







在前一章中,我们介绍了几个使用goroutines和channels以一种直接和自然的方式实现并发的程序。然而,在这样做的过程中,我们避开了许多重要而微妙的问题。
在本章中,我们将更详细地了解并发的机制。特别地,我们将指出在多个goroutine之间共享变量时出现的一些问题,识别这些问题的分析技术,以及解决这些问题的模式。最后,我们将解释goroutines和操作系统线程之间的一些技术差异。
9.1 竞态
在串行程序中(即一个程序只有一个goroutine),程序中各个步骤的执行顺序由程序逻辑来决定。比如,在一系列语句中,第一句在第二句之前执行,以此类推。当一个程序有两个或多个goroutine时,每个goroutine内部的各个步骤也是顺序执行的,但我们无法知道一个goroutine中的事件x和另外一个goroutine中的事件y的先后顺序。如果我们无法自信地说一个事件肯定先于另外一个事件,那么这两个事件就是并发的。
考虑一个能在串行程序中正确工作的函数。如果这个函数在并发调用时仍然能正确工作,那么这个函数是并发安全(concurrency-safe)的,在这里并发调用是指,在没有额外同步机制的情况下,从两个或者多个goroutine同时调用这个函数。我们可以将这个概念推广到一组协作函数,例如特定类型的方法和操作。如果一个类型的所有可访问方法和操作都是并发安全的,那么该类型就是并发安全的。
我们可以使一个程序具有并发安全性,而不必使该程序中的每个具体类型都具有并发安全性。事实上,并发安全类型是例外而不是规则,因此只有当类型的文档说明说它是并发安全的时候,你才能并发访问它。我们通过将大多数变量限制在单个goroutine中或通过维护更高级别的互斥不变量来避免对大多数变量的并发访问。我们将在本章中解释这些术语。
公开的包级别函数通常被期望是并发安全的。由于包级别变量无法限制在单个goroutine中,修改这些变量的函数必须采用互斥机制。
函数可能在并发调用时出现许多原因导致无法工作,包括死锁、活锁(一种无限循环的状态,它们一直在忙于相互响应,而无法取得任何进展)和资源饥饿。我们没有足够的空间来讨论所有这些问题,因此我们将专注于最重要的一个问题,即竞态条件。
竞态条件是指程序在多个goroutine的操作交错执行时,可能导致程序无法给出正确的结果的情况。竞态条件非常具有破坏性,因为它们可能在程序中潜伏,并且只在特定情况下偶尔出现,例如在负载较重时或使用某些编译器、平台或架构时。这使得它们难以重现和诊断。
按照惯例,我们通过金融比喻来解释竞态条件的严重性,因此我们考虑一个简单的银行账户程序。
// Package bank implements a bank with only one account.
package bank
var balance int
func Deposit(amount int) { balance = balance + amount }
func Balance() int { return balance }
我们本可以将Deposit函数的主体写成balance += amount,这是等价的,但是较长的形式会简化解释。
对于这么简单的程序,我们可以一眼看出对Deposit和Balance的任何调用序列都会给出正确的答案,也就是说,Balance会报告之前存款金额的总和。然而,如果我们不是按顺序而是并发地调用这些函数,Balance就不再保证给出正确的答案。考虑以下两个goroutine,它们代表了对一个联合银行账户(多个账户持有人共同拥有的银行账户)的两个交易:
// Alice:
go func() {
bank.Deposit(200) // A1
fmt.Println("=", bank.Balance()) // A2
}()
// Bob:
go bank.Deposit(100) // B
Alice先存入$200,然后检查她的余额,而Bob存入$100。由于步骤A1和A2与B同时发生,我们无法预测它们发生的顺序。直觉上,可能会认为只有三种可能的顺序,我们将其称为“先Alice”,“先Bob”和“先Alice/Bob/Alice”。以下表格显示了每个步骤后余额变量的值。引号中的字符串代表打印的余额单。

在所有情况下,最终余额都是$300。唯一的变化是Alice的余额单是否包括Bob的交易,但顾客们无论如何都感到满意。
但这种直觉是错误的。还有第四种可能的结果,在这种情况下,Bob的存款发生在Alice的存款中间,即在余额已经读取(balance + amount)但尚未更新(balance = …)时,这会导致Bob的交易消失。这是因为Alice的存款操作A1实际上是两个操作的序列,一个是读取操作,一个是写入操作;我们称它们为A1r和A1w。下面是问题的交错情况:
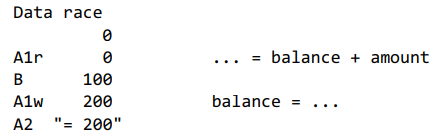
在A1r之后,表达式balance + amount的计算结果为200,这是在A1w写入的值,尽管有中间Bob的存款。最终的余额只有200美元。
这个程序包含一种特定类型的竞争条件,称为数据竞争。当两个goroutine并发地访问同一个变量,并且至少有一个访问是写操作时,就会发生数据竞争。
如果数据竞争涉及到比单个机器字更大的类型,例如接口、字符串或切片,情况会变得更加混乱。以下代码并发地更新了一个变量x,使其成为两个长度不同的切片:
var x []int
go func() { x = make([]int, 10) }()
go func() { x = make([]int, 1000000) }()
x[999999] = 1 // NOTE: undefined behavior; memory corruption possible!
在最后一条语句中,变量x的值是未定义的;它可能是nil,也可能是长度为10或1,000,000的切片。但请注意,切片有三个部分:指针、长度和容量。如果指针来自于第一次调用make,长度来自于第二次调用,那么x将成为一个奇异体,一个其名义长度为1,000,000但其底层数组仅有10个元素的切片。在这种情况下,存储到索引999,999将会覆盖一个远处的内存位置,其后果无法预测,且难以调试和定位。这种语义上的雷区称为未定义行为,在C程序员中很常见;幸运的是,在Go中很少会像在C中那样麻烦。
即使是将并发程序视为多个顺序程序的交错这一概念也是错误的直觉。正如我们将在第9.4节中看到的,数据竞争可能会产生更奇怪的结果。许多程序员——甚至一些非常聪明的程序员——偶尔会为他们程序中已知的数据竞争提供理由:“互斥的成本太高了”,“这个逻辑仅用于日志记录”,“如果丢失一些消息我不介意”等等。在某个编译器和平台上没有出现奇怪的结果可能会让他们产生错误的自信。一个好的经验法则是,没有所谓的良性数据竞争。那么,我们如何避免在我们的程序中出现数据竞争呢?
我们将重复这个定义,因为它非常重要:只要两个goroutine同时访问同一个变量,并且其中至少有一个访问是写入操作,就会发生数据竞争。从这个定义可以得出,有三种方式可以避免数据竞争。
第一种方式是不写入该变量。考虑下面的map,它在每次首次请求键时才延迟填充。如果Icon被顺序调用,程序可以正常工作,但如果Icon被并发调用,访问map就会出现数据竞争。
var icons = make(map[string]image.Image)
func loadIcon(name string) image.Image
// NOTE: not concurrency-safe!
func Icon(name string) image.Image {
icon, ok := icons[name]
if !ok {
icon = loadIcon(name)
icons[name] = icon
}
return icon
}
如果我们在创建额外的goroutine之前使用所有条目初始化map,并且之后不再修改它,那么任意数量的goroutine可以安全地并发调用Icon,因为每个goroutine只读取map。
var icons = map[string]image.Image{
"spades.png": loadIcon("spades.png"),
"hearts.png": loadIcon("hearts.png"),
"diamonds.png": loadIcon("diamonds.png"),
"clubs.png": loadIcon("clubs.png"),
}
// Concurrency-safe.
func Icon(name string) image.Image {
return icons[name]
}
在上面的例子中,icons变量在包初始化期间被赋值,这发生在程序的main函数开始运行之前。一旦初始化,icons就不再修改。从不被修改或是不可变的数据结构本质上是并发安全的,因此不需要同步。但是很明显,如果更新是必要的,就不能使用这种方法,就像银行账户一样。
避免数据竞争的第二种方法是避免从多个goroutine访问变量。这是前面章节中许多程序所采用的方法。例如,并发网络爬虫(8.6节)中的主goroutine是唯一访问seen映射的goroutine,而聊天服务器(8.10节)中的broadcaster goroutine是唯一访问clients map的goroutine。这些变量被限制在单个goroutine中。由于其他goroutine无法直接访问变量,它们必须使用通道向控制变量的goroutine发送请求来查询或更新变量。这就是Go准则“不要通过共享内存来通信;相反,通过通信来共享内存”的含义。一个通过通道请求来控制受限变量的goroutine被称为该变量的监控goroutine。例如,broadcaster goroutine监控对clients map的访问。
下面是重写的银行案例,用一个叫teller的监控goroutine限制balance变量:
package bank
var deposits = make(chan int) // 发送存款额
var balances = make(chan int) // 接收余额
func Deposit(amount int) { deposits <- amount }
func Balance() int { return <-balances }
func teller() {
var balance int // balance被限制在teller goroutine中
for {
select {
case amount := <-deposits:
balance += amount
case balances <- balance:
}
}
}
func init() {
go teller() // 启动监控goroutine
}
即使变量无法在其整个生命周期内被限制在单个goroutine中,但限制仍然可能是解决并发访问问题的一种方法。例如,通过在管道中传递其地址,可以在多个goroutine之间共享变量。如果管道的每个阶段在将变量发送到下一个阶段后都不访问该变量,则对该变量的所有访问都是顺序的。实际上,变量被限制在管道的一个阶段,然后限制在下一个阶段,依此类推。这种约束有时被称为序列化约束。
在下面的示例中,蛋糕被串行地限制在首先是baker goroutine,然后是icer goroutine:
type Cake struct{ state string }
func baker(cooked chan<- *Cake) {
for {
cake := new(Cake)
cake.state = "cooked"
cooked <- cake // baker never touches this cake again
}
}
func icer(iced chan<- *Cake, cooked <-chan *Cake) {
for cake := range cooked {
cake.state = "iced"
iced <- cake // icer never touches this cake again
}
}
避免数据竞态的第三种方法是允许许多goroutine同时访问变量,但一次只允许一个。这种方法被称为互斥,并且是接下来章节的主题。
9.2 互斥锁:sync.Mutex
在第8.6节中,我们使用了一个带缓冲的通道作为计数信号量,以确保不超过20个goroutine同时发出HTTP请求。基于相同的思想,我们可以使用容量为1的通道来确保最多只有一个goroutine同时访问共享变量。一个只计数到1的信号量被称为二进制信号量。
var (
sema = make(chan struct{}, 1) // a binary semaphore guarding balance
balance int
)
func Deposit(amount int) {
sema <- struct{}{} // acquire token
balance = balance + amount
<-sema // release token
}
func Balance() int {
sema <- struct{}{} // acquire token
b := balance
<-sema // release token
return b
}
这种互斥的模式非常有用,因此sync包中直接支持Mutex类型。它的Lock方法获取令牌(称为锁),而Unlock方法释放它。
import "sync"
var (
mu sync.Mutex // guards balance
balance int
)
func Deposit(amount int) {
mu.Lock()
balance = balance + amount
mu.Unlock()
}
func Balance() int {
mu.Lock()
b := balance
mu.Unlock()
return b
}
每当一个goroutine访问银行的变量(这里只有balance),它必须调用mutex的Lock方法来获取一个独占锁。如果其他goroutine已经获取了锁,这个操作将会阻塞,直到另一个goroutine调用Unlock,锁才再次可用。mutex保护了共享变量。按照惯例,由mutex保护的变量在mutex自身声明的后面立即声明。如果偏离了这个规范,请确保进行文档说明。
在Lock和Unlock之间的代码区域,goroutine可以自由地读取和修改共享变量,这一区域被称为临界区。锁持有者调用Unlock发生在其他goroutine可以获取锁之前。一旦goroutine完成了操作,就要在函数的所有路径上,包括错误路径上释放锁。
上面的银行程序举例说明了一个常见的并发模式。一组导出函数封装了一个或多个变量,这样访问这些变量的唯一方法是通过这些函数(或对象的方法)。每个函数在开始时获取一个mutex锁,在结束时释放它,从而确保共享变量不会被并发访问。这种函数、mutex锁和变量的安排称为监视器(monitor)。(之前在监控goroutine中也使用监控(monitor)这个词,都代表使用一个代理人(broker)来确保变量按顺序访问)
由于Deposit和Balance函数中的临界区非常短——只有一行代码,没有分支——在结尾调用Unlock是直截了当的。在更复杂的临界区中,尤其是那些必须通过提前返回来处理错误的情况下,很难确保在所有路径上Lock和Unlock的调用严格匹配。Go的defer语句来拯救我们:通过延迟调用Unlock,临界区隐含地延伸到当前函数的结尾,使我们不必记住在Lock调用远离之处插入Unlock调用。
func Balance() int {
mu.Lock()
defer mu.Unlock()
return balance
}
在上面的例子中,Unlock在返回语句读取balance的值之后执行,因此Balance函数是并发安全的。作为额外的好处,我们不再需要局部变量b。
此外,延迟的Unlock也会在临界区发生panic时运行,这在使用recover(5.10节)的程序中可能很重要。相对于显式调用Unlock,延迟会稍微增加一些开销,但代码会更清晰。像对待其他并发程序一样,更倾向于清晰明了,抵制过早的优化。在可能的情况下,使用defer并让临界区延伸至函数的结尾。
考虑下面的Withdraw函数。如果成功,它将按指定金额减少余额并返回true。但如果账户余额不足以进行交易,Withdraw将恢复余额并返回 false。
// NOTE: not atomic!
func Withdraw(amount int) bool {
Deposit(-amount)
if Balance() < 0 {
Deposit(amount)
return false // insufficient funds
}
return true
}
该函数最终会给出正确的结果,但它有一个令人讨厌的副作用。当尝试进行过度的取款时,余额暂时会降到零以下。这可能导致一个对较小金额的并发取款被错误地拒绝。因此,如果Bob尝试购买一辆跑车,Alice就无法支付她的早晨咖啡。问题在于Withdraw不是原子操作:它由三个单独的操作序列组成,每个操作都会获取然后释放互斥锁,但没有任何东西锁定整个序列。
理想情况下,Withdraw应该在整个操作周围获取互斥锁一次。然而,它不能正常工作:
// NOTE: incorrect!
func Withdraw(amount int) bool {
mu.Lock()
defer mu.Unlock()
Deposit(-amount)
if Balance() < 0 {
Deposit(amount)
return false // insufficient funds
}
return true
}
Withdraw函数中的Deposit函数会尝试第二次调用mu.Lock() 来获取互斥锁,但因为互斥锁不可重入——不可能锁定已经被锁定的互斥锁——这导致了死锁,Withdraw永远阻塞。
Go互斥锁不可重入有一个很好的原因。互斥锁的目的是确保在程序临界区维护共享变量的某些不变量。其中一个不变量是‘‘没有goroutine在访问共享变量’’,但可能还有特定于互斥锁所保护的数据结构的其他不变量。当一个goroutine获取互斥锁时,它可能假设不变量成立。在持有锁的同时,它可能更新共享变量,以使不变量暂时被违反。然而,当释放锁时,它必须确保已恢复顺序,并且不变量再次成立。虽然可重入互斥锁可以确保没有其他goroutine访问共享变量,但它不能保护这些变量的其他不变量。
一个常见的解决方案是将诸如Deposit这样的函数分成两个部分:一个未导出的函数deposit,它假设锁已经被持有并进行真正的工作,以及一个导出的函数Deposit,它在调用deposit之前获取锁。然后我们可以这样用deposit来表达Withdraw:
// This function requires that the lock be held.
func deposit(amount int) { balance += amount }
func Deposit(amount int) {
mu.Lock()
defer mu.Unlock()
deposit(amount)
}
func Balance() int {
mu.Lock()
defer mu.Unlock()
return balance
}
// NOTE: incorrect!
func Withdraw(amount int) bool {
mu.Lock()
defer mu.Unlock()
deposit(-amount)
if balance < 0 {
deposit(amount)
return false // insufficient funds
}
return true
}
当然,这里所示的deposit函数非常简单,一个真实的Withdraw函数可能不会费心将其放到一个函数中,然后再调用它,但尽管如此,它仍然说明了这个原则。
封装(6.6节)通过减少程序中的意外交互,帮助我们维护数据结构不变量。出于同样的原因,封装也有助于我们维护并发不变量。当使用互斥锁时,要确保它及其所保护的变量都不是导出的,无论它们是包级别的变量还是结构体的字段。
9.3 读写互斥锁:sync.RWMutex
在看到他的100美元存款消失得无影无踪后,Bob焦虑地编写了一个程序,以每秒数百次的频率检查他的银行余额。他在家里、在工作地以及手机上都运行这个程序。银行注意到增加的流量正在导致存款和取款的延迟,因为所有请求都是顺序运行的,独占锁会暂时阻止其他goroutine运行。
由于余额函数只需要读取变量的状态,事实上,让多个查询余额的调用并发运行是安全的,只要没有正在运行的存款或取款调用。在这种情况下,我们需要一种特殊类型的锁,允许只读操作并行进行,但写操作具有完全独占的访问权限。这种锁称为多读单写锁,在Go中由sync.RWMutex提供:
var mu sync.RWMutex
var balance int
func Balance() int {
mu.RLock() // readers lock
defer mu.RUnlock()
return balance
}
现在,余额查询函数调用RLock和RUnlock方法来获取和释放读锁(共享锁)。未被更改的存款函数调用mu.Lock和mu.Unlock方法来获取和释放写锁(独占锁)。
在进行更改后,Bob的大部分余额查询请求可以并行运行,并且更快地完成。锁的可用时间更长,存款请求可以及时进行。
只有在临界区没有对共享变量的写操作时才能使用RLock。一般来说,我们不应假设看似只读的函数或方法不会更新某些变量。例如,一个看似简单的访问器方法可能也会增加内部的使用计数器,或者更新缓存以便重复调用更快。如果不确定,应使用独占锁。
仅当大多数获取锁的goroutine是读者,并且锁争用状态多时(即goroutine经常必须等待获取锁时),才有必要使用RWMutex。RWMutex需要更复杂的内部记录,使得在无竞争锁时比常规的互斥锁更慢。
9.4 内存同步
你可能想知道为什么余额查询方法需要互斥锁,无论是基于通道还是基于互斥锁。毕竟,与存款不同,它只包含单个操作,因此没有其他goroutine在其中“中途”执行的危险。我们需要互斥锁的两个原因:首先,余额不能在某些其他操作(如取款)中间执行。第二个(更微妙的)原因是同步不仅仅涉及多个goroutine的执行顺序;同步还影响内存。
在现代计算机中,可能有数十个处理器,每个处理器都有自己的对于内存的本地缓存。为了效率,对内存的写入会在每个处理器内部进行缓冲,仅会在必要时刷新到内存。They may even be committed to main memory in a different order than they were written by the writing goroutine。通道通信和互斥操作等同步原语会导致处理器刷新并提交其累积的写入,以便保证到达该点的goroutine的执行效果对其他处理器上运行的goroutine是可见的。
考虑以下代码片段的可能输出:
var x, y int
go func() {
x = 1 // A1
fmt.Println("y:", y, " ") // A2
}()
go func() {
y = 1 // B1
fmt.Println("x:", x, " ") // B2
}()
由于这两个goroutine是并发的,并且在没有互斥的情况下访问共享变量,所以存在数据竞争,因此我们不应该感到惊讶程序不是确定性的。我们可能期望它打印以下四种结果之一,这些结果对应于程序语句的直观交错:
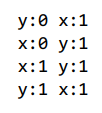
第四行可能是由序列A1、B1、A2、B2或者B1、A1、A2、B2等来解释。然而,这两个结果可能会让人感到意外。

但是,取决于编译器、CPU和许多其他因素,它们也可能发生。什么可能的四个语句的交错可以解释它们呢?
在单个goroutine内,每个语句的效果都保证按照执行顺序发生;goroutine内是顺序一致的。但是,在没有使用通道或互斥量进行显式同步的情况下,不能保证所有goroutines都以相同的顺序看到事件。尽管goroutine A在读取y的值之前能观察到写入x=1的效果,但它不一定会观察到goroutine B写入y的操作,因此A可能会打印出y的旧值。
尝试将并发理解为各goroutine语句的某种交错可能很诱人,但正如上面的示例所示,这并不是现代编译器或CPU的工作方式。由于赋值和打印涉及不同的变量,编译器可能会得出这两个语句的顺序不会影响结果的结论,并进行交换。如果两个goroutine在不同的CPU上执行,每个CPU都有自己的缓存,那么一个goroutine的写入对另一个goroutine的打印不可见,直到处理器缓存与主存同步。
所有这些并发问题都可以通过使用简单、已成熟的模式来避免:如果可能,将变量限制在单个goroutine中;对于所有其他变量,使用互斥量同步。
9.5 延迟初始化:sync.Once
推迟昂贵的初始化步骤直到需要的时候是一个好的实践。在程序的开头初始化一个变量会增加启动延迟,并且如果执行并不总是达到使用该变量的程序部分,则初始化它是不必要的。让我们回到之前在章节中看到的icons变量:
func loadIcons() {
icons = map[string]image.Image{
"spades.png": loadIcons("spades.png"),
"hearts.png": loadIcons("hearts.png"),
"diamonds.png": loadIcons("diamonds.png"),
"clubs.png": loadIcons("clubs.png"),
}
}
// NOTE: not concurrency-safe!
func Icon(name string) image.Image {
if icons == nil {
loadIcons() // one-time initialization
}
return icons[name]
}
对于只被单个goroutine访问的变量,我们可以使用上述模式,但如果Icon被同时调用,则此模式不安全。就像银行的原始Deposit函数一样,Icon由多个步骤组成:它测试icons是否为nil,然后加载图标,然后将icons更新为非nil值。直觉可能会认为上述竞争条件的最坏可能结果是loadIcons函数被多次调用。当第一个goroutine正在加载图标时,另一个进入Icon的goroutine会发现变量仍然等于nil,并且还会调用loadIcons。
但是,这种直觉也是错误的。(我们希望到现在你已经对并发有了新的直觉,即并发的直觉是不可信的!)回想一下第9.4节对内存的讨论。在没有显式同步的情况下,编译器和CPU可以以任意数量的方式重新排序对内存的访问,只要重排的结果在goroutine内看来是顺序一致的。loadIcons语句的一种可能的重新排序如下所示。它在将其填充之前将空映射存储在icons变量中。
func loadIcons() {
icons = make(map[string]image.Image)
icons["spades.png"] = loadIcons("spades.png")
icons["hearts.png"] = loadIcons("hearts.png")
icons["diamonds.png"] = loadIcons("diamonds.png")
icons["clubs.png"] = loadIcons("clubs.png")
}
因此,发现icons不是空值的goroutine不能假设变量的初始化已经完成。
确保所有goroutines观察到loadIcons的效果的最简单正确的方法是使用互斥量对它们进行同步:
var mu sync.Mutex // 保护icons
var icons map[string]image.Image
// Concurrency-safe.
func Icon(name string) image.Image {
mu.Lock()
defer mu.Unlock()
if icons == nil {
loadIcons()
}
return icons[name]
}
然而,强制对icons的互斥访问的成本是,即使变量已经安全初始化并且永远不会再次修改,两个goroutine也无法同时访问该变量。这提示了一种多读者锁:
var mu sync.RWMutex // guard icons
var icons map[string]image.Image
// Concurrency-safe.
func Icon(name string) image.Image {
mu.RLock()
if icons != nil {
icon := icons[name]
mu.RUnlock()
return icon
}
mu.RUnlock()
// acquire an exclusive lock
mu.Lock()
if icons == nil { // NOTE: must recheck for nil
loadIcons()
}
icon := icons[name]
mu.Unlock()
return icon
}
现在有两个临界区。首先,goroutine获取一个读取者锁,查询map,然后释放锁。如果找到了条目(常见情况),则返回。如果没有找到条目,则goroutine获取一个写者锁。没有办法将共享锁升级为独占锁而不先释放共享锁,因此我们必须在另一个goroutine在此期间可能已经初始化了icons变量的情况下重新检查icons变量。
上述模式给了我们更大的并发性,但是复杂,因此容易出错。幸运的是,sync包提供了解决一次性初始化问题的专门解决方案:sync.Once。概念上,Once由一个互斥锁和一个布尔变量组成,记录初始化是否已经完成;互斥锁保护布尔值和客户端的数据结构。sync.Once唯一的方法是Do,它接受初始化函数作为其参数。让我们使用Once来简化Icon函数。
var loadIconsOnce sync.Once
var icons map[string]image.Image
// Concurrency-safe.
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons)
return icons[name]
}
每次调用Do(loadIcons)都会锁定互斥量并检查布尔变量。在第一次调用中,变量为false,Do调用loadIcons并将变量设置为true。后续的调用什么也不做,互斥量同步确保loadIcons对内存(特别是icons)的影响对所有goroutines都可见。以这种方式使用sync.Once,我们可以避免在变量被正确创建前与其他goroutines共享变量。
9.6 竞态检测器
即使尽最大的注意,编写并发程序时仍然很容易出错。幸运的是,Go运行时和工具链都配备了一个复杂且易于使用的动态分析工具,即race detector(竞态检测器)。
只需在go build、go run或go test命令中添加-race标志。这会导致编译器构建应用程序或测试的修改版本,并添加额外的内容,这些内容有效地记录了在执行期间发生的所有对共享变量的访问,以及读取或写入变量的goroutine的身份。此外,修改后的程序记录了所有同步事件,如go语句、通道操作和调用(*sync.Mutex).Lock、(*sync.WaitGroup).Wait等等(同步事件的完整集合由Go内存模型文档规定,该文档随着语言规范一起发布)。
竞态检测器研究这些事件流,寻找一个goroutine读取或写入了一个共享变量,而该变量是最近由另一个不同的goroutine写入的,且没有中间的同步操作。这表明了对共享变量的并发访问,因此这是数据竞争。该工具打印一个报告,其中包括变量的身份,以及读取goroutine和写入goroutine中的活动函数调用的堆栈。这通常足以准确定位问题。第9.7节包含了竞态检测器的一个示例。
竞态检测器报告了实际执行的所有数据竞争。然而,它只能检测到在运行时发生的竞态条件;它不能找到运行时没有出现过的竞态条件。为了获得最佳结果,请确保测试时使用并发来测试。
由于额外的记录,使用竞态检测构建的程序需要更多的时间和内存来运行,但即使对于许多生产作业来说,这种开销也是可以容忍的。对于不经常发生的竞态条件,让竞态检测器执行其工作可以节省数小时或数天的调试时间。
9.7 例子:并发非阻塞缓存
在本节中,我们将构建一个并发的非阻塞缓存,这是一个抽象概念,它解决了现实世界中经常出现但现有库没有很好解决的问题。这个问题是函数记忆化,即缓存函数的结果,以便它只需要计算一次。我们的解决方案将是并发安全的,并且将避免基于单个锁的设计所带来的争用。
我们将使用下面的httpGetBody函数作为我们可能想要记忆化的函数的示例。它会发起一个HTTP GET请求并读取请求体。对这个函数的调用相对昂贵,因此我们希望避免不必要地重复调用它们。
func httpGetBody(url string) (interface{}, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
defer resp.Body.Close()
return ioutil.ReadAll(resp.Body)
}
最后一行隐藏了一个小细节。ReadAll返回两个结果,一个[]byte和一个error,但由于它们可以分别赋值给httpGetBody声明的结果类型interface{}和error,因此我们可以直接返回调用的结果。我们选择了这种httpGetBody的返回类型,以使其符合我们的缓存设计的函数类型。
这是缓存的第一个草稿:
// Package memo provides a concurrency-unsafe
// memoization of a function of type Func.
package memo
// A Memo caches the results of calling a Func.
type Memo struct {
f Func
cache map[string]result
}
// Func is the type of the function to memoize.
type Func func(key string) (interface{}, error)
type result struct {
value interface{}
err error
}
func New(f Func) *Memo {
return &Memo{f: f, cache: make(map[string]result)}
}
// NOTE: not concurrency-safe!
func (memo *Memo) Get(key string) (interface{}, error) {
res, ok := memo.cache[key]
if !ok {
res.value, res.err = memo.f(key)
memo.cache[key] = res
}
return res.value, res.err
}
一个Memo实例包含要进行记忆的函数f(类型为Func)和缓存,缓存是一个从字符串到结果的映射。每个结果简单地是调用f时返回的结果对——一个值和一个错误。随着设计的进展,我们将展示Memo的几种变体,但它们都将共享这些基本方面。
下面是如何使用Memo的示例。对于传入URL流中的每个元素,我们调用Get函数,记录调用的延迟和返回的数据量。
m := memo.New(httpGetBody)
for url := range incomingURLs() {
start := time.Now()
value, err := m.Get(url)
if err != nil {
log.Print(err)
}
// value.([]byte)是类型断言,返回[]byte类型的变量
fmt.Printf("%s, %s, %d bytes\n", url, time.Since(start), len(value.([]byte)))
}
我们可以使用test包(第11章的主题)系统地调查记忆化的效果。从下面的测试输出中,我们可以看到URL流中包含重复的URL,并且尽管对于每个URL的第一次调用(*Memo).Get可能需要数百毫秒,但第二次请求在不到一毫秒的时间内返回相同数量的数据。
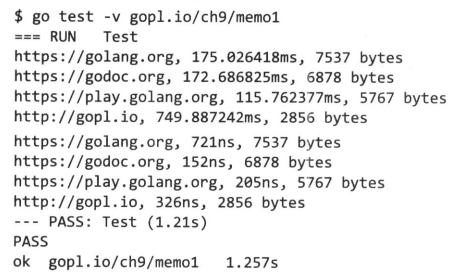
这次测试中所有的Get都是串行运行的。
因为HTTP请求用并发来改善的空间很大,所以我们修改测试让所有请求并发进行。这个测试使用sync.WaitGroup来做到等最后一个请求完成后再返回的效果。
m := memo.New(httpGetBody)
var n sync.WaitGroup
for url := range incomingURLs() {
n.Add(1)
go func(url string) {
start := time.Now()
value, err := m.Get(url)
if err != nil {
log.Print(err)
}
fmt.Printf("%s, %s, %d bytes\n",
url, time.Since(start), len(value.([]byte)))
n.Done()
}(url)
}
n.Wait()
测试运行速度快了很多,但不幸的是,它不太可能始终正确地工作。我们可能会发现意外的缓存未命中,或者缓存命中返回不正确的值,甚至崩溃。
更糟糕的是,它很可能有时能够正确工作,所以我们甚至可能都不会注意到它存在问题。但如果我们使用-race标志运行它,竞争检测器(9.6节)经常会打印出类似这样的报告。
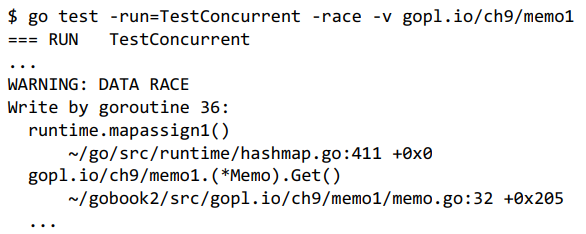
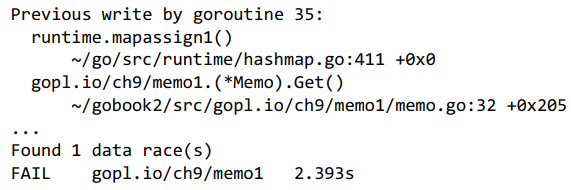
上图告诉我们在memo.go的第32行,两个goroutine在没有任何干预同步的情况下更新了缓存映射。Get不是并发安全的:它存在数据竞争。
func (memo *Memo) Get(key string) (interface{}, error) {
res, ok := memo.cache[key]
if !ok {
res.value, res.err = memo.f(key)
memo.cache[key] = res // 第32行
}
return res.value, res.err
}
使缓存并发安全的最简单方法是使用基于监视器的同步机制。我们所需要做的就是向Memo添加一个互斥锁,在Get开始时获取互斥锁,并在Get返回之前释放它,以便两个缓存操作发生在临界区内。
type Memo struct {
f Func
mu sync.Mutex // guards cache
cache map[string]result
}
// Get is concurrency-safe!
func (memo *Memo) Get(key string) (interface{}, error) {
memo.mu.Lock()
res, ok := memo.cache[key]
if !ok {
res.value, res.err = memo.f(key)
memo.cache[key] = res
}
memo.mu.Unlock()
return res.value, res.err
}
现在竞争检测器保持安静,即使同时运行测试也是如此。不幸的是,这对Memo的更改颠覆了我们之前的性能增益。通过在每次对f的调用期间持有锁,Get序列化了我们打算并行化的所有I/O操作。我们需要的是一个非阻塞缓存,一个不会序列化对其记忆化函数的调用的缓存。
在下面的Get的下一个实现中,goroutine两次获取锁:一次用于查找,如果查找返回空,则第二次用于更新。第一次解锁到第二次加锁期间,其他goroutine可以自由使用缓存。
func (memo *Memo) Get(key string) (value interface{}, err error) {
memo.mu.Lock()
res, ok := memo.cache[key]
memo.mu.Unlock()
if !ok {
res.value, res.err = memo.f(key)
// Between the two critical sections, several goroutines
// may race to compute f(key) and update the map.
memo.mu.Lock()
memo.cache[key] = res
memo.mu.Unlock()
}
return res.value, res.err
}
性能再次提升了,但现在我们注意到有些URL被重复获取了。当两个或更多的goroutine在大约相同的时间调用Get来获取相同的URL时,就会发生这种情况。它们都查阅缓存,发现缓存中没有值,然后调用慢速函数f。然后它们都使用获取到的结果更新映射。其中一个结果被另一个覆盖了。
理想情况下,我们希望避免这种冗余的工作。这种特性有时被称为重复抑制。在下面的Memo版本中,每个map元素都是指向一个entry结构的指针。每个entry包含了对函数f的调用的记忆化结果,就像之前一样,但它还包含了一个名为ready的通道。就在entry的结果被设置之后,该通道将被关闭,以向任何其他的goroutine广播(8.9节),表示它们现在可以安全地从entry中读取结果了。
type entry struct {
res result
ready chan struct{} // closed when res is ready
}
func New(f Func) *Memo {
return &Memo{f: f, cache: make(map[string]*entry)}
}
type Memo struct {
f Func
mu sync.Mutex // guards cache
cache map[string]*entry
}
func (memo *Memo) Get(key string) (value interface{}, err error) {
memo.mu.Lock()
e := memo.cache[key]
if e == nil {
// This is the first request for this key.
// This goroutine becomes responsible for computing
// the value and broadcasting the ready condition.
e = &entry{ready: make(chan struct{})}
memo.cache[key] = e
memo.mu.Unlock()
e.res.value, e.res.err = memo.f(key)
close(e.ready) // broadcast ready condition
} else {
// This is a repeat request for this key.
memo.mu.Unlock()
<-e.ready // wait for ready condition
}
return e.res.value, e.res.err
}
现在调用Get会获取保护缓存map的互斥锁,查找map中现有entry的指针,如果没有找到,则分配并插入一个新entry,然后释放锁。如果存在现有entry,则其值不一定准备好——另一个goroutine仍然可能正在调用慢速函数f——因此goroutine必须在读取entry的结果之前等待entry的"ready"条件。它通过从ready通道中读取一个值来做到这一点,因为此操作会阻塞,直到通道关闭。如果没有现有entry,则通过将一个新的"not ready" entry插入map中,当前goroutine负责调用慢速函数、更新entry,并将新entry的就绪状态广播给任何可能等待它的其他goroutine。
请注意,entry中的变量e.res.value和e.res.err是在多个goroutine之间共享的。创建entry的goroutine设置它们的值,其他goroutine在"ready"条件被广播后读取它们的值。尽管被多个goroutine访问,但不需要互斥锁。ready通道的关闭发生在任何其他goroutine接收到广播事件之前,因此在第一个goroutine中对这些变量的写操作发生在后续goroutine读取它们之前。这里不存在数据竞争。
我们的并发、重复抑制、非阻塞缓存已经完成。
上面的Memo实现使用互斥锁来保护一个被每个调用Get的goroutine共享的映射变量。将这种设计与另一种设计进行对比很有趣,后者将map变量限制在一个监视器goroutine中,Get的调用者必须向监视器goroutine发送消息。
Func、result、entry的声明与前面相同:
// Func is the type of the function to memoize.
type Func func(key string) (interface{}, error)
// A result is the result of calling a Func.
type result struct {
value interface{}
err error
}
type entry struct {
res result
ready chan struct{} // closed when res is ready
}
然而,现在Memo类型包含一个通道,通道在requests类型中,通过该通道Get的调用者与监视器goroutine进行通信。通道的元素类型是request。使用这个结构,Get的调用者向监视器goroutine发送键(即记忆化函数的参数)以及一个通道response,通过这个通道当结果可用时将结果发送回来。这个通道仅会传输一个值。
// A request is a message requesting that the Func be applied to key.
type request struct {
key string
response chan<- result // the client wants a single result
}
type Memo struct{ requests chan request }
// New returns a memoization of f. Clients must subsequently call Close.
func New(f Func) *Memo {
memo := &Memo{requests: make(chan request)}
go memo.server(f)
return memo
}
func (memo *Memo) Get(key string) (interface{}, error) {
response := make(chan result)
memo.requests <- request{key, response}
res := <-response
return res.value, res.err
}
func (memo *Memo) Close() { close(memo.requests) }
在上述Get方法中,创建了一个response通道,将其放入请求中,然后将请求发送到监视器goroutine,然后立即从中接收。缓存变量被限制在监视器goroutine (*Memo).server中。监视器在一个循环中读取请求,直到请求通道被Close方法关闭为止。对于每个请求,它都会查询缓存,如果没有找到,则创建并插入一个新entry。
func (memo *Memo) server(f Func) {
cache := make(map[string]*entry)
for req := range memo.requests {
e := cache[req.key]
if e == nil {
// This is the first request for this key.
e = &entry{ready: make(chan struct{})}
cache[req.key] = e
go e.call(f, req.key) // call f(key)
}
go e.deliver(req.response)
}
}
func (e *entry) call(f Func, key string) {
// Evaluate the function.
e.res.value, e.res.err = f(key)
// Broadcast the ready condition.
close(e.ready)
}
func (e *entry) deliver(response chan<- result) {
// Wait for the ready condition.
<-e.ready
// Send the result to the client.
response <- e.res
}
类似于基于互斥锁的版本,对于给定键的第一个请求负责调用函数f,并将结果存储在条目中,通过关闭ready通道广播条目的就绪状态。这由(*entry).call完成。
对于相同键的后续请求,在映射中找到现有条目,等待结果变为就绪,并通过response通道将结果发送给调用Get的客户端goroutine。这由(*entry).deliver完成。call和deliver方法必须在它们自己的goroutine中调用,以确保监视器goroutine不会停止处理新请求。
这个例子显示了使用两种方法之一(共享变量和锁,或通信顺序进程)可以构建许多并发结构而不会过度复杂。
在特定情况下,哪种方法更可取并不总是明显,但了解并对比它们的是值得的。有时,从一种方法切换到另一种方法可以使的代码更简单。
9.8 goroutine与线程
在前面的章节中,我们说过暂时可以忽略goroutine和操作系统(OS)线程之间的区别。尽管它们之间的区别基本上是量变,但足够多的量变会导致质变,而goroutine和线程也是如此。现在是区分它们的时候了。
9.8.1 可增长的栈
每个操作系统线程都有一个固定大小的内存块(通常为2MB),用作其栈,这是一个工作区,用于保存正在进行或在另一个函数被调用时暂时挂起的函数调用的本地变量。这个固定大小的栈既太大又太小。对于一个小的goroutine来说,比如一个仅等待WaitGroup然后关闭一个通道的goroutine,一个2MB的栈将是一个巨大的内存浪费。在Go程序中一次创建数十万个goroutine并不罕见,而使用这么大的栈将是不可能的。并且固定大小的栈对于最复杂和递归深度最深的函数来说并不总是足够大。改变固定大小可以提高空间效率,并允许创建更多的线程,或者可以支持更深度的递归函数,但不能同时做到两者兼顾。
相比之下,一个goroutine从一个小的栈开始,通常为2KB。一个goroutine的栈,就像一个操作系统线程的栈一样,保存活动和暂停的函数调用的本地变量,但不同于操作系统线程,goroutine的栈是不固定的;它根据需要增长和缩小。goroutine栈的大小限制可能高达1GB,比典型的固定大小线程栈大数个数量级,尽管当然很少有goroutine使用那么多。
9.8.2 goroutine调度
操作系统线程由操作系统内核调度。每隔几毫秒,硬件定时器会中断处理器,导致一个叫调度器的内核函数被调用。这个函数暂停当前正在执行的线程,并将其寄存器保存在内存中,然后检查线程列表并决定下一个应该运行的线程,从内存中恢复该线程的寄存器,然后恢复该线程的执行。因为操作系统线程由内核调度,所以从一个线程传递控制到另一个线程需要进行完整的上下文切换,即保存一个用户线程的状态到内存中,恢复另一个线程的状态,并更新调度器的数据结构。这个操作很慢,因为它的局部性差,并且需要大量的内存访问,并且随着访问内存所需的CPU周期数的增加,历史上这个操作只会变得更糟。
Go运行时包含其自己的调度器,使用一种称为m:n调度的技术,因为它在n个操作系统线程上多路复用(或调度)m个goroutine。Go调度器的工作类似于内核调度器,但它只关注单个Go程序的goroutine。
与操作系统的线程调度器不同,Go调度器不是周期性地由硬件定时器调用的,而是通过某些Go语言构造隐式调用的。例如,当一个goroutine调用time.Sleep或在通道或互斥操作中阻塞时,调度器将其置于休眠状态,并运行另一个goroutine直到该goroutine被唤醒为止。因为它不需要切换到内核上下文,所以重新调度goroutine比重新调度线程要便宜得多。
9.8.3 GOMAXPROCS
Go调度器使用一个名为GOMAXPROCS的参数来确定同时可以活跃执行Go代码的操作系统线程数量。其默认值是机器上的CPU数量,因此在一个拥有8个CPU的机器上,调度器将同时在最多8个操作系统线程上调度Go代码(GOMAXPROCS是m:n调度中的n)。正在睡眠或在通信中阻塞的goroutines根本不需要线程。被阻塞在I/O或其他系统调用中,或调用非Go函数的goroutines,则需要一个操作系统线程,但GOMAXPROCS不需要考虑这些。
你可以使用GOMAXPROCS环境变量或runtime.GOMAXPROCS函数显式地控制此参数。我们可以看到GOMAXPROCS对这个小程序的影响,该程序打印一个无限流的零和一。
for {
go fmt.Print(0)
fmt.Print(1)
}
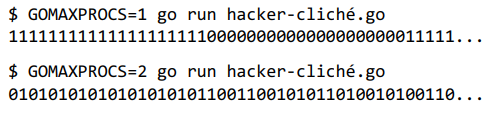
在第一次运行时,最多同时执行一个goroutine。最初是主goroutine,它打印数字1。经过一段时间后,Go调度器将其置于休眠状态,并唤醒打印数字0的goroutine,在操作系统线程上运行。在第二次运行中,有两个可用的操作系统线程,因此两个goroutine同时运行,以大约相同的速率打印数字。我们必须强调,goroutine调度涉及许多因素,并且运行时不断演变,因此你的结果可能与上述结果有所不同。
9.8.4 goroutine没有标识
在大多数支持多线程的操作系统和编程语言中,当前线程具有一个明确的标识,可以轻松地作为普通值获取,通常是一个整数或指针。这使得很容易构建一个称为线程局部存储(thread-local storage)的抽象,它基本上是一个全局map,以线程标识为键,这样每个线程都可以独立地存储和检索值,与其他线程无关。
goroutines对于程序员来说没有可以访问的身份概念。这是有意设计的,因为线程局部存储往往会被滥用。例如,在使用线程局部存储的语言中实现的Web服务器中,许多函数通常会通过查找该存储中的信息来找到它们当前正在处理的HTTP请求的信息。然而,就像过度依赖全局变量的程序一样,这可能会导致不健康的“远距离影响”,其中函数的行为不仅由其参数确定,而且由其运行的线程的标识确定。因此,如果线程的标识发生变化——比如说一些工作线程被招募来帮助——函数会神秘地出现错误行为。
Go鼓励一种更简单的编程风格,其中影响函数行为的参数是明确的。这不仅使程序更易读,而且让我们可以自由地将给定函数的子任务分配给许多不同的goroutine,而不必担心它们的标识。
现在你已经学会了编写Go程序所需的所有语言特性。在接下来的两章中,我们将回顾一些支持大规模编程的实践和工具:如何将项目结构化为一组包,以及如何获取、构建、测试、基准测试、性能分析、文档化和分享这些包。














 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









