









一、概述
要配置对三台机器进行hadoop集群配置,每台机子都已经装好Ubuntu12.10 amd64.
对每台机器配置:
sudo gedit /etc/hosts
二、安装jdk
参见Ubuntu12.10下jdk1.7安装配置http://blog.csdn.net/turn88/article/details/12276657
三、安装ssh
ssh 分为客户端 (openssh-client)和服务器( openssh-server),依赖于openssl库,安装 ubuntu 12.10后,系统 已经 默认 安装了 openssl库和 openssh-client,因此 我们只需要安装 openssh-server即可。
sudo apt-get update
sudo apt-get openssh-server
安装完成后输入
ssh localhost
如果可以连通,没有出现connection refused则安装成功。
配置master到slave1和slave2的免密码登陆
免密码登陆参见ssh 免密码登录http://blog.csdn.net/turn88/article/details/12277013
四、安装hadoop
1、解压安装
tar -xzvf hadoop-1.2.1.tar.gzsudo mv hadoop-1.2.1 /usr/local/hadoop
2、配置
(1)配置环境变量
sudo gedit /etc/profile在末尾添加
#set hadoop environment
export HADOOP_HOME=/usr/local/hadoopexport PATH=$HADOOP_HOME/bin:$PATH(2)配置文件
cd /usr/local/hadoopsudo gedit conf/hadoop-env.sh找到相应位置,并修改如下,即添加 JAVA环境变量
这里要输入自己的JAVA_HOME对应的地址。
下面配置core-site.xml、hdfs-site.xml、mapred-site.xml三个文件
sudo gedit conf/core-site.xml如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
sudo gedit conf/hdfs-site.xml如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本个数,不配置默认为3个</description> </property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
<description>配置namenode的本地路径</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>配置datanode的本地路径</description>
</property>
</configuration>
sudo gedit conf/mapred-site.xml如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>3、启动
重启计算机
格式化namenode
cd /usr/local/hadoop
bin/hadoop namenode -format开启hadoop
bin/start-all.sh打开浏览器输入localhost:50070,如果如下所示,则成功
上传文件到HDFS
bin/hadoop fs -mkdir input
bin/hadoop fs -put text input/text
运行wordcount程序
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount input output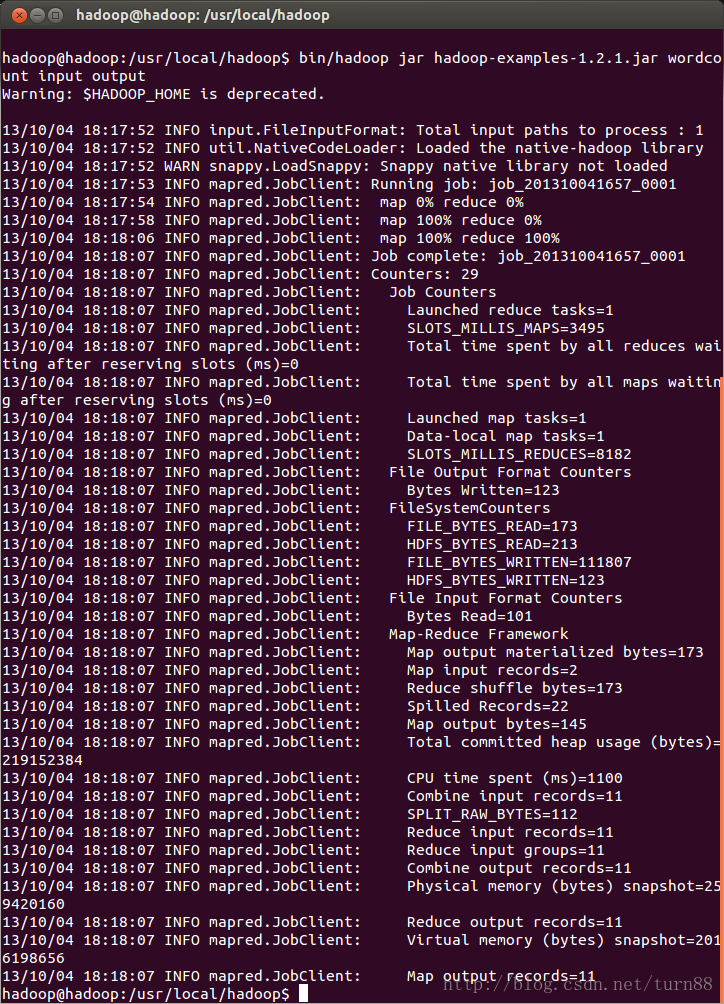















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









