






 在使用mmsegmentation训练自定义数据集时遇到UnicodeDecodeError,原因是文件读取未指定编码。通过指定utf-8编码解决了该错误,但其他地方的代码仍报同样错误。进一步调查发现Windows系统的默认编码并非utf-8。通过修改系统编码设置,问题得到彻底解决。此问题困扰博主多日,深入理解问题本质是关键。
在使用mmsegmentation训练自定义数据集时遇到UnicodeDecodeError,原因是文件读取未指定编码。通过指定utf-8编码解决了该错误,但其他地方的代码仍报同样错误。进一步调查发现Windows系统的默认编码并非utf-8。通过修改系统编码设置,问题得到彻底解决。此问题困扰博主多日,深入理解问题本质是关键。
使用mmsegmentation训练自己的数据集的过程中遇到如下一个错误
UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x8f in position 156: character maps to
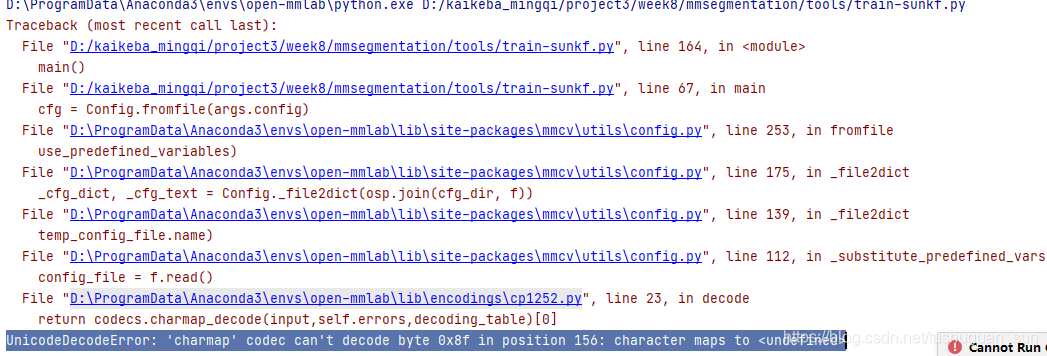
通过点击错误提示,和如下链接
https://stackoverflow.com/questions/42019117/unicodedecodeerror-charmap-codec-cant-decode-byte-0x8f-in-position-xxx-char
可以定位到是open file时没有指定编码方式,于是乎指定了utf-8编码方式,如下。
with open(filename, 'r', encoding="utf-8") as f:
config_file = f.read()
这里指定后,确实不再报错误了,但是继续运行的时候,其他地方open file的代码也报同样的错误。
我想着一个一个指定也太麻烦了,可能是我的windows电脑的默认编码方式不是utf-8的原因,于是百度怎么查看和修改windows电脑的编码方式,发现我的电脑默认编码方式果然不是utf-8,于是按照如下方式进行了设置,并解决了问题。
修改电脑的编码方式
这个问题困扰了我两三天,一直没有真正地理解问题的根本原因,直到认真看了下面链接的回答后,才慢慢理解问题的原因并想到是我电脑编码方式的原因。
https://stackoverflow.com/questions/42019117/unicodedecodeerror-charmap-codec-cant-decode-byte-0x8f-in-position-xxx-char


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









