







MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
索引的数据结构(B+树)
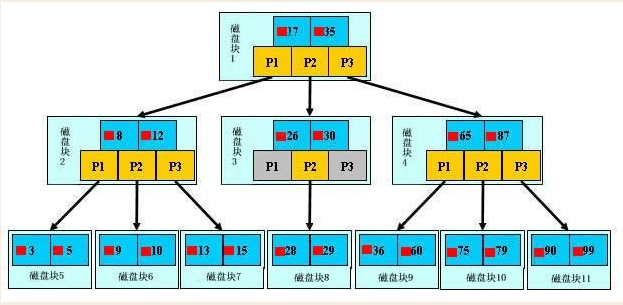
普通索引
加速查找
唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
主键和唯一索引的区别:
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
唯一性索引列允许空值,而主键列不允许为空值。
主键列在创建时,已经默认为非空值 + 唯一索引了。
主键可以被其他表引用为外键,而唯一索引不能。
一个表最多只能创建一个主键,但可以创建多个唯一索引。
主键和唯一索引都可以有多列。
主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
在 RBO 模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
联合索引
联合索引是指对表上的多个列进行索引,联合索引也是一棵B+树,不同的是联合索引的键值数量不是1,而是大于等于2。
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引最左匹配原则:
联合索引ABC三列,单查某列时,只有第一列A索引有效;A and B索引有效,A or B索引无效,顺序无关;B and C索引无效。
全文索引
用于搜索很长一篇文章的时候,效果最好。
空间索引
了解就好,几乎不用。
索引失效分析
1、like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效
2、or语句前后没有同时使用索引。当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效
3、数据类型出现隐式转化。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描
4、在索引列上使用 IS NULL 或 IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引
5、在索引字段上使用not,<>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描(如果是主键,则还是会走索引)
6、对索引字段进行计算操作、字段上使用函数
7、联合索引ABC三列,单查某列时,只有第一列A索引有效;A and B索引有效,A or B索引无效,顺序无关;B and C索引无效
8、排序条件为索引,则select字段必须也是索引字段,否则无法命中
慢查询优化的基本步骤
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析














 4787
4787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









