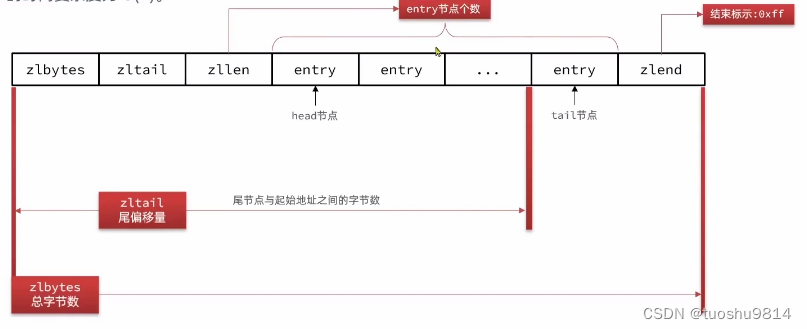
- zlbytes: 总的字节数,占4字节,
- zltail: 尾偏移量(这个直接拿到尾节点的数据)占4字节,
- zllen: entry个数,占2字节,
- entry: 具体的数据,字节数不确定,长度由内容决定
- zlend: 结束标志:0xff, 占1字节
头部分(zlbytes,zltail,zllen)和尾部分(zlend)占的字节数是固定的,直接可以拿到头节点和尾节点的数据的,这就实现了压入和弹出操作
ZipListEntry
ZipList中的Entry并不像普通的链表那样记录前后节点的指针,因为记录两个指针需要16字节,浪费内存,而是采用了下面的结构

- previous_entry_length: 前一节的长度,占一个或5个字节:
- 如果前一节的长度小于254字节,则采用1个字节保存这个长度值
- 如果前一节的长度大于254字节,则采用5个字节保存这个长度值,第一个字节是0xfe,后4个字节才是真实长度
- encoding: 编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
- content: 负责保存节点的数据,可以是字符串或整数
这样我们可以根据前一个节点知道后一个节点数据,我们知道节点起始位置 + previous_entry_length字节 + encoding字节 + content字节,就可以知道下一个节点数据的位置,实现了正序遍历。
也可以进行倒叙遍历,zltail记录了最后一个节点偏移量,那么我们可以得到最后一个节点的起始地址,最后一个节点的起始地址 - 当前节点previous_entry_length,就可以得到前一个节点的起始地址。
redis这样设计没有通过指针就实现了寻址操作
注意:ZipList中所有的存储长度采用了小端字节序,即低位字节在前,高位字节在后,例如:0x1234,采用小端字节序后实际存储的值是:0x3412
Encoding编码
ZipListEntry中的Encoding编码分为字符串和整数两种:
- 字符串: 如果是以“00”,“01”,或者 “10”开头,则证明content是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1字节 | <=63字节 |
| |01pppppp| |qqqqqqqq| | 2字节 | <=16383字节 |
| |10000000| |qqqqqqqq| |rrrrrrrr| |ssssssss| |tttttttt| | 5字节 | <=4294967295字节 |
1字节和2字节除了高两位,后续低位记录就是content的长度
5字节的前面1个字节就是标识后续的4个字节表是长度
例如:我们要保存字符串“ab”和“bc”
“ab”和“bc”的字节占2,都是字符串所以encoding是:00000010,对应的16进制就是0x02

- 整数: 如果encoding是以11开头,则证明content是整数,且content固定只占用1个字节
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| |11000000| | 1字节 | int16(2字节) |
| |11010000| | 1字节 | int32(4字节) |
| |11100000| | 1字节 | int64(8字节) |
| |11110000| | 1字节 | 24位有符整数(3字节) |
| |11111110| | 1字节 | 8位有符整数(1字节) |
| |1111xxxx| | 1字节 | 直接在xxxx位置保存数据,范围从0001- 1101, 减1后结果尾实际值 |
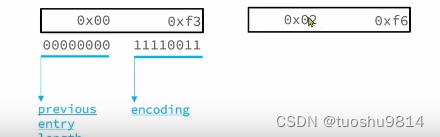
例如:一个ZipList中包含两个整数值: “2”和“5”
2和5的数值比较小,都在0001- 1101这个范围,那么就采用最后一种方式 :
2和5的entry结构如下:
ZipList如下:

ZipList连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- previous_entry_length: 前一节的长度,占一个或5个字节:
- 如果前一节的长度小于254字节,则采用1个字节保存这个长度值
- 如果前一节的长度大于等于254字节,则采用5个字节保存这个长度值,第一个字节是0xfe,后4个字节才是真实长度
现在假设我们有N个连续、长度尾250-253字节之间的entry,因此entry的previous_entry_length属性用一个字节即可表示,如图所示:

这时队首插入一个新的节点,字节长度超过了等于254节点,那么后一个节点previous_entry_length用5个字节表示,那么这个节点也超过了254,后续节点的previous_entry_length都变成了5个字节,这时候触发了后续节点的连续更新,导致连锁更新,
ZipList的删除和新增操作都可能导致连锁更新,不过这种触发的条件概率是很低的
总结
- 压缩列表可以看作是一种连续内存空间的“双向链表”
- 列表的节点之前不是通过指针,而是记录上一个节点和本节点长度来寻址,内存占用比较低
- 如果列表数据过多,导致列表过长,可能影响查询性能
- 增或删可能会触发连锁更新的问题















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









