







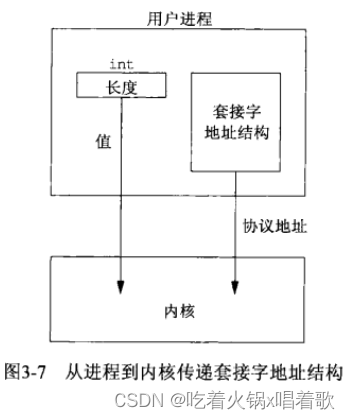
先介绍套接字地址结构,本书中几乎每个例子都会用到它们,该结构可在两个方向上传递:从进程到内核和从内核到进程。从内核到进程方向的传递是值-结果参数的例子。
地址转换函数在地址的文本表达和它们存放在套接字地址结构中的二进制值之间进行转换。多数现存IPv4代码使用inet_addr和inet_ntoa函数,但新函数inet_pton和inet_ntop同时适用于IPv4和IPv6代码。这些地址转换函数与它们所转换的地址类型协议相关,要考虑究竟是IPv4地址还是IPv6地址,为解决此问题,我们自己开发了一组以sock_开头的函数,它们以协议无关方式使用套接字地址结构,使得代码与协议无关。
大多套接字函数需要一个指向套接字地址结构的指针作为参数。每个协议族都定义它自己的套接字地址结构,这些结构的名字均以sockaddr_开头。
IPv4套接字地址结构通常也称为网际套接字地址结构,名字是sockaddr_in,定义在netinet/in.h头文件中,以下是它的POSIX定义:

长度字段sin_len是为增加对OSI协议的支持而随4.3 BSD Reno添加的,在此之前,sockaddr_in结构的第一个成员是sin_family,它是无符号短整数(unsigned short)类型。不是每个厂家都支持该字段,POSIX规范也不要求有此字段。该成员的数据类型uint8_t是典型的,符合POSIX的系统都提供这种形式的数据类型。如果长度字段sin_len随套接字API的原始版本提供了,那么现在所有套接字函数就不需要长度参数了(如bind和connect函数的第3个参数)。
长度字段sin_len简化了长度可变套接字地址结构的处理。
即使有长度字段sin_len,我们也无需设置和检查它,除非涉及路由套接字,该字段是由处理来自不同协议族的套接字地址结构的例程(如路由表处理代码)在内核中使用的。
源自Berkeley的实现中,从进程到内核传递套接字地址结构的4个套接字函数(bind、connect、sendto、sendmsg)都要调用sockargs函数,sockargs函数从进程复制套接字地址结构,并显式地把它的sin_len字段设置成作为参数传递给这4个函数的该地址结构的长度。从内核到进程传递套接字地址结构的5个套接字函数为accept、recvfrom、recvmsg、getpeername、getsockname,这5个函数均在返回前设置sin_len字段。
通常没有简单的编译时测试来确定一个实现是否为它的套接字地址结构定义了长度字段,我们的代码中通过测试HAVE_SOCKADDR_SA_LEN常值来确定,然而是否定义该常值需编译一个使用这个可选的长度字段的简单测试程序,并看是否编译成功来确定。如果套接字地址结构有长度字段,则IPv6实现需定义SIN6_LEN,一些IPv4实现(如Digital Unix)基于某个编译时选项(如_SOCKADDR_LEN)确定是否给应用提供了套接字地址结构中的长度字段,这个特性为较早的程序提供了兼容性。
符合POSIX规范只需sockaddr_in结构包含sin_family、sin_addr、sin_port三个字段。对于符合POSIX的实现来说,定义额外的字段是可以接受的,几乎所有实现都定义了sin_zero字段,所以所有的套接字地址结构大小都至少16字节。
in_addr_t类型至少是一个32位的无符号整数类型;in_port_t类型至少是一个16位的无符号整数类型;sa_family_t可以是任何无符号整数类型,在支持长度字段sin_len的实现中,sa_family_t通常是一个8位的无符号整数,在不支持长度字段sin_len的实现中,它是一个16位的无符号整数。

类型u_char、u_short、u_int、u_long都是无符号的,POSIX定义这些类型时特意标记它们为已过时,仅是为了向后兼容才提供的。
IPv4地址和端口号在套接字地址结构中以网络字节序来存储。
32位IPv4地址有两种访问方法,举例来说,如果serv定义为某个网际套接字地址结构,那么serv.sin_addr将按in_addr结构引用其中的32位IPv4地址,而serv.sin_addr.s_addr将按in_addr_t(通常是一个32位无符号整数)引用同一个32位IPv4地址。因此我们必须正确使用这两个IPv4地址,尤其是将它们作为函数的参数使用时,因为编译器对传递结构和传递整数的处理是不同的。
sin_addr字段是一个结构,而不仅仅是一个in_addr_t类型的无符号长整数,这是有历史原因的。早期的版本(4.2 BSD)把in_addr结构定义为一个union,允许访问一个32位IPv4地址中的所有4个字节,或者访问它的2个16位值,这用于地址被划分成A、B、C三类的时期,以便获取地址中的适当字节,然而随着子网划分技术和无类地址编排的出现,三种地址类正在消失,这个联合也不再需要了,如今大多系统已经废除了此联合,转而把in_addr结构定义为仅有一个in_addr_t字段的结构。
sin_zero字段未曾使用,我们总是把sin_zero字段置为0,按照惯例,我们总是在填写前把整个结构置0,而不单独将sin_zero字段置0。
套接字地址结构不在主机之间传递,仅用于主机上确定通信信息。
套接字地址结构总是以指向该结构的指针方式来传递进套接字函数,以这样的指针作为参数的套接字函数必须处理来自所支持的任何协议族的套接字地址结构。如何声明指向套接字地址结构的指针的数据类型存在一个问题,有了ANSI C后很简单,void *是通用指针类型,但套接字函数是在ANSI C前定义的,1982年采取的办法是在头文件sys/socket.h中定义一个通用的套接字地址结构:

于是套接字函数的套接字地址结构指针参数的类型是指向通用套接字地址结构的指针,如bind函数的ANSI C函数原型为int bind(int, struct sockaddr *, socklen_t);。这就要求调用这些函数时要将指向特定于协议的套接字地址结构的指针进行类型强制转换,变成指向通用套接字地址结构的指针:
struct sockaddr_in serv; /* IPv4 socket address structure */
/* full in serv{} */
bind(sockfd, (struct sockaddr *)&serv, sizeof(serv));
如果我们不进行类型强制转换,并假设系统头文件中有bind函数的一个ANSI C原型,则C编译器会产生警告wrning: passing arg 2 of 'bind' from incompatible pointer type.(警告:把不兼容的指针类型传递给bind函数的第二个参数)。
对于应用程序开发人员,通用套接字地址结构唯一的作用是要对指向特定于协议的套接字地址结构的指针执行强制类型转换。
在我们自己的unp.h头文件中,把SA定义为struct sockaddr只是为了缩短类型强制转换这些指针所写的代码。
从内核角度看,内核取调用者传入的指针,把它类型强制转换为struct sockaddr *类型,然后检查其中sa_family字段的值来确定这个结构的真实类型。然而从开发人员角度看,使用void *类型就更简单了,因为无须显式进行类型强制转换。
IPv6套接字地址结构在头文件netinet/in.h中定义:

IPv6对于套接字API的扩展定义在RFC 3493中。
对于上图需要注意:
1.如果系统支持套接字地址结构中的长度字段sin6_len,那么必须定义SIN6_LEN。
2.IPv6的地址族是AF_INET6,而IPv4的是AF_INET4。
3.结构中字段的先后顺序做过编排,使得如果sockaddr_in6结构本身是64位对齐的(即该结构被存储在内存地址为64位的整数倍处),那么128位的sin6_addr成员也是64位对齐的。在一些64位处理机上,如果64位数据存储在某个64位边界位置,那么对它的访问将得到优化处理。
4.sin6_flowinfo字段分成两个字段:低序20位是流标;高序12位保留。
5.对于具备范围的地址,sin6_scope_id字段标识其范围,最常见的是链路局部地址的接口索引。
作为IPv6套接字API的一部分而定义的新的通用套接字地址结构克服了现有struct sockaddr的一些缺点,新的struct sockaddr_storage足以容纳系统所支持的任何套接字地址结构,新结构定义在头文件netinet/in.h中:

sockaddr_storage与sockaddr类型存在以下区别:
1.如果系统支持的任何套接字地址结构有对齐需要,sockaddr_storage能满足最苛刻的对齐要求(苛刻表示更大的对齐值,如8字节对齐比4字节对齐更苛刻,因为8字节对齐时结构能在内存中放置的位置更少,是4字节对齐的一半)。
2.sockaddr_storage足够大,能容纳系统支持的任何套接字地址结构。
除了ss_family和ss_len(如果存在)字段外,sockaddr_storage结构中的其他字段对用户来说是透明的。sockaddr_storage结构必须类型强制转换成或复制到ss_family字段对应的地址类型的套接字地址结构中,才能访问其他字段。
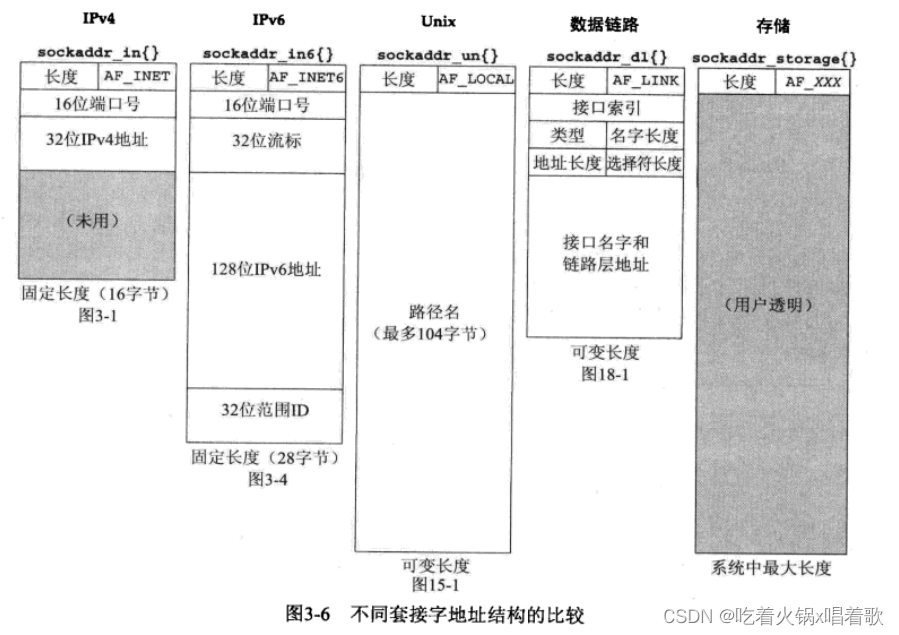
上图中,我们假设所有套接字地址结构都包含一个单字节的长度字段,地址族字段也占用一个字节,其他所有字段都占用其可能的最短长度。
为了处理长度可变的结构,当我们把指向某个套接字地址结构的指针作为一个参数传递给某套接字函数时,也把该结构的长度作为另一个参数传递给这个函数。
上图中每种长度固定的结构下方给出了它在4.4 BSD实现中的字节数长度。
sockaddr_un结构本身并非长度可变的,但其中的路径名长度是可变的,当传递指向此结构的指针时,必须小心处理长度字段,包括套接字地址结构中的长度字段(如果实现支持)和作为参数传给内核或从内核返回的长度。
当给一个套接字函数传递一个套接字地址结构时,总是以该结构的指针传递,该结构的长度也作为一个参数传递,该长度参数的传递方式取决于该结构的传递方向,从进程到内核或从内核到进程。
从进程到内核传递套接字地址结构的函数有bind、connect、sendto,这些函数的有一个参数是指向某套接字地址结构的指针,还有一个参数是该结构的整数大小。此时内核就知道了需要从进程复制多少数据进来:
表示套接字地址结构大小的数据类型是socklen_t而不是int,POSIX建议将其定义为uint32_t。
从内核到进程传递套接字地址结构的函数有accept、recvfrom、getsockname、getpeername。这些函数的参数中的两个是指向某个套接字地址结构的指针和指向该结构大小的整数变量的指针:
struct sockaddr_un cli; /* Unix domain */
socklen_t len;
len = sizeof(cli); /* len is a value */
getpeername(unixfd, (SA *), &cli, &len);
/* len may have changed */
将套接字地址结构大小这一参数从整数改为指向整数的指针的原因在于,当函数被调用时,结构大小是一个值,它告诉内核该结构的大小,这样内核在写该结构时不至于越界;而当函数返回时,结构大小是一个结果,它告诉进程内核在结构中存储了多少信息。这种类型的参数被称为值-结果参数:

我们说套接字地址结构在进程和内核间传递,对于如4.4 BSD之类的实现,由于所有套接字都是内核中的系统调用,因此这是正确的。但在另外的一些实现中,如System V,套接字函数只作为普通用户进程执行的库函数,这些函数与内核中的协议栈如何互动是这些实现的细节问题,对我们通常没有任何影响,为简单起见,我们说套接字地址结构在进程与内核间传递,而System V的确在进程和内核间传递套接字地址结构,但那是作为流消息的一部分传递的。
传递套接字地址结构的函数还有recvmsg和sendmsg,它们套接字地址结构的长度不是作为函数参数而是作为结构字段传递的。
使用值-结果参数作为套接字地址结构的长度时,如果套接字地址结构是固定长度的,那么从内核返回的值总是那个固定长度,如IPv4的sockaddr_in长度是16字节,IPv6的sockaddr_in6的长度是28字节。对于可变长度的套接字地址结构(如Unix域的sockaddr_un),返回值可能小于该结构的最大长度。
一些有值-结果参数的函数:
1.select函数中间的3个参数。
2.getsockopt函数的长度参数。
3.使用recvmsg函数时,msghdr中的msg_namelen和msg_controllen字段。
4.ifconf结构中的ifc_len字段。
5.sysctl函数两个长度参数中的第1个。
内存中存储一个整数有两种方法,一种是将低序字节存储在起始地址,这称为小端字节序;另一种是将高序字节存储在起始地址,这称为大端字节序:

上图中,MSB(Most Significant Bit)为最高有效位,LSB(Least Significant Bit)为最低有效位。
术语小(大)端表示多字节值的小(大)端存储在该值的起始地址。
这两种格式都有主机使用,我们把某个给定系统所用的字节序称为主机字节序,确定主机使用的字节序:
#include <stdio.h>
#include <stdlib.h>
int main() {
union {
short s;
char c[sizeof(short)];
} un;
un.s = 0x0102;
printf("%s: ", CPU_VENDOR_OS);
if (sizeof(short) == 2) {
if (un.c[0] == 1 && un.c[1] == 2) {
printf("big-endian\n");
} else if (un.c[0] == 2 && un.c[1] == 1) {
printf("little-endian\n");
} else {
printf("unknown\n");
}
} else {
printf("sizeof(short) = %d\n", sizeof(short));
}
exit(0);
}
以上程序中,我们在一个短整型变量中存放2字节的值0x0102,然后查看它的低地址字节c[0]和高地址字节c[1]确定字节序。
以上程序中的字符串CPU_VENDOR_OS是由GNU的autoconf程序在配置时确定的,它标识CPU类型、厂家、操作系统版本。
有很多系统可以在重置时或运行时在大端字节序和小端字节序之间切换。
网际协议使用大端字节序传送32bit IPv4地址和16bit端口号。
理论上说,具体实现可以按主机字节序存储套接字地址结构中的各个字段,等需要将这些字段和协议首部中相应字段转换时,再在主机字节序和网络字节序之间互转,让我们免于关心转换的细节,但由于历史原因和POSIX规范的规定,套接字地址结构中某些字段必须按网络字节序进行维护,因此我们要关注如何在主机字节序和网络字节序之间相互转换。主机字节序和网络字节序之间转换的函数:

以上函数名中的h表示host,n表示network,s代表short,l代表long。short和long这两个称谓是出自4.2 BSD的Digital VAX实现的历史产物,如今我们把s视为一个16位的值(如TCP或UDP端口号),把l视为一个32位的值(如IPv4地址)。事实上,即使在64位的Digital Alpha中,尽管长整型占64位,htonl和ntohl函数操作的仍然是32位值。
使用这些函数时,不需关心主机字节序是大端还是小端。在那些使用大端字节序的系统中,这四个函数常定义为空宏。
几乎所有计算机都使用8位字节,我们用术语字节表示一个8位的量。大多因特网标准表示一个8位量的术语是八位组(octet)而非字节,该术语起源于TCP/IP发展的早期,当时许多早期的工作是在诸如DEC-10这样的系统上进行的,这些系统就不使用8位的字节。
因特网中一个重要的约定是位序,在许多因特网标准的RFC文档中,可以看到类似以下图示(该图取自RFC 791,是IPv4首部的前32位):

上图表示在线缆上出现的顺序排列的4个字节,最左边是最早出现的最高有效位。位序的编号从0开始,分配给最高有效位的编号为0。熟悉以上记法,以方便阅读RFC文档中的协议定义。
20世纪80年代在网络编程上存在一个普遍的问题,在Sun工作站(Motorola 68000处理器,大端主机字节序)上开发代码时可能会忘记调用转换字节序的4个函数中的任何一个,这些代码在大端主机字节序的机器上都能运行,但当移植到小端机器(如VAX系列机)上时就不能工作。
操纵多字节字段的函数有两组,它们既不对数据作解释,也不假设数据是以空字符结束的C字符串,处理套接字地址结构时,我们需要这些函数,因为我们需要操纵诸如IP地址这样的字段,这些字段可能包含值为0的字节,却不是C字符串。以空字符结尾的C字符串是由定义在string.h头文件中、名字以str开头的函数处理的。
名字以b(表示字节)开头的第一组函数起源于4.2 BSD,几乎所有现今支持套接字函数的系统仍提供它们。名字以mem(表示内存)开头的第二组函数起源于ANSI C标准,支持ANSI C函数库的所有系统都提供它们。
首先给出源自Berkeley的操纵多字节字段的函数:

上图中的函数本书中只使用bzero函数,我们使用它是因为它只有2个参数,比3个参数的memset函数容易记。
上图中,ANSI C的限定词const对于以上三处使用来说,表示所限定的指针所指内容不会被函数更改,即函数只是读而不修改由const指针所指的单元。
bzero函数把目标字节串中指定数目的字节置0,我们常用该函数把套接字地址结构初始化为0。
bcopy函数将指定数目的字节从源字节串移到目标字节串。
bcmp函数比较两个任意字节串,如果相同返回0,否则返回非0。
然后是ANSI C的操纵多字节字段的函数:

memset函数把目标字节串指定数目的字节置为参数c的值。
memcpy函数类似于bcopy函数,但两个指针的顺序是相反的。当源字节串与目标字节串重叠时,bcopy函数能正确处理,但memcpy函数的操作结果不可知,此时应改用ANSI C的memmove函数,当目标区域和源区域有重叠时,memmove函数会在源串被覆盖之前将重叠区域的字节拷贝到目标区域中。
记住memcpy函数中两个指针参数顺序的方法之一是它们是与C中的赋值语句相同顺序从左到右书写的dest = src;。
记住memset函数中最后两个参数顺序的方法之一是认识到所有ANSI C的memxxx函数都需要一个长度参数,且它总是最后一个参数。
memcmp函数比较两个任意的字节串,若相同返回0,否则返回非0值,是大于0还是小于0取决于第一个不等的字节,如果参数ptr1所指字节串中的这个字节大于参数ptr2所指字节串中的对应字节,则大于0,否则小于0。比较操作是在假设两个不等的字节均为无符号字符(unsigned char)的前提下完成的。
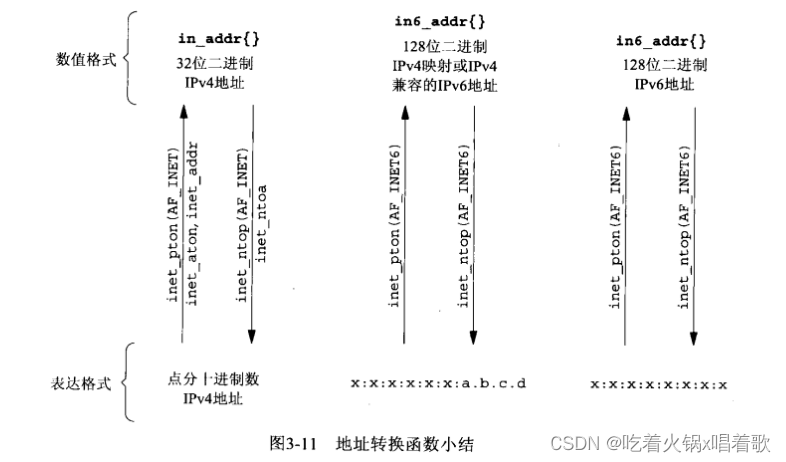
下面介绍两组地址转换函数,它们在ASCII字符串(人们偏爱使用的格式)和网络字节序的二进制值(即存放在套接字地址结构中的值)之间转换网际地址。
第一组函数inet_aton、inet_addr、inet_ntoa在点分十进制数串(如206.168.112.96)与其对应的长度为32位的网络字节序二进制值键转换IPv4地址。
第二组函数是两个较新的函数inet_pton和inet_ntop,它们对于IPv4和IPv6地址都适用。

inet_aton函数将参数strptr所指C字符串转换成一个32位的网络字节序的二进制值,并通过指针参数addrptr来存储,若成功返回1,否则返回0。
inet_aton函数有一个没写入正式文档中的特征:如果参数addrptr指针为空,那么该函数仍然对输入的字符串执行有效性检查,但不存储任何结果。
inet_addr函数将参数strptr所指C字符串转换成一个32位的网络字节序的二进制值,并将该二进制值返回。该函数存在一个问题,所有232个可能的二进制值都是有效的IP地址(从0.0.0.0到255.255.255.255),但当出错时该函数返回INADDR_NONE常值,该值通常是一个32位均为1的值,这意味着点分十进制255.255.255.255(IPv4的有限广播地址)不能由该函数处理,因为它的二进制值被用来指示该函数失败。
inet_addr函数还存在一个问题,一些手册页面声明该函数出错时返回-1而非INADDR_NONE,这样对该函数的返回值(一个无符号值,in_addr_t一般定义为uint32_t)和一个负常量(-1)比较时可能会有问题,具体取决于编译器。
函数inet_addr现已被废弃,应使用函数inet_aton,或即将介绍的函数inet_pton,它同时适用于ipv4和ipv6地址。
函数inet_ntoa将32bit的网络字节序二进制IPv4地址转换成相应的点分十进制串,该函数返回值所指向的字符串驻留在静态内存,因此该函数是不可重入的。该函数罕见地以一个结构而非指向结构的指针为参数。
以下是随IPv6出现的新函数,对IPv4和IPv6都适用,函数名中的p和n分别代表表达(presentation)和数值(numeric),地址的表达格式通常是ASCII字符串,数值格式通常是存放到套接字地址结构中的二进制值:

这两个函数的family参数既可以是AF_INET,也可以是AF_INET6,如果以不被支持的地址族作为family参数,这两个函数都会返回一个错误,并将errno置为EAFNOSUPPORT。
inet_pton函数尝试转换由指针参数strptr所指的字符串,并通过指针参数addrptr存放二进制结果。若成功返回1,否则如果对所指定的family参数而言输入字符串不是有效的表达形式,则返回0,如出错,返回-1。
inet_ntop函数进行相反的转换,从数值格式转换到表达格式。len参数是目标存储单元(即strptr参数所指空间)的大小,以免该函数溢出其调用者的缓冲区。为有助于指定这个大小,在头文件netinet/in.h中有如下定义:
#define INET_ADDRSTRLEN 16 /* for IPv4 dotted-decimal,如255.255.255.255\n */
#define INET6_ADDRSTRLEN 46 /* for IPv6 hex string,如0000:0000:0000:0000:0000:FFFF:111.222.212.222\n,最后的IPv4地址表示该地址是IPv4映射的IPv6地址 */
如果参数len太小,不足以容纳表达格式结果(包括结尾的空字符),那么返回一个空指针,并置errno为ENOSPC。
inet_ntop函数的strptr参数不能是空指针,调用者必须为目标存储单元分配内存并指定其大小,调用成功时,返回值就是指针参数strptr。
如果你的系统不支持IPv6,可用代码:
foo.sin_addr.s_addr = inet_addr(cp);
代替:
inet_pton(AF_INET, cp, &foo.sin_addr);
还有用代码:
ptr = inet_ntoa(foo.sin_addr);
代替:
char str[INET_ADDRSTRLEN];
ptr = inet_ntop(AF_INET, &foo.sin_addr, str, sizeof(str));
只支持IPv4的inet_pton函数的简单版本:
int inet_pton(int family, const char *strptr, void *addrptr) {
if (family == AF_INET) {
struct in_addr in_val;
if (inet_aton(strptr, &in_val) {
memcpy(addrptr, &in_val, sizeof(struct in_addr));
return 1;
}
return 0;
}
errno = EAFNOSUPPORT;
return -1;
}
仅支持IPv4的inet_ntop函数的简化版本:
const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len) {
const u_char *p = (const u_char *)addrptr;
if (family == AF_INET) {
char temp[INET_ADDRSTRLEN];
snprintf(temp, sizeof(temp), "%d.%d.%d.%d", p[0], p[1], p[2], p[3]);
if (strlen(temp) >= len) {
errno = ENOSPC;
return NULL;
}
strcpy(strptr, temp);
return strptr;
}
errno = EAFNOSUPPORT;
return NULL;
}
inet_ntop函数的问题是,它要求调用者传递一个指向某个二进制地址的指针,而该地址通常包含在一个套接字地址结构中,这要求调用者必须知道这个套接字地址结构的格式和地址族,即为了使用inet_ntop函数,我们要为IPv4编写以下代码:
struct sockaddr_in addr;
inet_ntop(AF_INET, &addr.sin_addr, str, sizeof(str));
或为IPv6编写如下代码:
struct sockaddr_in6 addr6;
inet_ntop(AF_INET6, &addr6.sin6_addr, str, sizeof(str));
这就使我们的代码与协议相关了。为解决此问题,我们自行编写一个函数sock_ntop,它以指向某个套接字地址结构的指针为参数,然后查看该结构内部,然后用相应方法调用函数返回该地址的表达格式:

我们自己定义的函数(非标准系统函数)的说明形式如上:包围函数原型和返回值的方框是虚线,开头包括的头文件通常是我们自己的unp.h。
sock_ntop函数的sockaddr参数指向一个长度为addrlen参数的套接字地址结构,该函数用它自己的静态缓冲区来保存结果,指向该缓冲区的一个指针就是它的返回值。
对结果进行静态存储会导致该函数不可重入且非线程安全,sock_ntop函数这样设计是为了让本书中的简单例子更方便地调用它。
我们的表达格式是在一个IPv4地址的点分十进制数串格式后,或在一个括以方括号的IPv6地址的十六进制数串格式之后,跟一个终止符(我们用一个冒号,类似URL的语法),再跟一个十进制端口号,最后跟一个空字符。因此,缓冲区大小对于IPv4至少为INET_ADDRSTRLEN加上6个字节(16+6=22,最多6位的端口号和一个冒号),对于IPv6至少为INET6_ADDRSTRLEN加上8个字节(46+8=54,最多6位的端口号和一个冒号和两个方括号)。
以下是sock_ntop函数仅支持AF_INET情形下的代码:
char *sock_ntop(const struct sockaddr *sa, socklen_t salen) {
char portstr[8];
static char str[128]; /* Unix domain is largest */
switch (sa->sa_family) {
case AF_INET:
struct sockaddr_in *sin = (struct sockaddr_in *)sa;
if (inet_ntop(AF_INET, &sin->sin_addr, str, sizeof(str)) == NULL) {
return NULL;
}
if (ntohs(sin->sin_port) != 0) {
snprintf(portstr, sizeof(portstr), ":%d", ntohs(sin->sin_port));
strcat(str, portstr);
}
return str;
}
}
我们还为操作套接字地址结构定义了其他几个函数,它们将简化我们的代码在IPv4和IPv6之间的移植:

函数sock_bind_wild将通配地址和一个临时端口绑定到一个套接字。函数sock_cmp_addr比较两个套接字地址结构的地址部分。函数sock_cmp_port比较两个套接字地址结构的端口号部分(上图中第3个函数,图中函数名是错误的)。函数sock_get_port返回端口号。函数sock_ntop_host以协议无关的方式把一个套接字地址结构中的IP地址从二进制格式转换为可读格式(仅返回IP地址的可读格式,不涉及端口号的处理)。函数sock_set_addr把一个套接字地址结构中的地址部分置为ptr指针参数所指的值。函数sock_set_port设置一个套接字地址结构的端口号部分。函数sock_set_wild把一个套接字地址结构中的地址部分置为通配地址。
以上函数中,返回值不为void的函数也提供了包裹函数,它们的名字以S开头。
字节流套接字(如TCP套接字)上的read和write函数所表现的行为不同于通常的文件IO,字节流套接字上调用read或write输入或输出的字节数可能比请求的数量少,但这不是出错状态。这个现象的原因在于内核中用于套接字的缓冲区可能已达到上限,此时需要调用者再次调用read或write函数以输入或输出剩余字节。有些版本的Unix在往一个管道中写多于4096字节的数据时也会有这样的行为,这个现象在read一个字节流套接字时很常见(读完接收缓冲区的数据或读到了指定大小时就返回),但在write一个字节流套接字时只在该套接字为非阻塞的前提下才出现。因此为了不让实现返回一个不足的字节计数值,我们用writen函数代替write函数。
以下是读写一个字节流套接字时使用的函数:

以下是readn函数的实现,它从一个描述符中读n字节:
#include "unp.h"
ssize_t readn(int fd, void *vptr, size_t n) { /* Read "n" bytes from a descriptor. */
size_t nleft;
ssize_t nread;
char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ((nread = read(fd, ptr, nleft)) < 0) {
if (errno == EINTR) {
nread = 0; /* and call read() again */
} else {
return -1;
}
} else if (nread == 0) {
break; /* EOF */
}
nleft -= nread;
ptr += nread;
}
return n - nleft; /* return >= 0 */
}
以下是writen函数的实现,它往一个描述符写n字节:
#include "unp.h"
ssize_t writen(int fd, const void *vptr, size_t n) { /* Write "n" bytes to a descriptor. */
size_t nleft;
ssize_t nwritten;
const char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ((nwritten = write(fd, ptr, nleft)) <= 0) {
if (nwritten < 0 && errno == EINTR) {
nwritten = 0; /* and call write() again */
} else {
return -1; /* error */
}
}
nleft -= nwritten;
ptr += nwritten;
}
return n;
}
readn和writen函数即使已经读或写了一部分数据,如果出错,返回值还是-1。这两个函数都将参数里的void *类型指针转换为了char *指针,因为该指针需要按字节数增长,如果不转换,C不允许增长void *类型指针。
以下是readline函数的实现,它从一个描述符读文本行,一次1个字节:
#include "unp.h"
/* PAINFULLY SLOW VERSION -- example only */
ssize_t readline(int fd, void *vptr, size_t maxlen) {
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; ++n) {
again:
if ((rc = read(fd, &c, 1)) == 1) {
*ptr++ = c;
if (c == '\n') {
break; /* new line is stored. like fgets() */
}
} else if (rc == 0) {
*ptr = 0;
return n - 1; /* EOF, n - 1 bytes were read() */
} else {
if (errno == EINTR) {
goto again;
}
return -1; /* error, errno set by read() */
}
}
*ptr = 0; /* null terminate like fgets() */
return n;
}
readline函数返回读到的字节数,它的参数maxlen含义为指针参数vptr指向的空间大小。
上述3个函数在读写错误返回时,都会检查errno是否为EINTR,这个错误表示系统调用被一个捕获的信号中断,如果发生了该错误,则继续进行读写。既然以上函数的作用是避免让调用者处理不足的字节计数值,那么我们就在函数中处理该错误,避免让调用者再次调用以上函数。
MSG_WAITALL标志可随recv函数一起使用来取代readn函数。
以上readline函数每读一个字节数据就系统调用一次read函数,这很低效,当面临从某个套接字读入文本行需求时,使用标准IO库(即stdio)非常诱人,但这是一种危险的方法,stdio缓冲机制会引发许多逻辑问题,可能导致应用程序中存在相当隐蔽的缺陷,究其原因在于stdio缓冲区的状态是不可见的。为深入解释,考虑客户和服务器之间的一个基于文本行的协议,使用该协议的多个客户程序和多个服务器可能是在一段时间内先后实现的(这很普遍,如按HTTP规范独立编写的Web浏览器程序和Web服务器程序就相当多),良好的防御性编程要求这些程序不仅能期望它们的对端程序也遵循相同的网络协议,而且能检查出来预期外的数据并加以修正(恶意企图自然也被检查出来),这样可以使网络应用能够从存在问题的网络数据传送中恢复,可能的话还会继续工作。为了提升性能而使用stdio缓冲区违背了这一目标,因为这样的应用进程不能分辨stdio缓冲区中是否有预期外的数据。
基于文本行的网络协议有SMTP、HTTP、FTP的控制连接协议、finger等,因此针对文本行操作的需求被一再提出,但我们的建议是依照缓冲区而不是文本行来考虑编程,即编写从缓冲区中读取代码,当期待一个文本行时,就查看缓冲区中是否有这行。
以下是readline函数的一个较快速版本,它使用自己的缓冲机制,其中重要的是readline内部缓冲区的状态是暴露的,使得调用者能查看缓冲区中到底收到了什么。但这个readline函数仍可能存在问题,如select等系统函数仍然不可能知道readline使用的内部缓冲区,因此编写不严谨的程序可能发现自己在select函数上等待的数据早已收到并存放在readline的缓冲区中了,因此混合调用readn和readline函数不会像预期那样工作,除非把readn函数也修改成检查readline函数的内部缓冲区。以下是使用自己缓冲机制的readline函数:
#include "unp.h"
static int read_cnt;
static char *read_ptr;
static char read_buf[MAXLINE];
// 每次最多读MAXLINE个字节,每次返回一个字节
static ssize_t my_read(int fd, char *ptr) {
if (read_cnt <= 0) {
again:
if ((read_cnt = read(fd, read_buf, sizeof(read_buf))) < 0) {
if (errno == EINTR) {
goto again;
}
return -1;
} else if (read_cnt == 0) {
return 0;
}
read_ptr = read_buf;
}
read_cnt--;
*ptr = *read_ptr++;
return 1;
}
// readline函数本身唯一的变化是用my_read函数取代read函数
ssize_t readline(int fd, void *vptr, size_t maxlen) {
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; ++n) {
if ((rc = my_read(fd, &c)) == 1) {
*ptr++ = c;
if (c == '\n') {
break; /* new line is stored, like fgets() */
}
} else if (rc == 0) {
*ptr = 0;
return n - 1; /* EOF, n - 1 bytes were read */
} else {
return -1;
}
}
*ptr = 0; /* null terminate like fgets() */
return n;
}
// 此函数可以展露内部缓冲区的状态,便于调用者查看在当前文本行后是否收到了新数据
ssize_t readlinebuf(void **vptrptr) {
if (read_cnt) {
*vptrptr = read_ptr;
}
return read_cnt;
}
以上readline函数使用静态变量实现跨函数调用的状态信息维护,其结果是这些函数变得不可重入或者说非线程安全了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









