







接口类型是对其他类型行为的概括与抽象。通过使用接口,我们可以写出更灵活的函数,这些函数不用绑定在一个特定的类型实现上。
很多面向对象语言都有接口的概念,Go语言接口的独特之处是它是隐式实现。即,对于一个具体类型,无须声明类型实现了哪些接口,只要在类型里提供接口中的方法即可。这种设计让你无须改变已有类型的实现,就可以为这些类创建新接口,对于那些定义在你不能控制的包中的类型,这一点特别有用。
7.1 接口即约定
之前介绍的类型都是具体类型。具体类型指定了它所含数据的精确布局,还暴露了基于这个精确布局的内部操作。比如对于数值有算术操作,对于slice类型我们有索引、append、range等操作。具体类型还会通过所含的方法提供额外的能力。总之,如果你知道了一个具体类型的数据,你就精确地知道了它是什么以及它能干什么。
Go中还有另一种类型称为接口类型。接口是一种抽象类型,它没有暴露所含数据的布局或内部结构,当然也没有那些数据的操作,它所提供的仅仅是一些方法。如果你拿到一个接口类型的值,你无从知道它是什么,你仅仅能知道它能做什么,或更精确地将,它提供了哪些方法。
本书通篇使用了两个类似函数来实现字符串的格式化:fmt.Printf和fmt.Sprintf。前者把结果发到标准输出(标准输出其实是一个文件),后者把结果以string类型返回。格式化是两个函数中最复杂的部分,如果仅仅因为两个函数在输出方式上的细微差异,就需要把格式化部分在两个函数中各写一遍,那就太糟糕了。幸运的是,通过接口机制可以解决这个问题。其实,两个函数都封装了函数fmt.Fprintf,这个函数对结果实际输出到哪里毫不关心:
package fmt
func Fprintf(w io.Writer, format string, args ...interface{}) (int, error)
func Printf(format string, args ...interface{}) (int, error) {
return Fprintf(os.Stdout, format, args...)
}
func Sprintf(format string, args ...interface{}) string {
var buf bytes.Buffer
Fprintf(&buf, format, args...)
return buf.String()
}
Fprintf的前缀F指文件,表示格式化的输出会写入第一个实参所指代的文件。对于Printf,第一个实参就是os.Stdout,它属于*os.File类型。对于Sprintf,尽管第一个实参不是文件,但它模拟了一个文件:&buf就是一个指向内存缓冲区的指针,与文件类似,这个缓冲区也可以写入多个字节。
其实Fprintf的第一个形参也不是文件类型,而是io.Writer接口类型,其声明如下:
package io
// Writer接口封装了基础的写入方法
type Writer interface {
// Write从p向底层数据流写入len(p)个字节的数据
// 返回实际写入的字节数(0 <= n<= len(p))
// 如果没有写完,会返回遇到的错误
// 在Write返回n < len(p)时,err必须为非nil
// Write不允许修改p的数据,即使是临时修改
//
// 实现时不允许残留p的引用
Write(p []byte) (n int, err error)
}
io.Writer接口定义了Fprintf和调用者之间的约定。一方面,这个约定要求调用者提供的具体类型(比如*os.File或者*bytes.Buffer)包含一个与其签名和行为一致的Write方法。另一方面,这个约定保证了Fprintf能使用任何满足io.Writer接口的参数。Fprintf没有假定写入的是一个文件还是一段内存,而是写入一个可以调用Write函数的类型值。
因为fmt.Fprintf函数没有对具体操作的值做任何假设,而是仅仅通过io.Writer接口的约定来保证行为,所以第一个参数可以安全地传入一个只需要满足io.Writer接口的任意具体类型的值。一个类型可以自由地被另一个满足相同接口的类型替换,被称作可替换性(LSP里氏替换,即任何一个基类的对象都可以被其子类对象替换,而不影响程序的正确性)。这是一个面向对象的特征。
让我们通过一个新的类型来进行校验,下面*ByteCounter类型里的Write方法,仅仅统计写向它的字节长度,然后丢弃这些字节(在这个+=赋值语句中,让len§的类型和*c的类型的转换是必须的)。
// gopl.io/ch7/bytecounter
type ByteCounter int
func (c *ByteCounter) Write(p []byte) (int, error) {
*c += ByteCounter(len(p)) // convert int to ByteCounter
return len(p), nil
}
因为*ByteCounter满足io.Writer的约定,我们可以把它传入Fprintf函数中;Fprintf函数执行字符串格式化的过程不会去关注ByteCounter正确的累加结果的长度。
var c ByteCounter
c.Write([]byte("hello"))
fmt.Println(c) // "5", = len("hello")
c = 0 // reset the counter
var name = "Dolly"
fmt.Fprintf(&c, "hello, %s", name)
fmt.Println(c) // "12", = len("hello, Dolly")
除了io.Writer这个接口类型,还有一个对fmt包很重要的接口类型。Fprintf和Fprintln函数向类型提供了一种控制它们值输出的途径。给一个类型定义String方法,可以让它满足使用最广泛的接口之一的fmt.Stringer:
package fmt
// The String method is used to print values passed
// as an operand to any format that accepts a string
// or to an unformatted printer such as Print.
type Stringer interface {
String() string
}
后面将会解释fmt包怎么发现哪些值满足这个接口类型的。
7.2 接口类型
一个接口类型定义了一套方法,如果一个具体类型要实现该接口,那么必须实现接口类型中定义的所有方法。
io.Writer是一个广泛使用的接口,它负责所有可以写入字节的类型的抽象,包括文件、内存缓冲区、网络连接、HTTP客户端、打包器(archiver)、散列器(hasher)等。io包还定义了很多有用的接口。Reader就抽象了所有可以读取字节的类型,Closer抽象了所有可以关闭的类型,比如文件、网络连接(现在你大概已经注意到Go的单方法接口的命名约定了,即加上er后缀)。
package io
type Reader interface {
Read(p []byte) (n int, err error)
}
type Closer interface {
Close() error
}
另外,我们还可以通过组合已有接口得到新接口,如:
type ReadWriter interface {
Reader
Writer
}
type ReadeWriteCloser interface {
Reader
Writer
Closer
}
以上语法称为嵌入式接口,与嵌入式结构类似,让我们可以直接使用一个接口,而不用逐一写出这个接口包含的方法。如下,尽管不够简洁,但可以不同嵌入式来声明io.ReadWriter:
type ReadWriter interface {
Read(p []byte) (n int, err error)
Write(p []byte) (n int, err error)
}
也能混合使用两种方式:
type ReadWriter interface {
Read(p []byte) (n int, err error)
Writer
}
三种声明的效果是一致的。方法定义的顺序也是无意义的,真正有意义的只有接口的方法集合。
7.3 实现接口
如果一个类型实现了一个接口要求的所有方法,那么这个类型实现了这个接口。比如*os.File类型实现了io.Reader、Writer、Closer和ReaderWriter接口。*bytes.Buffer实现了Reader、Writer和ReaderWriter,但没有实现Closer,因为它没有Close方法。为了简化表述,Go程序员通常说一个具体类型“是一个(is a)”特定的接口类型,这其实代表着该具体类型实现了该接口。比如,*bytes.Buffer是一个io.Writer;*os.File是一个io.ReaderWriter。
接口的赋值规则很简单,仅当一个表达式实现了一个接口时,这个表达式才可以赋给该接口。所以:
var w io.Writer
w = os.Stdout // OK:*os.File有Write方法
// new返回创建的变量的指针
w = new(bytes.Buffer) // OK:*bytes.Buffer有Write方法
w = time.Second // 编译错误:time.Duration缺少Write方法
var rwc io.ReadWriteCloser
rwc = os.Stdout // OK:*os.File有Read、Write、Close方法
rwc = new(bytes.Buffer) // 编译错误:*bytes.Buffer缺少Close方法
当右侧表达式也是一个接口时,该规则也有效:
w = rwc // OK:io.ReadWriteCloser有Write方法
rwc = w // 编译错误:io.Writer缺少Close方法
进一步讨论前,我们先解释一下一个类型有某一个方法的具体含义。6.2节曾提到,对每一个具体类型T,部分方法的接收者是T,部分方法的接收者是*T。同时我们对类型T的变量直接调用*T的方法也是合法的,只要变量是可变的,编译器隐式地帮你完成了取地址操作。但这仅仅是一个语法糖,类型T并不拥有*T指针的方法。
举个例子,在6.5章中,IntSet类型的String方法的接收者是一个指针类型,所以我们不能在一个不能寻址的IntSet值上调用这个方法:
type IntSet { /* ... */ }
func (*IntSet) String() string
var _ = IntSet{}.String() // compile error: String requires *IntSet receiver
但我们可以在一个IntSet变量上调用这个方法:
var s IntSet
var _ = s.String() // OK: s is a variable and &s has a String method
然而,由于只有*IntSet类型有String方法,所以也只有*IntSet类型实现了fmt.Stringer接口:
var _ fmt.Stringer = &s // OK
var _ fmt.Stringer = s // compire error: IntSet lacks String method
就像信封封装和隐藏起来信件一样,接口类型封装和隐藏具体类型和它的值。即使具体类型有其他的方法,也只有接口类型暴露出来的方法会被调用到:
os.Stdout.Write([]byte("hello")) // OK: *os.File has Write method
os.Stdout.Close() // OK: *os.File has Close method
var w io.Writer
w = os.Stdout
w.Write([]byte("hello")) // OK: io.Writer has Writer method
w.Close() // compile error: io.Writer lacks Close method
更多方法的接口类型(如io.ReadWriter)相比更少方法的接口类型(如io.Reader),更多方法的接口类型会告诉我们更多关于它的值持有的信息,且对实现它的类型的要求更严格。对于interface{}类型,它没有任何方法,看上去好像没用,但实际上interface{}被称为空接口类型是不可或缺的。因为空接口类型对实现它的类型没有要求,所以我们可以将任意一个值赋给空接口类型。
var any interface{}
any = true
any = 12.34
any = "hello"
any = map[string]int{"one": 1}
any = new(bytes.Buffer)
本书前面的例子使用过空接口类型,它允许像fmt.Println或errorf函数接受任何类型的参数。
对于一个interface{}值,它可能持有任意类型,我们不能直接对它持有的值做操作,因为interface{}没有任何方法。我们会在7.10学到一种用类型断言来获取interface{}中值的方法。
判定是否实现接口只需比较具体类型和接口类型的方法,所以没有必要在具体类型的定义中声明这种关系。但偶尔在注释中标注也不坏。但对于程序来将,这不是必须的。以下定义在编译期断言一个*bytes.Buffer的值实现了io.Writer接口类型:
// *byte.Buffer must satisfy io.Writer
var w io.Writer = new(bytes.Buffer)
我们甚至不需要创建一个新变量(用nil即可),因为*bytes.Buffer的值,甚至nil通过(*bytes.Buffer)(nil)进行显式的转换也实现了这个接口。当然,既然我们不想引用w,我们可以把它替换为空白标识符。基于这两点,修改后的代码可以节省不少变量:
// *bytes.Buffer必须实现io.Writer
var _ io.Writer = (*bytes.Buffer)(nil)
非空的接口类型(比如io.Writer)通常由一个指针类型来实现,特别是当接口类型的一个或多个方法暗示会修改接收者的情形(比如Write方法)。一个指向结构的指针才是最常见的方法接收者。
指针类型不是实现接口的唯一类型,即使是那些包含了会改变接收者的方法的接口类型,也可由Go的其他引用类型来实现。基础类型也能实现方法,如我们会在7.4节见到的time.Duration类型,它实现了fmt.Stringer。
一个具体类型可以实现很多不相关的接口。比如一个程序管理或销售数字文化商品,如音乐、电影、图书。那么它可能定义了如下具体类型:

我们可以把感兴趣的每一种抽象都用一种接口类型来表示。一些属性是所有商品都具备的,如标题、创建日期、创建者列表(作者或艺术家)。
type Artifact interface {
Title() string
Creators() []string
Created() time.Time
}
其他的一些特性只对特定类型的文化产品才有。和文字排版特性相关的只有books和magazines,还有只有movies和TV剧集和屏幕分辨率有关:
type Text interface {
Pages() int
Words() int
PageSize() int
}
type Audio interface {
Stream() (io.ReadCloser, error)
RunningTime() time.Duration
Format() string // e.g., "MP3", "WAV"
}
type Video interface {
Stream() (io.ReadCloser, error)
RunningTime() time.Time
Format() string // e.g., "MP4", "WMV"
Resolution() (x, y int)
}
这些接口是一种有用的方式来分组相关的具体类型和表示他们之间的共同特点。如果我们发现我们需要以同样的方式处理Audio和Video,我们可以定义一个Streamer接口来代表它们之间相同的部分而不必对已经存在的类型做改变。
type Streamer interface {
Stream() (io.ReadCloser, error)
RunningTime() time.Duration
Format() string
}
一组具体类型基于它们的共同行为可以表示成一个接口类型。不像基于类的语言,它们一个类实现的接口集合需要显式定义,在Go中,我们可以在需要的时候定义一个新的抽象或有特定特点的组,而不需修改具体类型的定义。当具体的类型来自不同的作者时会特别有用。当然也确实没有必要在具体的类型中指出这些共性。
7.4 flag.Value接口
思考下面这个会休眠特定时间的程序:
// gopl.io/ch7/sleep
var period = flag.Duration("period", 1*time.Second, "sleep Period")
func main() {
flag.Parse()
fmt.Printf("Sleeping for %v...", *period)
time.Sleep(*period)
fmt.Println()
}
在它休眠前会打印出休眠的时间周期。fmt包调用time.Duration的String方法打印这个时间周期是以用户友好的注解方式,而不是一个纳秒数字:

默认,睡眠时间是1秒,但睡眠时间可通过-period命令行标志来控制。flag.Duration函数创建了一个time.Duration类型的标志变量(指代表命令行选项的变量),且允许用一些用户友好的方式来指定时长,包括与String方法相同的记录方法。这种对称的设计提供了良好的用户接口:
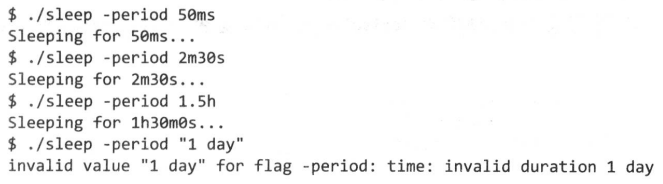
因为时间长度类的命令行标志被广泛使用,所以这个功能内置进了flag包。支持自定义类型不难,只需定义一个满足flag.Value接口的类型,其定义如下:
package flag
// Value接口代表存储在标志内的值
type Value interface {
String() string
Set(string) error
}
String方法用于格式化标志对应的值,可用于输出命令行帮助信息。由于有了该方法,因此每个flag.Value其实也是fmt.Stringer。Set方法解析了传入的字符串参数并更新标志值。可以认为Set方法是String方法的逆操作,两个方法使用相同的记法规格是良好的实践。
下面定义了celsiusFlag类型来允许在参数中使用摄氏或华氏温度。注意,celsiusFlag内嵌了一个Celsius类型(参考2.5节),所以已经有String方法了。为了满足flag.Value接口,只需再定义一个Set方法:
// gopl.io/ch7/tempconv
// *celsiusFlag满足flag.Value接口
package tempconv
type celsiusFlag struct { Celsius }
func (f *celsiusFlag) Set(s string) error {
var unit string
var value float64
fmt.Sscanf(s, "%f%s", &value, &unit) // 无须检查错误
switch unit {
case "C", "℃":
f.Celsius = Celsius(value)
return nil
case "F", "℉":
f.Celsius = FToC(Fahrenheit(value))
return nil
}
return fmt.Errorf("invalid temperature %q", s)
}
fmt.Sscanf函数用于从输入s解析一个浮点值(value)和一个字符串(unit)。尽管通常都必须检查Sscanf的错误结果,但这种情况下我们无需检查。因为如果出现错误,那么接下来的跳转条件没有一个会满足。
如下CelsuisFlag函数封装了上面的逻辑。这个函数返回一个Celsius指针,它指向嵌入在celsuisFlag变量f中的一个字段。Celsuis字段在标志处理过程中会发生变化(经由Set方法)。调用Var方法可以把这个标志加入到程序的命令行标记集合中,即全局变量flag.CommandLine(它是flag包中的一个变量,用于管理命令行参数和标志)。如果一个程序有非常复杂的命令行接口,那么单个全局变量flag.CommandLine就不够用了,需要有多个类似的变量来支撑。调用flag.CommandLine的Var方法(用于将一个已经存在的变量与一个命令行标志相关联)时会把*celsuisFlag实参赋给flag.Value形参,编译器会在此时检查*celsuisFlag类型是否有flag.Value所必需的方法。
// CelsiusFlag根据给定的name、默认值和使用方法
// 定义了一个Celsius标志,返回了标志值的指针
// 标志必须包含一个数值和一个单位,比如:"100C"
func CelsiusFlag(name string, value Celsius, usage string) *Celsius {
f := celsiusFlag{value}
// 将f与命令行标志(name)相关联,以便在命令行中设置温度值
flag.CommandLine.Var(&f, name, usage)
return &f.Celsius
}
现在可以在程序中使用这个新标志了:
// gopl.io/ch7/tempflag
var temp = tempconv.CelsiusFlag("temp", 20.0, "the temperature")
func main() {
flag.Parse()
fmt.Println(*temp)
}
接下来是一些典型的使用方法:
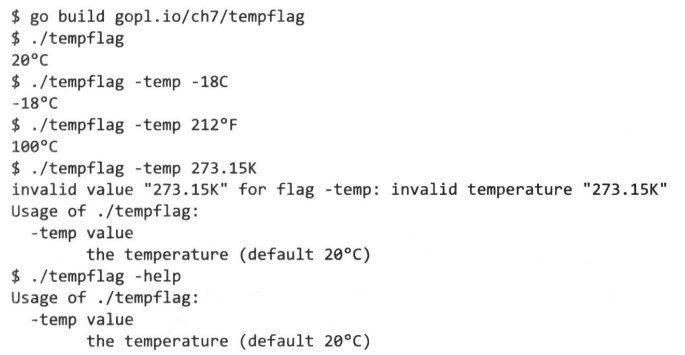
7.5 接口值
从概念上来讲,一个接口类型的值(简称接口值)有两个部分:一个具体类型和该具体类型的一个值。二者称为接口的动态类型和动态值。
对于Go这样的静态类型语言,类型仅仅是一个编译时的概念,所以类型不是一个值。在我们的概念模型中,用类型描述符来提供每个类型的具体信息,比如它的名字和方法。对于一个接口值,类型部分就用对应的类型描述符来表述。
如下四个语句中,变量w有三个不同的值(最初和最后是同一个值):
var w io.Writer
w = os.Stdout
w = new(bytes.Buffer)
w = nil
接下来让我们详细地查看一下在每个语句之后w的值和相关的动态行为。第一个语句声明了w,在Go中,变量总是初始化为一个明确的值,接口类型也不例外。对于一个接口的零值就是它的类型和值都是nil:
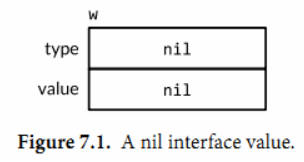
一个接口的值基于它的动态类型而被描述为空或非空,所以这是一个空的接口值。你可以通过w == nil或w != nil来判断接口值是否为空。调用一个空接口值上的任意方法都会产生panic:
w.Write([]byte("hello")) // panic: nil pointer dereference
第二个语句将一个*os.File类型的值赋给变量w。这个赋值过程调用了一个具体类型到接口类型的隐式转换,这和显式地使用io.Writer(os.Stdout)是等价的。这类转换不管是显式的还是隐式的,都会捕获它的操作数的类型和值。接口的动态类型被设置为指针类型*os.File的类型描述符,且它的动态值持有os.Stdout的拷贝;这个指向os.File指针变量的动态值代表进程的标准输出:
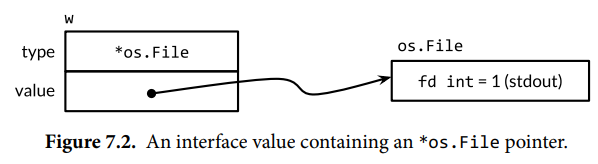
调用上面这个包含*os.File指针的接口值的Write方法,使得(*os.File).Write方法被调用。这个调用输出"hello"。
w.Write([]byte("hello")) // "hello"
通常在编译期,我们不知道接口值的动态类型是什么,所以一个接口上的调用必须使用动态分派(dynamic dispatch,是面向对象编程中的一个重要概念,也称为运行时多态性)。因为不是直接进行调用,所以编译器必须产生一段代码,用来获取类型描述符上名为Write的方法的地址,然后间接调用那个地址。调用时的接收者参数是接口动态值的拷贝,即os.Stdout。效果上与我们直接作以下调用相同:
os.Stdout.Write([]byte("hello")) // "hello"
第三个语句将一个*bytes.Buffer类型的值赋值给接口值。此时动态类型是*bytes.Buffer,且动态值是刚分配的缓冲区的指针:
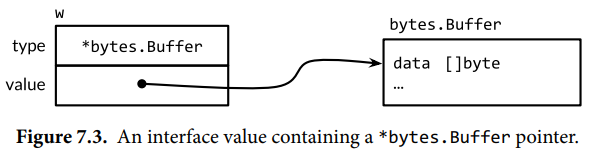
调用Write方法时的机制与前面相同:
w.Write([]byte("hello")) // writes "hello" to the bytes.Buffer
这次,类型描述符为*bytes.Buffer,因此(*bytes.Buffer).Write被调用,接收者是该缓冲区的地址。这个调用把字符串"hello"添加到缓冲区中。
最后,第四个语句将nil赋给了接口值,这个重置将接口的动态类型和动态值都设为nil值,把变量w恢复到和它之前定义时相同的状态。
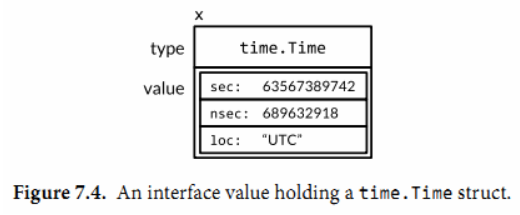
一个接口值可以持有任意大的动态值。例如,表示时间实例的time.Time类型,这个类型有几个对外不公开的字段。如果我们从time.Time上创建一个接口值:
var x interface{} = time.Now()
结果可能和下图相似。从概念上讲,不管接口值多大,动态值总是可以容下它(这只是一个概念上的模型,具体的实现可能会非常不同):
接口值可以使用==和!=来比较。两个接口值相等仅当它们都是nil值,或者它们的动态类型相同且动态值也根据这个动态类型的==操作相等。因为接口值是可比较的,所以它们可以用在map的键或作为switch语句的操作数。
然而,如果两个接口值的动态类型相同,但这个动态类型是不可比较的(如切片),将它们进行比较会失败并且panic:
var x interface{} = []int{1, 2, 3}
fmt.Println(x == x) // panic: comparing uncomparable type []int
接口外的类型要么是安全的可比较类型(如基本类型和指针),要么是完全不可比较的类型(如切片、map、函数),但是在比较接口值或包含了接口值的聚合类型时,我们要意识到潜在的panic。同样的风险也存在于使用接口作为map的键或switch的操作数。只能比较你非常确定它们的动态值是可比较类型的接口值。
在处理错误或调试过程中,得知接口值的动态类型是很有帮助的。所以我们使用fmt包的%T动作:
var w io.Writer
fmt.Printf("%T\n", w) // "<nil>"
w = os.Stdout
fmt.Printf("%T\n", w) // "*os.File"
w = new(bytes.Buffer)
fmt.Printf("%T\n", w) // "*bytes.Buffer"
在fmt包内部,使用反射来获取接口动态类型的名称。我们会在第12章学到反射。
7.5.1 注意:含有空指针的非空接口
空的接口值与仅仅动态值为nil的接口值不一样。
考虑如下程序,当debug设置为true时,主函数收集函数f的输出到一个缓冲区中:
const debug = true
func main() {
var buf *bytes.Buffer
if debug {
buf = new(bytes.Buffer) // 启用输出收集
}
f(buf) // 注意:微妙的错误
if debug {
// ...使用buf...
}
}
// 如果out不是nil,那么会向其写入输入的数据
func f(out io.Writer) {
// ...其它代码...
if out != nil {
out.Write([]byte("done!\n"))
}
}
当设置debug为false时,我们会觉得仅仅是不再收集输出,但实际上会导致程序在调用out.Write时崩溃:
if out != nil {
out.Write([]byte("done!\n")) // 宕机:对空指针取引用值
}
当main函数调用f时,它把一个类型为*bytes.Buffer的空指针赋给了out参数,所以out的动态值为空,动态类型为*bytes.Buffer,这表示out是一个包含空指针的非空接口(见图7-5),所以防御性检查out != nil仍然是true。
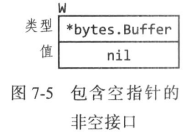
如前所述,动态分发机制决定了我们会调用(*bytes.Buffer).Write,不过这次接收者的值为空。对于某些类型,如*os.File,空接收值是合法的,但对于*bytes.Buffer则不行。方法尽管被调用了,但在尝试访问缓冲区时崩溃了。
问题在于,尽管一个空的*bytes.Buffer指针拥有的方法满足了该接口,但它并不满足该接口所需的一些行为。即,这个调用违背了(*bytes.Buffer).Write的一个隐式的前置条件,接收者不能为空。解决方案是把main函数中的buf类型修改为io.Writer,从而避免在最开始就把一个功能不完整的值赋给一个接口:
var buf io.Writer
if debug {
buf = new(bytes.Buffer) // 启用输出收集
}
f(buf) // OK
下面我们看以下Go标准库的一些重要接口。
7.6 使用sort.Interface来排序
与字符串格式化类似,排序也是一个在程序中广泛使用的操作。尽管一个最小的快排(Quicksort)只需15行左右,但一个健壮的实现长很多。我们无法想象在每次需要时都重新写一遍或复制一遍。
幸运的是,sort包提供了针对任意序列根据任意排列函数原地排序的功能。这样的设计其实并不常见。很多语言中,排序算法跟序列的类型绑定,而排序方式和具体类型元素关联。而Go的sort.Sort函数对序列和其中元素的布局无任何要求,它使用sort.Interface接口来指定通用排序算法和每个具体的序列类型之间的协议(contract)。这个接口的实现确定了序列的具体布局(通常是一个slice),以及元素期望的排序方式。
一个原地排序算法需要知道三个信息:序列长度、比较两个元素的含义、如何交换两个元素,所以sort.Interface接口就有三个方法:
package sort
type Interface interface {
Len() int
Less(i, j int) bool // i, j是序列元素的下标
Swap(i, j int)
}
为了对序列进行排序,我们需要定义一个实现了这三个方法的类型,然后对这个类型的一个实例调用sort.Sort函数。思考对一个字符串切片进行排序,这可能是最简单的例子了。下面是这个新的类型StringSlice和它的Len、Less、Swap方法:
type StringSlice []string
func (p StringSlice) Len() int { return len(p) }
func (p StringSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p StringSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
现在我们可以像下面这样对一个StringSlice类型(由names显式类型转换而来)来进行排序:
sort.Sort(StringSlice(names))
将names转换为StringSlice后,StringSlice的长度、容量、切片值都与names相同,且StringSlice还有排序所需的三个方法。
对字符串切片的排序很常用,所以sort包提供了StringSlice类型,也提供了Strings函数,该函数让上面的调用简化为sort.Strings(names)。
这里用到的技术很容易适配到其他排序顺序中,例如我们可以忽略大小写或含有的特殊字符。对于更复杂的排序,我们使用相同的方法,但会用更复杂的数据结构和更复杂地实现sort.Interface的方法。
我们下面对一个表格中的音乐播放列表进行排序。每个track都是单独的一行,列是这个track的属性,像艺术家、标题、时长。想象一个图形用户界面来呈现这个表格,且点击每一个属性的顶部都会使这个列表按照这个属性进行排序;再次点击相同属性的顶部会进行逆向排序。
下面的变量tracks包含了一个播放列表。每个元素都是一个指向Track的指针。尽管我们不用指针,而改为直接存储Tracks,后面的代码也能运行,考虑到sort函数要交换很多对元素,所以在元素是一个指针时代码运行速度会更快,毕竟,一个指针的大小只有一个字长,而一个完整的Track则需要8个甚至更多字。
package main
import "time"
type Track struct {
Title string
Artist string
Album string
Year int
Length time.Duration
}
var tracks = []*Track{
{"Go", "Delilah", "From the Roots Up", 2012, length("3m38s")},
{"Go", "Moby", "Moby", 1992, length("3m37s")},
{"Go Ahead", "Alicia Keys", "As I Am", 2007, length("4m36s")},
{"Ready 2 Go", "Martin Solveig", "Smash", 2011, length("4m24s")},
}
func length(s string) time.Duration {
d, err := time.ParseDuration(s)
if err != nil {
panic(s)
}
return d
}
以下printTracks函数将播放列表输出为一个表格。当然,一个图形界面肯定会更好,但这个例程使用的text/tabwriter包可以生成一个如下所示的干净整洁的表格。注意,*tabwriter.Writer满足io.Writer接口,它先收集所有写入的数据,在Flush方法调用时才格式化整个表格并且输出到os.Stdout。
func printTracks(tracks []*Track) {
const format = "%v\t%v\t%v\t%v\t%v\t\n"
tw := new(tabwriter.Writer).Init(os.Stdout, 0, 8, 2, ' ', 0)
fmt.Fprintf(tw, format, "Title", "Artist", "Album", "Year", "Length")
fmt.Fprintf(tw, format, "-----", "------", "-----", "----", "------")
for _, t := range tracks {
fmt.Fprintf(tw, format, t.Title, t.Artist, t.Album, t.Year, t.Length)
}
tw.Flush() // 计算各列宽度并输出表格
}
要按照Artist字段对播放列表排序,需要先定义一个新的slice类型,以及必需的Len、Less、Swap方法,正如StringSlice一样。
func (x byArtist) Len() int { return len(x) }
func (x byArtist) Less(i, j int) bool { return x[i].Artist < x[j].Artist }
func (x byArtist) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
要调用通用的排序例程,必须先把tracks转换为定义了排序规则的新类型byArtist:
sort.Sort(byArtist(tracks))
按照艺术家排序后,从printTracks生成的输出如下:

如果用户第二次请求“按照艺术家排序”,就需要把这些音乐反向排序。我们不需要定义一个新的byReverseArtist类型和对应的反向Less方法,因为sort包已经提供了一个Reverse函数,它可以把任意的排序反向。
按照艺术家对slice反向排序:
reverseByArtist := sort.Reverse(byArtist(tracks))
sort.Sort(reverseByArtist)
此时从printTracks生成的输出如下:

sort.Reverse函数值得仔细看一下,因为它使用了一个重要概念:组合(参考6.3节)。sort包定义了一个未导出的类型reverse,这个类型是一个嵌入了sort.Interface的结构。reverse的Less方法直接调用了内嵌的sort.Interface值的Less方法,但只交换传入的下标,就可以颠倒排序结果。
package sort
type reverse struct { Interface } // that is, sort.Interface
func (r reverse) Less(i, j int) bool { return r.Interface.Less(j, i) }
func Reverse(data Interface) Interface { return reverse(data) }
reverse的另外两个方法Len和Swap,由内嵌的sort.Interface隐式提供。所以导出函数Reverse返回一个包含原始sort.Interface值的reverse实例。
如果要按其他列来排序,就需要定义一个新类型,如byYear:
type byYear []*Track
func (x byYear) Len() int { return len(x) }
func (x byYear) Less(i, j int) bool { return x[i].Year < x[j].Year }
func (x byYear) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
把tracks按照sort.Sort(byYear(tracks))排序后,printTracks就可以输出一个按照年代排序的列表了:

对于每一类slice和每一种排序方式,都需要实现一个新的sort.Interface。如你所见,Len和Swap方法对所有slice类型都是一样的。下例中,具体类型customSort组合了一个slice和一个函数,让我们只写一个比较函数就可以定义一个新的排序。顺便说一下,实现sort.Interface的具体类型并不一定都是slice,比如customSort就是一个结构类型:
type customSort struct {
t []*Track
less func(x, y *Track) bool
}
func (x customSort) Len() int { return len(x.t) }
func (x customSort) Less(i, j int) bool { return x.less(x.t[i], x.t[j]) }
func (x customSort) Swap(i, j int) { x.t[i], x.t[j] = x.t[j], x.t[i] }
让我们定义一个多层排序函数,它第一个排序键是标题,第二个键是年,第三个键是时长。下面是该排序的函数,这个排序使用了匿名函数进行排序:
sort.Sort(customSort{tracks, func(x, y *Track) bool {
if x.Title != y.Title {
return x.Title < y.Title
}
if x.Year != y.Year {
return x.Year < y.Year
}
if x.Length != y.Length {
return x.Length < y.Length
}
return false
}})
下面是排序的结果:

尽管对长度为n的序列排序需要O(nlogn)次比较操作,检查一个序列是否已经有序至少需要n-1次比较。sort包的isSorted函数帮我们检查序列是否有序。像sort.Sort一样,它也使用sort.Interface对这个序列和其中元素的排序方式进行抽象,但是它从不会调用Swap方法:这段代码示范了IntsAreSorted和Ints函数在IntSlice类型上的使用:
package main
import (
"fmt"
"sort"
)
func main() {
values := []int{3, 1, 4, 1}
fmt.Println(sort.IntsAreSorted(values)) // "false"
sort.Ints(values)
fmt.Println(values) // "[1 1 3 4]"
fmt.Println(sort.IntsAreSorted(values)) // "true"
sort.Sort(sort.Reverse(sort.IntSlice(values)))
fmt.Println(values) // "[4 3 1 1]"
fmt.Println(sort.IntsAreSorted(values)) // "false"
}
为了使用方便,sort包为[]int、[]string、[]float64的正常排序提供了特定版本的函数和类型。对于其他类型,如[]int64或[]uint,尽管也很简单,还是依赖我们自己的实现。
7.7 http.Handler接口
本章继续讨论服务端API,以及作为基础的http.Handler接口。
// net/http
package http
type Handler interface {
ServeHTTP(w ResponseWriter, r *Request)
}
func ListenAndServe(address string, h Handler) error
ListenAndServe函数需要一个服务器地址,如“localhost:8000”,以及一个Handler接口的实例(用来接受所有的请求)。这个函数会一直运行,直到服务出错(或启动失败)时返回一个非空错误。
设想一个电子商务网站,使用数据库来存储商品和价格(以美元计价)的映射。如下程序将展示一个最简单的实现。它用一个map类型(命名为database)来代表仓库,再加上一个ServeHTTP方法来满足http.Handler接口。这个函数遍历整个map并且输出其中的元素:
package main
import (
"fmt"
"log"
"net/http"
)
type dollars float32
func (d dollars) String() string {
return fmt.Sprintf("$%.2f", d)
}
type database map[string]dollars
func (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) {
for item, price := range db {
fmt.Fprintf(w, "%s: %s\n", item, price)
}
}
func main() {
db := database{"shoes": 50, "socks": 5}
log.Fatal(http.ListenAndServe("localhost:8000", db))
}
如果启动服务器:

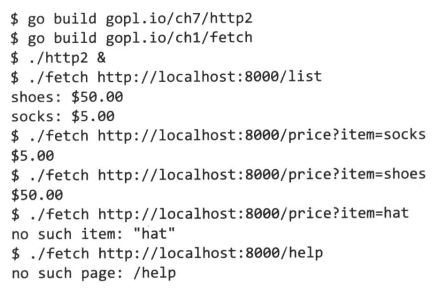
使用1.5节的fetch程序来连接服务器(也可以用Web浏览器),可以得到如下输出:
到现在为止,这个服务器只能列出所有商品,而且是完全不管URL,对每个请求都是如此。一个更加真实的服务器会定义多个不同URL,每个触发不同的行为。我们把现有功能的URL设为/list,再加上另外一个/price用来显示单个商品的价格,商品可以在请求参数中指定,如/price?item=socks:
func (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) {
switch req.URL.Path {
case "/list":
for item, price := range db {
fmt.Fprintf(w, "%s: %s\n", item, price)
}
case "/price":
item := req.URL.Query().Get("item")
price, ok := db[item]
if !ok {
w.WriteHeader(http.StatusNotFound) // 404
fmt.Fprintf(w, "no such item: %q\n", item)
return
}
fmt.Fprintf(w, "%s\n", price)
default:
w.WriteHeader(http.StatusNotFound) // 404
fmt.Fprintf(w, "no such page: %s\n", req.URL)
}
}
现在,处理函数基于URL的路径部分(req.URL.Path)来决定执行哪部分逻辑。如果处理函数不能识别这个路径,那么它就会调用w.WriteHeader(http.StatusNotFound)来返回一个HTTP错误。注意,这个调用必须在往w中写入内容前完成(http.ResponseWriter也是一个接口,它扩充了io.Writer,加了发送HTTP响应头的方法)。也可以使用http.Error这个工具错误来达到同样的目的:
msg := fmt.Sprintf("no such page: %s\n", req.URL)
http.Error(w, msg, http.StatusNotFound) // 404
对于/price的场景,它调用了URL的Query方法,把HTTP的请求参数解析为一个map,或更精确地讲,解析为一个multimap,它的类型是net/url包的url.Values(底层类型是map[string][]string,6.2.1节)。然后url.Values的Get方法找到第一个item请求参数,然后我们的代码里查询其对应的价格。如果商品没找到,则返回一个错误。
与新服务器的交互:
我们可以继续给ServeHTTP方法增加功能,但对于一个真实的应用,应当把每部分逻辑分到独立的函数或方法中去。某些相关的URL,比如几个图片文件的URL可能都是/images/*.png形式,为了处理它们,net/http包提供了一个请求多工转发器ServeMux,它可以把多个http.Handler组合成单个http.Handler。
对于更复杂的应用,一些ServeMux可以通过组合来处理更加错综复杂的路由需求。Go语言目前没有一个权威的Web框架,就像Ruby语言有Rails和python有Django。这并不是说这样的框架不存在,而是Go语言标准库中的构建模块就已经非常灵活以至于这些框架都是不必要的。此外,尽管在一个项目早期使用框架是非常方便的,但是它们带来额外的复杂度会使长期的维护更加困难。
以下程序中,我们创建一个ServeMux并且使用它将URL和相应处理/list和/price操作的handler联系起来,这些操作逻辑都已经被分到不同的方法中。然后我们在调用ListenAndServe函数时使用ServeMux为主要的handler。
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
db := database{"shoes": 50, "socks": 5}
mux := http.NewServeMux()
mux.Handle("/list", http.HandlerFunc(db.list))
mux.Handle("/price", http.HandlerFunc(db.price))
log.Fatal(http.ListenAndServe("localhost:8000", mux))
}
type dollars float32
func (d dollars) String() string {
return fmt.Sprintf("$%.2f", d)
}
type database map[string]dollars
func (db database) list(w http.ResponseWriter, req *http.Request) {
for item, price := range db {
fmt.Fprintf(w, "%s: %s\n", item, price)
}
}
func (db database) price(w http.ResponseWriter, req *http.Request) {
item := req.URL.Query().Get("item")
price, ok := db[item]
if !ok {
w.WriteHeader(http.StatusNotFound) // 404
fmt.Fprintf(w, "no such item: %q\n", item)
return
}
fmt.Fprintf(w, "%s\n", &price)
}
让我们关注这两个用于注册处理程序的两次mux.Handle调用。第一个调用中,db.list是一个方法值(参考6.4节),即如下类型的一个值:
func(w http.ResponseWriter, req *http.Request)
当调用db.list时,等价于以db为接收者调用database.list方法。所以db.list是一个实现了类似handler行为的方法,但由于db.list本身没有ServeHTTP方法(意思是db.list这个方法的类型不含ServeHTTP方法),因此它不满足http.Handler接口,不能直接传给mux.Handle。
表达式http.handleFunc(db.list)其实是类型转换,而不是函数调用。注意,http.HandleFunc是一个类型。它有如下定义:
// net/http
package http
type HandlerFunc func(w ResponseWriter, r *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
HandlerFunc演示了Go语言接口的不寻常的机制。HandlerFunc是一个函数类型,它含有方法且满足http.Handler接口所需的方法。HandlerFunc的ServeHTTP方法的行为就是调用它的底层函数。HandlerFunc相当于是一个适配器,让一个函数值满足一个接口,其中函数值和接口的唯一方法有相同的签名。实际上,这个技巧让一个类似database的单个类型,以多种方式满足了http.Handler接口:一次通过它的list方法,一次通过它的price方法。
由于像这样注册一个handler太常用了,ServeMux有一个HandleFunc方法为我们做以上注册,因此我们可以简化handler的注册:
mux.HandleFunc("/list", db.list)
mux.HandleFunc("/price", db.price)
一个程序中可以构造两个web服务器,它们监听不同的端口,定义不同的URLs,且分发到不同的handlers。仅仅只需要构造另一个ServMux,然后调用另一个ListenAndServe,两个服务器可以是并发存在的。但在大多数程序中,一个web服务器就足够了。另外,一个程序有多个HTTP handlers是很常见的,它们可能定义在不同的源文件里,把它们都显式注册到程序的一个ServeMux实例中很麻烦。
因此,为了便利,net/http提供了一个global的ServeMux实例,名为DefaultServeMux;并且提供了包级别的函数http.Handle和http.HandleFunc。为了使用DefaultServeMux作为服务器的handler,我们不需要将其传递给ListenAndServe函数,只需传nil即可。
从而,服务器的main函数可以简化为:
db := database{"shoes": 50, "socks": 5}
http.HandleFunc("/list", db.list)
http.HandleFunc("/price", db.price)
log.Fatal(http.ListenAndServe("localhost:8000", nil))
最后,一个重要的提醒:正如我们1.7节提到的,web服务器会在一个新goroutine中调用handler,因此,当访问其他goroutine也能访问的变量时,或其他请求也在调用相同handler时,handlers必须采取类似加锁的预防措施。我们会在接下来两章谈并发。
7.8 error接口
从本书的开始,我们一直在创建和使用神秘的、预先声明好的error类型值,而没有解释它实际上是什么。实际上,它只是一个接口类型,其中仅有一个返回错误信息的方法:
type error interface {
Error() string
}
最简单的创建一个error值的方式是调用errors.New,它返回一个带有指定错误信息的error值。整个errors包只有四行代码:
package errors
func New(text string) error { return &errorString{text} )
type errorString struct { text string }
func (e *errorString) Error() string { return e.text }
errorString的底层类型是一个结构体,而不是一个string,防止它被无意或有意地修改。用指针类型*errorString(而非errorString)满足(即实现该接口)error接口的原因是,每次调用New创建的都是不同的error实例(含义应该是,只有这样,相同错误信息也能被视为不同的错误,也本应视为不同的错误)。我们不想让类似io.EOF这样的用于特定情境的错误,与仅仅只是错误信息相同的error被当成是相等的:
fmt.Println(errors.New("EOF") == errors.New("EOF")) // "false"
调用errors.New不太常见,因为有一个方便的包裹函数fmt.Errorf,它同时还做了string格式化。我们在第五章中用过它几次。
package fmt
import "errors"
func Errorf(format string, args ...interface{}) error {
return errors.New(Sprintf(format, args...))
}
尽管*errorString可能是最简单的error类型(符合error接口的类型),但它并不是唯一一个error类型。例如,syscall包提供了Go的底层系统调用API。在很多平台上,syscall包都定义了符合error接口的数字类型Errno,在Unix平台,Errno的Error方法会在一个string表中进行错误码的string信息查找,就像下例:
package syscall
import "fmt"
// uintptr是一种无符号整数类型,其大小足以存储指针的位模式
type Errno uintptr // 操作系统错误码
// errors是一个数组,因为中括号中有内容,...表示数组大小取决于初始化值中的个数
var errors = [...]string{
1: "operation not permitted", // EPERM
2: "no such file or directory", // ENOENT
3: "no such process", // ESRCH
// ...
}
func (e Errno) Error() string {
if 0 <= int(e) && int(e) < len(errors) {
return errors[e]
}
return fmt.Sprintf("errno %d", e)
}
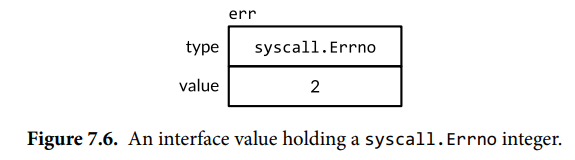
以下语句会创建一个接口值(接口值分为两部分,动态类型和动态值),该接口值中含有值为2的Errno类型,用来表示POSIX ENOENT的情形:
// syscall.Errno(2)是类型转换,转换后的类型Errno满足error接口
var err error = syscall.Errno(2)
fmt.Println(err.Error()) // "no such file or directory"
fmt.Println(err) // "no such file or directory"
上例中err的值如下图所示:
Errno是一种高效的表示方法,用来表示有限集合的系统调用错误码,并且它满足标准error接口。我们将在7.11中看到其他满足error接口的类型。
7.9 例子:表达式求值器
本节中,我们将创建一个简单算术运算的求值器。我们会使用一个名为Expr的接口,来表示这种语言中的任何表达式。现在,接口不需要任何方法,但我们稍后将会添加一些。
// An Expr is an arithmetic expression.
type Expr interface{}
我们的表达式语言由以下内容组成:浮点数字面值;二元操作符+-*/;一元操作符+x和-x;函数调用pow(x,y),sin(x),sqrt(x);像x和pi这样的变量;括号和标准的操作符优先级。所有的值都是float64类型的。以下是一些表达式例子:
sqrt(A / pi)
pow(x, 3) + pow(y, 3)
(F - 32) * 5 / 9
以下五个具体类型表示特定类型的表达式。Var代表一个变量的引用(我们将看到为什么它是导出的)。literal表示一个浮点数常量。unary和binary类型代表有一个或两个操作数的操作符表达式,操作数可以是任意的Expr类型。call代表函数调用,我们将限制它的fn字段只能是pow、sin、sqrt。
// A Var identifies a variable, e.g., x.
type Var string
// A literal is a numeric constant, e.g., 3.141.
type literal float64
// A unary represents a unary operator expression, e.g., -x.
type unary struct {
op rune // one of '+', '-'
x Expr
}
// a binary represents a binary operator expression, e.g., x+y.
type binary struct {
op rune // one of '+', '-', '*', '/'
x, y Expr
}
// A call represents a function call expression, e.g., sin(x).
type call struct {
fn string // one of "pow", "sin", "sqrt"
args []Expr
}
为了对一个含有变量的表达式求值,我们需要一个environment,它将变量名映射到值:
type Env map[Var]float64
我们也需要每个表达式都定义一个Eval方法来返回表达式在给定environment下的值。由于每个表达式都要提供这个方法,我们将其添加到Expr接口中。这个包只导出了Expr、Env、Var类型;用户可以不访问其他表达式类型的情况下使用求值器。
type Expr interface {
// Eval returns the value of this Expr in the environment env.
Eval(env Env) float64
}
具体的Eval方法如下。Var的Eval方法执行对environment的查找,如果变量未定义则返回0。literal的Eval方法简单地返回它表示的字面值:
func (v Var) Eval(env Env) float64 {
return env[v]
}
func (l literal) Eval(_ Env) float64 {
return float64(l)
}
unary和binary的Eval递归地计算它们操作数,然后将操作符op应用到操作数的计算结果。我们不把除0或除无穷当成错误,因为它们会产生一个结果,尽管结果是无限。call的Eval会对它的参数求对应的pow、sin、sqrt值,方法是调用math包里的对应函数:
func (u unary) Eval(env Env) float64 {
switch u.op {
case '+':
return +u.x.Eval(env)
case '-':
return -u.x.Eval(env)
}
panic(fmt.Sprintf("unsupported unary operator: %q", u.op))
}
func (b binary) Eval(env Env) float64 {
switch b.op {
case '+':
return b.x.Eval(env) + b.y.Eval(env)
case '-':
return b.x.Eval(env) - b.y.Eval(env)
case '*':
return b.x.Eval(env) * b.y.Eval(env)
case '/':
return b.x.Eval(env) / b.y.Eval(env)
}
panic(fmt.Sprintf("unsupported binary operator: %q", b.op))
}
func (c call) Eval(env Env) float64 {
switch c.fn {
case "pow":
return math.Pow(c.args[0].Eval(env), c.args[1].Eval(env))
case "sin":
return math.Sin(c.args[0].Eval(env))
case "sqrt":
return math.Sqrt(c.args[0].Eval(env))
}
panic(fmt.Sprintf("unsupported function call: %s", c.fn))
}
其中一些Eval方法可能会失败。例如,一个call表达式中可能会遇到未知的函数或错误的参数数量。以一个非法的操作符(如!或<)创建一个unary或binary表达式(尽管下面的Parse函数不会这么做)。这些错误导致Eval panic。其他错误,如求一个没有在environment中的Var值,仅仅只是导致Eval返回错误的结果(即0)。所有这些错误都可以在求值前通过检查Expr而检测出来。这将会是Check方法的所做的,下面将会展示它。
下面的TestEval函数用来测试求值器。它使用testing包,我们将在第11章介绍这个包,但现在,知道调用t.Errorf会报告一个错误就足够了。此函数会在一个有三种表达式的表上循环,会为它们输入不同的environment。第一个表达式给定圆的面积A,计算圆的半径。第二个计算两个变量的立方和。第三个将华氏度转换为摄氏度。
func TestEval(t *testing.T) {
tests := []struct {
expr string
env Env
want string
}{
{"sqrt(A / pi)", Env{"A": 87616, "pi": math.Pi}, "167"},
{"pow(x, 3) + pow(y, 3)", Env{"x": 12, "y": 1}, "1729"},
{"pow(x, 3) + pow(y, 3)", Env{"x": 9, "y": 10}, "1729"},
{"5 / 9 * (F - 32)", Env{"F": -40}, "-40"},
{"5 / 9 * (F - 32)", Env{"F": 32}, "0"},
{"5 / 9 * (F - 32)", Env{"F": 212}, "100"},
}
var prevExpr string
for _, test := range tests {
// Print expr only when it changes.
if test.expr != prevExpr {
fmt.Printf("\n%s\n", test.expr)
prevExpr = test.expr
}
expr, err := Parse(test.expr)
if err != nil {
t.Error(err) // parse error
continue
}
got := fmt.Sprintf("%.6g", expr.Eval(test.env))
fmt.Printf("\t%v => %s\n", test.env, got)
if got != test.want {
t.Errorf("%s.Eval() in %s = %q, want %q\n",
test.expr, test.env, got, test.want)
}
}
}
对于表中的每个条目,会解析这个表达式,在environment下对其求值,然后打印结果。我们这里没有地方展示Parse函数,但你可以用go get来下载这个包(本书代码所在包gopl.io),Parse函数就在包中。
用命令go get gopl.io下载包时,可能会遇到以下报错:go: modules disabled by GO111MODULE=off; see 'go help modules'。这是因为没有启动模块支持,运行以下命令开启模块支持:
go env -w GO111MODULE=on
然后再运行命令,可能会遇到以下报错:
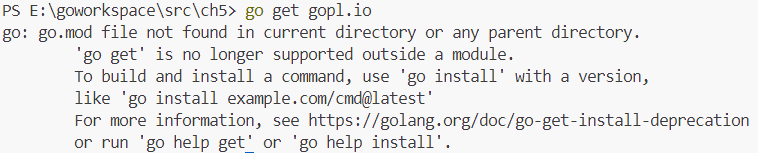
这是由于在当前目录或任何父目录中找不到go.mod文件引起的,这表示当前工作目录不是go模块。在Go 1.17及更高版本中,go get命令不再支持在非go模块中使用。解决方法是在go模块中执行该命令,如果想新建一个go模块,可用以下命令:go mod init <module-name>,这将在当前目录下创建一个新的go.mod文件,从而将当前目录初始化为一个Go模块所在目录。然后再运行go get命令,会在当前目录下得到一个go.sum文件,其中记录了当前项目(模块)所依赖的每个模块的版本信息以及其哈希值。而下载的模块代码会在$GOPATH/pkg目录下。
go test命令(11.1)运行一个包的测试:
go test -v gopl.io/ch7/eval
-v标志会打印出test的输出,对于像这次这样的成功的测试,一般输出就不显示了。下面是测试中fmt.Printf语句输出的内容:

到现在为止所有的输入都是合法的,但实际中并不总是这样。即使是在解释性语言中,通过语法检查来发现静态错误(不用运行程序也能检测出来的错误)也是很常见的。通过分离静态检查和动态检查,我们可以更快地发现错误,并且不用每次求值前都进行动态检查(而是只进行一次静态检查)。
我们给Expr接口加上另一个Check方法,它用于在表达式树上检查静态错误。它的vars参数稍后再解释。
type Expr interface {
Eval(env Env) float64
// Check方法报告表达式中的错误,并把检查的表达式中的变量加入vars中
Check(vars map[Var]bool) error
}
具体的Check方法如下。literal和Var的求值不可能出错,所以Check方法返回nil。unary和binary的Check方法先检查操作符是否合法,再递归检查操作数。call的Check方法先检查函数是否是已知的,然后检查参数个数是否正确,最后递归检查每个参数。
func (v Var) Check(vars map[Var]bool) error {
vars[v] = true
return nil
}
func (literal) Check(vars map[Var]bool) error {
return nil
}
func (u unary) Check(vars map[Var]bool) error {
if !strings.ContainsRune("+-", u.op) {
return fmt.Errorf("unexpected unary op %q", u.op)
}
return u.x.Check(vars)
}
func (b binary) Check(vars map[Var]bool) error {
if !strings.ContainsRune("+-*/", b.op) {
return fmt.Errorf("unexpected binary op %q", b.op)
}
if err := b.x.Check(vars); err != nil {
return err
}
return b.y.Check(vars)
}
var numParams = map[string]int{"pow": 2, "sin": 1, "sqrt": 1}
func (c call) Check(vars map[Var]bool) error {
arity, ok := numParams[c.fn]
if !ok {
return fmt.Errorf("unknown function %q", c.fn)
}
if len(c.args) != arity {
return fmt.Errorf("call to %s has %d args, want %d",
c.fn, len(c.args), arity)
}
for _, arg := range c.args {
if err := arg.Check(vars); err != nil {
return err
}
}
return nil
}
下面分两列展示了一些有错误的输出,以及它们触发的错误。Parse函数(没有展示出来)报告了语法错误,Check方法报告了语义错误。

Check方法的输入是一个Var集合,它用来收集在表达式中发现的变量名。必须把每个变量都放到environment中,求值器才能成功求值。逻辑上讲,vars参数是Check方法的结果而非输入参数(即值-结果参数),但由于Check方法是递归调用的,因此使用参数更加方便。调用方在最初调用时需要提供一个空集合。
在3.2节中,我们绘制了函数f(x, y),不过函数是编译时指定的。既然我们可以对字符串形式的表达式进行解析、检查、求值,那么就可以构建一个Web应用,在运行时从客户端接收一个表达式,并绘制函数的曲面图。可以使用vars集合来检查表达式是一个只有两个变量x、y的函数(为了简单起见,还提供了半径r,所以实际上是3个变量)。使用Check方法来拒绝掉不规范的表达式,避免了接下来的40000次求值中重复检查(4个象限中100×100的格子,指的是不用再每次求值前都检查一遍)。
下面的parseAndCheck函数组合了解析和检查步骤:
// gopl.io/ch7/surface
import "gopl.io/ch7/eval"
func parseAndCheck(s string) (eval.Expr, error) {
if s == "" {
return nil, fmt.Errorf("empty expression")
}
expr, err := eval.Parse(s)
if err != nil {
return nil, err
}
vars := make(map[eval.Var]bool)
if err := expr.Check(vars); err != nil {
return nil, err
}
for v := range vars {
if v != "x" && v != "y" && v != "r" {
return nil, fmt.Errorf("undefined variable: %s", v)
}
}
return expr, nil
}
要构造完这个Web应用,仅需增加下面的plot函数,其函数签名与http.HandlerFunc类似:
func plot(w http.ResponseWriter, r *http.Request) {
r.ParseForm()
expr, err := parseAndCheck(r.Form.Get("expr"))
if err != nil {
http.Error(w, "bad expr: "+err.Error(), http.StatusBadRequest)
return
}
w.Header().Set("Content-Type", "image/svg+xml")
surface(w, func(x, y float64) float64 {
r := math.Hypot(x, y) // 与(0,0)之间的距离
return expr.Eval(eval.Env{"x": x, "y": y, "r": r})
})
}
plot函数解析并检查HTTP请求中的表达式,并用它来创建一个有两个变量的匿名函数。这个匿名函数与原始曲面图绘制程序surface的f参数由同样的签名,且能对用户提供的表达式进行求值。environment中定义了x、y、r。最后,plot调用了surface函数,surface函数来自gopl.io/ch3/surface中的main函数,略作修改,加了参数用于绘制函数和输出用的io.Writer,原始版本直接使用了函数f和os.Stdout。图7-7显示了用这个程序绘制的三张曲面图:

7.10 类型断言
类型断言是一个作用在接口值上的操作,写出来类似于x.(T),其中x必须是一个接口类型的表达式(注意,接口类型由两部分组成,动态值和动态类型),而T是一个类型(称为断言类型)。类型断言会检查作为操作数的动态类型是否满足指定的断言类型。
这里有两个可能。首先,如果断言类型T是一个具体类型,那么类型断言会检查x的动态类型是否就是T。如果检查成功,类型断言的结果就是接口类型x的动态值,该结果的类型自然就是T。换句话说,具体类型的类型断言会从操作数(即接口类型x)中提取出值(动态值)。如果检查失败,则操作会产生panic。例如:
var w io.Writer
w = os.Stdout
f := w.(*os.File) // success: f == os.Stdout,接口值w中保存的是一个具体类型*os.File的值
c := w.(*byte.Buffer) // panic: interface holds *os.File, not *bytes.Buffer
其次,如果断言类型T是一个接口类型,那么类型断言检查x的动态类型是否满足T接口。如果检查成功,动态值不会像具体类型那样被提取出来;结果仍然是一个接口值,结果的动态类型和动态值都还保持不变(与x相同),但结果的接口类型是T(即,接口值里的动态值和动态类型不变,但接口值本身的类型被修改为了T接口类型,别忘了,我们现在讨论的是T为一个接口类型的情况)。换句话说,对于接口类型的类型断言改变了表达式(表达式指的是x)的类型,使另一个不同的方法类型集(通常是x的方法集合的超集,但也不一定,只要接口类型的动态类型有断言类型所表示的接口中的方法就可以,也可以减少)可以被访问,且结果类型值中的动态值和动态类型与x中的相同。
如下类型断言代码中,w和rw都持有os.Stdout,它们的动态类型都是*os.File,但w作为io.Writer仅暴露了Write方法,而rw还暴露了它的Read方法。
var w io.Writer
w = os.Stdout
rw := w.(io.ReadWriter) // 成功:*os.File有Read和Write方法
w = new(ByteCounter)
rw.(io.ReadWriter) // 崩溃:*ByteCounter没有Read方法
// 注:减少方法集的内容也可以
var rw io.ReadWriter
rw = os.Stdout
w := rw.(io.Writer) // 成功:*os.File有Write方法,但不常用,因为直接用赋值就可以
以上代码中,如果直接用w来访问os.Stdout的Read方法,是访问不了的,因为w是一个接口类型,它的动态类型是io.Writer,不能访问Raed方法。而rw可以访问Read方法。a := os.Stdout中的a不是接口类型,而是*io.File类型,也可以访问Read方法,尽管os.Stdout有Read方法,调用它也不能产生预期的结果,因为os.Stdout是设计来输出的,而不是读的。
无论哪种类型作为断言类型,如果操作数(指x.(T)中的x)是一个空接口值(指接口值,),类型断言都失败。很少需要从一个接口类型向一个要求更宽松(即所含方法更少,而且是原接口类型的方法的子集)的类型做类型断言,因为它与赋值的行为一致(当x是nil时不一致,赋值不会报错,而类型断言会报错)。
w = rw // ioReadWriter is assignment to io.Writer
w = rw.(io.Writer) // fails only if rw == nil
我们经常无法确定一个接口值的动态类型,这是就需要检测它是否是某一特定类型。如果类型断言出现在需要两个结果的赋值表达式中(如下例),那么断言不会在失败时panic,而是会多返回一个布尔型的值来指示断言是否成功:
var w io.Writer = os.Stdout
f, ok := w.(*os.File) // 成功:ok,f == os.Stdout
b, ok := w.(*bytes.Buffer) // 失败:!ok,b == nil
按照惯例,一般把类型断言的第二个返回值赋给一个名为ok的变量。如果操作失败,ok为false,而第一个返回值为断言类型的零值,上例中是*bytes.Buffer类型的空指针。
ok返回值通常马上就用于判断。下面if表达式的扩展形式可以让我们写出更紧凑的代码:
if f, ok := w.(*os.File); ok {
// ...使用f...
}
当类型断言的操作数(即x)是一个变量时,有时你会看到返回值的名字与操作数变量名一致,原有的值就被新的返回值掩盖了,比如:
if w, ok := w.(*os.File); ok {
// ...use w...
}
7.11 使用类型断言来识别错误
考虑os包中的文件操作可能返回的错误集合,I/O会因为很多原因失败,但有三类原因通常必须单独处理:文件已存在(创建操作)、文件未找到(读取操作)、权限不足。os包提供了三个帮助函数用来对错误进行分类:
package os
func IsExist(err error) bool
func IsNotExist(err error) bool
func IsPermission(err error) bool
一个不成熟的实现会通过检查错误消息是否包含特定的字符串来做判断:
func IsNotExist(err error) bool {
// 注意:不健壮
return strings.Contains(err.Error(), "file does not exit")
}
但由于处理IO错误的逻辑会随着平台的变化而变化,因此这种方法很不健壮,同样的错误可能会用完全不同的错误消息来报告。检查错误消息是否包含特定的字符串,这种方法在单元测试中还算够用,但对于生产级的代码则远远不够。
一个更可靠的方法是用专门的类型来表示结构化的错误值。os包定义了一个PathError类型来表示与一个文件路径相关的操作上发生错误(比如Open或Delete),一个类似的LinkError错误用来表述与两个文件路径相关的操作上发生错误(如Symlink和Rename)。下面是os.PathError的定义:
package os
// PathError记录了错误以及错误相关的操作和文件路径
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string {
return e.Op + " " + e.Path + ": " + e.Err.Error()
}
很多客户端忽略了PathError,改用一种统一的方法来处理所有的错误,即调用Error方法。PathError的Error方法拼接了所有的字段,而PathError的结构保留了错误的各种底层字段。对于需要区分错误类型的客户端,可以使用类型断言来检查错误的特定类型,这些类型包含的细节远远多余一个简单的字符串。
_, err := os.Open("/no/such/file")
fmt.Println(err) // "open /no/such/file: No such file or directory"
// 相比%v,%#v会输出类型和该类型的结构信息
fmt.Println("%#v\n", err)
// 输出:
// &os.PathError{Op:"open", Path:"/no/such/file", Err:0x2}
下面是之前三个判断错误类型的帮助函数的工作方式。比如,如下所示的IsNotExist判断错误是否等于syscall.ENOENT(7.8节),或是否等于os.ErrNotExist(参见5.4.2节的io.EOF),或者是否是一个*PathError(它里面的err字段中的错误是以上两种错误之一)。
var ErrNotExist = errors.New("file does not exist")
// IsNotExist返回一个布尔值,该值表明err是否是已知的代表文件或目录不存在的错误
// ErrNotExist和syscall.ENOENT是已知的表示文件或目录不存在的错误
func IsNotExist(err error) bool {
if pe, ok := err.(*PathError); ok {
err = pe.Err
}
return err == syscall.ENOENT || err == ErrNotExist
}
实际使用该函数:

当然,如果错误消息已被fmt.Errorf这类方法合并到一个字符串中,那么PathError的结构信息就丢失了。错误区分通常在失败操作发生时马上处理,然后再将错误传播给调用者。
7.12 通过接口类型断言来查询特性
下面这段代码的逻辑类似于net/http包中的Web服务器向客户端响应诸如"Content-type:text/html"这样的HTTP头字段。io.Writer w代表HTTP响应,写入的字节最终会发到某人的Web浏览器上。
func writeHeader(w io.Writer, contentType string) error {
if _, err := w.Write([]byte("Content-type: ")); err != nil {
return err
}
if _, err := w.Write([]byte(contentType)); err != nil {
return err
}
// ...
}
因为Write方法需要一个字节slice,而我们想写入的是一个字符串,所以[]byte(…)转换就是必需的。这种转换需要进行内存分配和内存复制,但复制后的内存又会被马上抛弃。让我们假设这是Web服务器的核心部分,且性能分析表明这个内存分配导致性能下降。我们能否避开内存分配呢?
从io.Writer接口我们能知道w可以写入字节slice。但如果我们深入net/http包查看,可以看到w对应的动态类型还支持一个能高效写入字符串的WriteString方法,这个方法避免了临时内存的分配和复制(这个有点盲目猜测,但很多实现了io.Writer的类也有WriteString方法,比如*bytes.Buffer、*os.File、*bufio.Write)。
我们无法假定一个io.Writer w有WriteString方法。但可以定义一个新接口,这个接口只包含WriteString方法,然后使用类型断言来判断w的动态类型是否满足这个新接口。
// writeString将s写入w
// 如果w有WriteString方法,那么将直接调用该方法
func writeString(w io.Writer, s string) (n int, err error) {
type stringWriter interface {
WriteString(string) (n int, err error)
}
if sw, ok := w.(stringWriter); ok {
return sw.WriteString(s) // 避免了内存复制
}
return w.Write([]byte(s)) // 分配了临时内存
}
func writeHeader(w io.Writer, contentType string) error {
if _, err := writeString(w, "Content-type: "); err != nil {
return err
}
if _, err := writeString(w, contentType); err != nil {
return err
}
// ...
}
为了避免代码重复,我们把检查挪到了工具函数writeString中。实际上,标准库提供了io.WriteString函数,它为我们做了上例中writeString函数的检查,这也是向io.Writer写入字符串的推荐做法。标准库中的io.WriteString函数如下:
// StringWriter is the interface that wraps the WriteString method.
type StringWriter interface {
WriteString(s string) (n int, err error)
}
// WriteString writes the contents of the string s to w, which accepts a slice of bytes.
// If w implements [StringWriter], [StringWriter.WriteString] is invoked directly.
// Otherwise, [Writer.Write] is called exactly once.
func WriteString(w Writer, s string) (n int, err error) {
if sw, ok := w.(StringWriter); ok {
return sw.WriteString(s)
}
return w.Write([]byte(s))
}
这个例子中,比较古怪的地方是,没有一个标准的接口定义了WriteString方法且指定它应满足的规范。进一步讲,一个具体的类型是否满足stringWriter接口仅仅由它拥有的方法来决定,而不是这个类型与一个接口类型之间的一个关系声明。这意味着上面的技术依赖一个假定,即如果一个类型满足以下接口,那么WriteString(s)必须与Write([]byte(s))方法功能相同:
interface {
io.Writer
WriteString(s string) (n int, err error)
}
尽管io.WriteString文档中提到了这个假定,但在调用它的函数的文档中就很少提到这个假定了。给一个特定类型多定义一个方法,就隐式地接受了一个特性约定(即满足了一个接口)。Go语言的初学者,特别是那些具有强类型语言背景的人,会对这种缺乏显式约定的方式感到不安,但在实践中很少产生问题。撇开空接口interface{}不谈,很少有因为无意识的巧合导致错误的接口匹配。
前面的writeString函数使用类型断言来判定一个更普适接口类型的值是否满足一个更专用的接口类型(普适指的是传入的都是io.Writer,专用指的是可能它同时还满足io.StringWriter),如果满足,则可以使用后者所定义的方法。这种技术不仅适用于io.ReadWriter这种标准接口,还适用于stringWriter这种自定义类型。
这个方法也用在了fmt.Printf中,用于从通用类型中识别出error或者fmt.Stringer。在fmt.Fprintf内部,有一步是把单个操作数转换为一个字符串,如下所示:
package fmt
func formatOneValue(x interface{}) string {
if err, ok := x.(error); ok {
return err.Error()
}
if err, ok := x.(Stringer); ok {
return str.String()
}
// ...所有其他类型...
}
如果x满足这两种接口中的一个,就直接确定格式化方法。如果不满足,默认处理部分大致会使用反射来处理所有其他类型,详细情况在第12章讨论。
再说一次,上面的代码给出了一个假定,任何有String方法的类型都满足了fmt.Stringer的约定,即把类型转化为一个适合输出的字符串。
7.13 类型分支
接口有两种不同的风格。第一种风格下,典型的比如io.Reader、io.Writer、fmt.Stringer、sort.Interface、http.Handler、error,接口上的各种方法突出了满足这个接口的具体类型之间的相似性,但隐藏了各个具体类型的布局和各自特有的功能。这种风格强调了方法,而不是具体类型。
第二种风格则充分利用了接口值能容纳各种具体类型的能力,它把接口作为这些类型的联合(union)来使用。类型断言用来在运行时区分这些类型并分别处理。在这种风格中,强调的是满足这个接口的具体类型,而不是这个接口的方法(何况经常没有),也不注重信息隐藏。我们把这种风格的接口使用方式称为可识别联合(discriminated union)。
如果你对面向对象编程很熟悉,那么你就知道这两种风格分别对应子类型多态(subtype polymorphism,将子类的实例视为其父类的实例,从而可以使用父类定义的接口来操作子类的对象,代码可以编写为操作抽象基类或接口,而不必关心实际的具体子类,对应第一种风格,即强调的是接口上的方法,而不是具体类型的布局和特有功能)和特设多态(ad hoc polymorphism,通过函数重载或运算符重载来实现的,允许在同一作用域中使用相同的名称但具有不同参数或操作的函数,对应第二种风格,强调的是满足接口的具体类型,而不是接口的方法),当然这些名词并不重要。本章其余部分将结合示例对第二种风格的接口进行详解。
Go语言的数据库SQL查询API允许我们干净地分离查询中的不变部分和可变部分。一个示例客户端如下:
func listTracks(db sql.DB, artist string, minYear, maxYear int) {
result, err := db.Exec(
"SELECT * FROM tracks WHERE artist = ? AND ? <= year AND year <= ?",
artist, minYear, maxYear)
// ...
}
Exec方法把查询字符串中的每一个“?”替换为与相应参数值对应的SQL字面量,这些参数可能是布尔型、数字、字符串、nil。通过这种方式构造请求可以帮助避免SQL注入攻击,攻击者通过在输入数据中加入不恰当的引号来控制你的查询。在Exec的实现代码中,可以发现一个类似下例的函数,它将每个参数值转换为对应的SQL字面量。
func sqlQuote(x interface{}) string {
if x == nil {
return "NULL"
} else if _, ok := x.(int); ok {
return fmt.Sprintf("%d", x)
} else if _, ok := x.(uint); ok {
return fmt.Sprintf("%d", x)
} else if b, ok := x.(bool); ok {
if b {
return "TRUE"
}
return "FALSE"
} else if s, ok := x.(string); ok {
return sqlQuoteString(s) // (not shown)
} else {
panic(fmt.Sprintf("unexpected type %T: %v", x, x))
}
}
一个switch语句可以把包含一长串值相等比较的if-else语句简化掉。类似地,一个类型分支(type switch)语句可以简化一长串的类型断言if-else语句。
类型分支的最简单形式与普通分支语句类似,两个的差别是操作数改为x.(type)(注意,这里直接写关键词type,而不是一个特定类型),每个分支是一个或多个类型。类型分支的分支判定基于接口值的动态类型,其中nil分支会在x == nil时才匹配,而default分支则在其他分支都不满足时才运行。sqlQuote的类型分支如下:
switch x.(type) {
case nil: // ...
case int, uint: // ...
case bool: // ...
case string: // ...
default: // ...
}
与普通的switch(参考1.8节)类似,分支是按顺序排判定的,当一个分支符合时,对应的代码会执行。分支的顺序在一个或多个分支是接口类型时很重要,因为有可能两个分支都满足。default分支的位置是无关紧要的。另外,类型分支不允许使用fallthrough。
注意,在原来的代码中,bool和string分支的逻辑需要访问由类型断言提取出来的原始值。这个需求比较典型,所以类型分支语句也有一种扩展形式,它用来把每个分支中提取出来的原始值绑定到一个新的变量:
switch x := x.(type) { /* ... */ }
这里把新的变量也命名为x,与类型断言类似,重用变量名也很普遍。与switch语句类似,类型分支也隐式创建了一个词法块,所以声明一个新变量叫x并不与外部块中的变量x冲突。每个分支也会隐式创建各自的语法块。
用类型分支重写后的sqlQuote更加清晰易读了:
func sqlQuote(x interface{}) string {
switch x := x.(type) {
case nil:
return "NULL"
case int, uint:
return fmt.Sprintf("%d", x) // 这里x的类型为interface{}
case bool:
if x {
return "TRUE"
}
return "FALSE"
case string:
return sqlQuoteString(x) // (not shown)
default:
panic(fmt.Sprintf("unexpected type %T: %v", x, x))
}
}
在这个版本中,在case后只有一个类型的分支块内,变量x的类型都与该分支的类型一致。比如,在bool分支中x的类型是bool。在case后有多个类型的分支块内,x的类型与switch的操作数一致,在这个例子中就是interface{}。如果多个分支执行的代码一致,比如int和uint,类型分支可以很方便地组合它们。
尽管sqlQuote支持任一类型的实参,但仅当实参类型能符合类型分支中的一个时才能正常结束,对于其他情况会panic并抛出一条“unexpected type”消息。表面上x的类型是interface{},实际上我们把它当做int、uint、bool、string、nil的一个可识别联合。
7.14 例子:基于标记的XML解析
4.5节展示了如何用encoding/json包的Marshal和Unmarshal函数来把JSON文档(JSON document,即JSON编码后的串)解析为GO语言的数据结构。encoding/xml包提供了一个相似的API。当需要构造一个完整文档树(document tree,在计算机科学中,文档通常被组织成树形结构,这被称为文档树,文档树是由节点组成的层级结构,每个节点代表文档中的一个元素或部分,例如,在HTML和XML等标记语言中,文档就是一个树形结构,其中包含元素(如标签、属性等),树的根节点表示整个文档,而其他节点表示文档中的各个部分或元素。这些节点之间存在父子关系和兄弟关系,形成了文档的层级结构)时这很方便,但对于很多程序来说这不是必要的。encoding/xml还为解析XML提供了一个基于标记的更底层的API。在这些API中,解析器读入输入文本,然后输出一个标记流。标记流中主要包含四种类型:StartElement、EndElement、CharData、Comment,这四种类型都是encoding/xml包中的一个具体类型。每次调用(*xml.Decoder).Token都会返回一个标记。
API相关的部分如下所示。
// encoding/xml
package xml
type Name struct {
Local string // 例如"Title"或者"id"
}
type Attr struct { // 例如name="value"
Name Name
Value string
}
// Token包括StratElement、EndElement、CharData和Comment
// 以及其他一些晦涩的类型(未显示)
type Token interface{}
type StartElement struct { // e.g., <name>
Name Name
Attr []Attr
}
type EndElement struct{ Name Name } // e.g., </name>
type CharData []byte // e.g., <p>CharData</p>
// p标签被看做是一个段落用于将文本内容分段
type Comment []byte // e.g., <!-- Comment -->
type Decoder struct { /* ... */
}
func NewDecoder(io.Reader) *Decoder
func (*Decoder) Token() (Token, error) // returns next Token in sequence
Token接口没有任何方法,这也是一个可识别联合的典型示例。一个传统的接口(比如io.Reader)的目标是隐藏具体类型的细节,这样可以轻松创建满足接口的新实现,对于每一种实现,使用方的处理方式都是一样的。可识别联合类型的接口恰好相反,它的实现类型是固定的而不是随意增加的,实现类型是暴露的而不是隐藏的。可识别联合类型很少有方法,操作它的函数经常会使用类型switch,然后对每种类型应用不同的逻辑。
下面的xmlselect程序提取并输出XML文档树中特定元素下的文本。利用以上API,可以在一遍扫描中完成这个任务,还不用生成相应的文档树。
// Xmlselect输出XML文档中指定元素下的文本
package main
import (
"encoding/xml"
"fmt"
"io"
"os"
"strings"
)
func main() {
dec := xml.NewDecoder(os.Stdin)
var stack []string // 元素名的栈
for {
tok, err := dec.Token()
if err == io.EOF {
break
} else if err != nil {
fmt.Fprintf(os.Stderr, "xmlselect: %v\n", err)
os.Exit(1)
}
switch tok := tok.(type) {
case xml.StartElement:
stack = append(stack, tok.Name.Local) // 入栈
case xml.EndElement:
stack = stack[:len(stack)-1] // 出栈
case xml.CharData:
if containsAll(stack, os.Args[1:]) {
fmt.Printf("%s: %s\n", strings.Join(stack, " "), tok)
}
}
}
}
// containsAll判断x是否包含y中的所有元素,且顺序一致
func containsAll(x, y []string) bool {
for len(y) <= len(x) {
if len(y) == 0 {
return true
}
if x[0] == y[0] {
y = y[1:]
}
x = x[1:]
}
return false
}
在main函数的每次循环中,如果遇到StartElement,就把元素的名字入栈,遇到EndElement则把元素名字出栈。API保证了StartElement和EndElement标记是正确匹配的,对于不规范的文档也是如此。Comments被忽略了。当xmlselect遇到CharData时,如果栈中的元素名按顺序包含命令行参数中给定的名称,就输出对应的文本。
如下命令输出了在两层div元素下h2元素的内容。输入的内容是XML规范,这份规范本身也是一个XML文档:

7.15 一些建议
当设计一个新包时,一个新手Go程序员会首先设计一系列接口,然后再定义满足这些接口的具体类型。这种方式会产生很多接口,但这些接口只有一个单独的实现。不要这样做。这种接口是不必要的抽象,还有运行时的成本。可以用导出机制(参考6.6节)来限制一个类型的哪些方法或接口提的哪些字段对包外是可见的。仅在有两个或者多个具体类型需要按统一的方式处理时才需要接口。
这个规则也有特例,如果接口和类型实现出于依赖的原因不能放在一个包里,那么一个接口只有一个具体类型实现也是可以的。在这种情况下,接口是一种解耦两个包的好方式。
因为接口用于有两个或多个类型满足它的情况,它必然会抽象掉那些具体的实现细节。这种设计的结果就是出现了具有更简单和更少方法的接口,比如io.Writer和fmt.Stringer都只有一个方法。设计新类型时越小的接口越容易满足。一个不错的接口设计经验是仅要求你需要的。
Go能很好地支持面向对象编程风格,但这不意味着你只能使用它。不是所有东西都必须是一个对象,全局函数和未封装的数据类型也应该有位置。综合来看,在本书第1章~第5章的示例中,我们用到的方法(比如input.Scan)不超过两打,这与诸如fmt.Printf之类的普通函数比起来并不多。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









