







12.8.4 用partition()实现“重排数组,让奇数位于偶数前面”
std::partition()的作用是把符合条件的元素放到区间首部,不符合条件的元素放到区间后部,我们只需把“符合条件”定义为“元素是奇数”就能解决这道题。复杂度是O(N)时间和O(1)空间。为节省篇幅,isOdd()直接做成了函数,而不是函数对象,缺点是有可能阻止编译器实施inline(函数对象还可以有状态,即重载了operator()的类中可以有数据成员保存状态)。
// recipes/algorithm/partition.cc
bool isOdd(int x)
{
return x % 2 != 0; // x % 2 == 1 is WRONG
}
void moveOddsBeforeEvens()
{
int oddeven[] = {1,2,3,4,5,6};
std::partition(oddeven, oddeven + 6, &isOdd);
std::copy(oddeven, oddeven + 6, std::ostream_iterator<int>(std::cout, ", "));
std::cout << std::endl;
}
输出如下,注意确实满足“奇数位于偶数之前”,但奇数元素之间的相对位置有变化,偶数元素亦是如此。
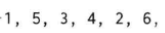
如果题目要求改成“调整数组顺序使奇数位于偶数前面,并且保持奇数的先后顺序不变,偶数的先后顺序不变”,解决办法也一样简单,改用std::stable_partition()即可,代码及输出如下:
int oddeven[] = {1,2,3,4,5,6};
std::stable_partition(oddeven, oddeven + 6, &isOdd);
std::copy(oddeven, oddeven + 6, std::ostream_iterator<int>(std::cout, ", "));
std::cout << std::endl;
// 输出1, 3, 5, 2, 4, 6
注意,stable_partition()的复杂度较特殊:在内存充足的情况下,开辟与原数组一样大的空间,复杂度是O(N)时间和O(N)空间;在内存不足的情况下,要做in-place位置调换,复杂度是O(NlogN)时间和O(1)空间。
类似的题目还有“调整数组顺序使负数位于非负数前面”,读者应能举一反三。
12.8.5 用lower_bound()查找IP地址所属的城市
题目:已知N个IP地址和它们对应的城市名称,写一个程序,能从IP地址找到它所在的城市。注意这些IP地址区间互不重叠。
这道题目的naive解法是O(N),借助std::lower_bound()可以轻易做到O(logN)查找,代价是事先做一遍O(NlogN)的排序。如果区间相对固定而查找很频繁,这么做是值得的。
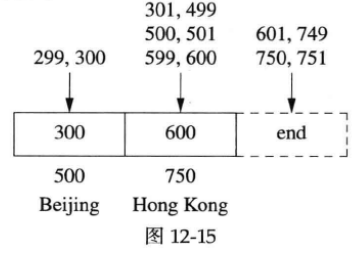
基本思路是按IP区间的首地址排好序,再进行二分查找。比如说有两个区间[300, 500]、[600, 750],分别对应北京和香港两个城市,那么std::lower_bound()查找299、300、301、499、500、599、600、601、749、750、751等“IP地址”返回的迭代器如图12-15所示。
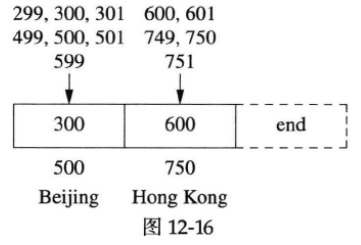
我们需要对返回的结果微调(下面注释1所在行到注释2所在行),使得迭代器it所指的区间是唯一有可能包含该IP地址的区间,如图12-16所示。
最后判断一下IP地址是否位于这个区间就行了(注释3所在行)。完整代码如下,为了简化,“城市”用整数表示,-1表示未找到。另外,这个实现对于整个IP地址空间都是正确的,即便区间中包括[255.255.255.0, 255.255.255.255]这种边界条件。
// recipes/algorithm/iprange.cc
struct IPrange
{
uint32_t startIp; // inclusive
uint32_t endIp; // inclusive
int value; // >= 0
bool operator<(const IPrange &rhs) const
{
return startIp < rhs.startIp;
}
};
// REQUIRE: ranges is sorted.
int findIpValue(const std::vector<IPrange> &ranges, uint32_t ip)
{
int result = -1;
if (!ranges.empty())
{
IPrange needle = {ip, 0, 0};
std::vector<IPrange>::const_iterator it = std::lower_bound(ranges.begin(), ranges.end(), needle);
if (it == ranges.end())
{
--it;
}
else if (it != ranges.begin() && it->startIp > ip)
{
--it;
}
if (it->startIp <= ip && it->endIp >= ip)
{
result = it->value;
}
}
return result;
}
说明:如果IP地址区间有重复,那么我们通常要用线段树(http://en.wikipedia.org/wiki/Segment_tree)来实现高效的查询。另外,在真实的场景中,IP地址区间通常适用专门的longest prefix match算法,这会比本节的通用算法更快。
小结
想到正确的思路是一码事,写出正确的、经得起推敲的代码是另一码事。例如12.8.4用(x % 2 != 0)来判断int x是否为奇数,如果写成(x % 2 == 1)就是错的,因为x可能是负数,负数的取模运算的关窍见12.3。常见的错误还包括误用char的值作为数组下标(面试题目:统计文件中每个字符出现的次数),但是没有考虑char可能是负数,造成访问越界。有的人考虑到了char可能是负数,因此先强制转型为unsigned int再用作下标,这仍然是错的。正确的做法是强制转型为unsigned char再用作下标,这涉及C/C++整型提升的规则,就不详述了(如果是负数char转换成unsigned int,相当于把-1赋值给unsigned int,结果是最大的unsigned int值,太大了;而转换成unsigned char时,相当于把-1赋值给unsigned char,结果是最大的unsigned char值,即255)。这些细节往往是面试官的考察点(工作5年以来,作者面试过近百人,因此这番话是从面试官的角度说的)。本节给出的解法在正确性方面应该是没问题的;在效率方面,可以说在Big-O意义下是最优的,但不一定是运行最快的。
另外,面试题的目的可能就是让你动手实现一些STL算法,例如求两个有序集合的交集(set_intersection())、洗牌(random_shuffle())等等,这就不属于本节所讨论的范围了。从“算法”本身的难度上看,作者个人把STL algorithm分为三类,面试时要求手写的往往是第二类算法。
1.容易。即闭着眼睛一想就知道是如何实现的,自己手写一遍的难度跟strlen()和strcpy()差不多。这类算法基本上就是遍历一遍输入区间,对每个元素做些判断或操作,一个for循环就解决问题。一半左右的STL algorithm属于此类,例如for_each()、stransform()、accumulate()等等。
2.较难。知道思路,但是要写出正确的实现要考虑清楚各种边界条件。例如merge()(将两个已排序容器合并成一个有序的容器)、unique()、remove()、random_shuffle()(要考虑随机数生成器的状态空间,http://en.wikipedia.org/wiki/Fisher-Yates_shuffle#Potential_sources_of_bias)、lower_bound()、partition()等等,三成左右的STL algorithm属于此类。
3.难。要在一个小时内写出正确的、健壮的实现基本不现实,例如sort()(快速排序是本科生数据结构课上就有的内容,但是其工业强度的实现是足以在顶级期刊上发论文的)、nth_element()()、next_permutation(将容器中第N个元素放置在其正确的位置上,并保证该位置之前的元素都不大于它,该位置之后的元素都不小于它)、inplace_merge()等等,约有两成STL algorithm属于此类。
注意,“容易”级别的算法是指写出正确的实现很容易,但不一定意味着写出高效的实现也同样容易,例如std::copy()拷贝POD类型的效率可媲美memcpy(),这需要用一点模板技巧。
以上分类纯属个人主观看法,或许别人有不同的分类法,例如把remove()归入简单,把next_permutation()归入较难,把lower_bound()归入难等。














 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









