







第一章 软件构建的观点和质量目标
第一节 多维软件视图
多维度视图Multi-dimensional software views
1.Build-time Views 构造阶段
(1) Build-time, moment, and code-level view 左上一
Source code,
AST,
Interface-Class-Attribute-Method(Class Diagram)
Lexical-based semi-structured source code 词汇层面 :
半结构化:近乎自然语言的风格+遵循特定的编程语法
前者:方便程序员
后者:方便编译器
Syntax-oriented program structure 语法层面:
AST:彻底结构化,将源代码变为一棵树
对树做各种操作==对源代码的修改
Semantics-oriented program structure 语义层面:
用UML来描述interfaces, classes, attributes,methods和它们之间的关系。
用于表达“需求”和“设计”思想,再转化成code。
(2)Build-time, period, and code-level view 右上一
Code churn 代码变化
添加,改进,或删除——使文件版本迭进
(3) Build-time, moment, and component-level view 左上二
Package, Source ,File, Static linking, Library, Test Case
(Component Diagram)
开发者像使用编程语言指令一样使用库中的功能
Sources of libraries:操作系统提供的库、编程语言提供的库、第三方公司提供的库、自己积累的库
(4) Build-time, period, and component-level view 右上二
Software Configuration Item (SCI,配置项)
Version Control System (VCS,版本控制系统)
版本控制是给计算机软件的不同状态分配唯一的名字或者编号的过程
git,github的使用。
2.Runtime Views
Code-level view 代码层面:逻辑实体在内存中如何呈现?
Component-level view 构件层面:物理实体在物理硬件环境中如何呈现?
Moment view :逻辑/物理实体在内存/硬件环境中特定时刻的形态如何?
Period view :逻辑/物理实体在内存/硬件环境中的形态随时间如何变化?
(5) Run-time, moment, and code-level view 左下一
Snapshot diagram:快照图:描述程序运行时,某时刻内存里变量层面的状态
Memory dump (内存信息转储):当进程由于某种内部错误或信号而中止时产生的硬盘上的一个文件,其中包含进程内存内容的副本。
(6) Run-time, period and code-level view 右下一
Execution tracing 执行跟踪:用日志方式记录程序执行的调用次序
(7) Run-time, period, and component-level view 左下二
Package, Library, Dynamic linking, Configuration, Database, Middleware, Network, Hardware
(Deployment Diagram)
(8) Run-time, period, and component-level view 右下二
Event log
第二节 软件系统的质量属性
内部质量/外部质量
外部质量因素影响用户,内部质量因素影响软件本身和它的开发者
外部质量取决于内部质量
外部质量因素
正确性(Correctness)
按照预先定义的“规约”执行,最重要的质量指标
每一层保证自己的正确性,同时假设其下层是正确的
防御式编程:在写程序的时候就确保正确性
specification:规约
健壮性(Robustness 鲁棒性)
健壮性是对正确性的补充
出现规约定义之外情况的时候,软件要做出恰当的反应
未被specification覆盖的情况即为“异常情况”:所谓的“异常”,取决于spec的范畴
针对异常情况处理,出现异常时不要“崩溃”
可扩展性(Extendibility):规模越大,扩展起来越不容易
可复用性(Reusability):一次开发,多次使用
兼容性(Compatibility)、性能(Efficiency)、可移植性(Portability)(Java的优点之一)、易用性(Easy of use)、功能性(Functionality)、及时性(Timeliness)
质量目标之间冲突 Tradeoff between quality properties
不同质量因素折中,但”正确性“绝不能与其他质量因素折中
正确性和健壮性:可靠性
可扩展性和可重用性:模块化
第二章 软件测试与测试优先的编程
Software Testing 软件测试
即使是最好的测试,也无法达到100%的无错误
测试(Test)
测试用例 = 输入 + 执行条件 + 期望结果
写spec -> 写符合spec的测试用例 -> 写代码执行测试反复修改
TDD(Test-driven development)
好的测试用例的特性与好的测试的特性相似
*写测试用例时必须既要考虑有效输入也要考虑无效输入
Unit testing 单元测试
针对软件的最小单元模型开展测试,隔离各个模块,容易定位错误和调试
Integration testing 集成测试
合并后的执行两个或更多的类,包,由多个程序员创建了组件、子系统或编程团队。
System testing 系统测试:
一个完全集成系统进行测试,以验证系统能否满足其需求,执行软件的最终配置。
黑盒测试/白盒测试
黑盒测试:对程序外部表现出来的行为的测试(从spec导出测试用例,不考虑内部实现)
白盒测试:考虑内部实现细节(一般较早执行)
白盒测试一般由开发人员完成
黑盒测试一般由测试人员完成
白盒测试:
- 独立/基本路径测试:
对程序所有执行路径进行等价类划分,
找出有代表性的最简单的路径(例如循环只需执行一次),
设计测试用例使每一条基本路径被至少覆盖一次。
黑盒测试:
- 通过归并选择测试用例
基于等价类划分的测试:将被测函数的输入域划分为等价类,从等价类中导出测试用例。
针对每个输入数据需要满足的约束条件,划分等价类
每个等价类代表着对输入约束加以满足/违反的有效/无效数据的集合 - 归并中包含边界
大量的错误发生在输入域的“边界”而非中央
多个划分维度上的多个取值,要组合起来,每个组合都要有一个用例
每个维度的每个取值至少被1个测试用例覆盖一次即可
回归测试
一旦程序被修改,重新执行之前的所有测试
测试用例:
输入+执行条件+期望结果
测试优先编程流程
先写spec,再写符合spec的测试用例
写代码、执行测试、有问题再改、再执行测试用例,直到通过它
使用 JUnit 进行自动化单元测试
@Test
public void testAssertArrayEquals() {
//assertArrayEquals:测试数组expected、actual是否相等(若不等,则打印参数1中的错误语句)
byte[] expected = "trial".getBytes();
byte[] actual = "trial".getBytes();
assertArrayEquals("failure - byte arrays not same", expected, actual);
}
@Test
public void testAssertEquals() { //assertEquals:测试数组是否相等,类似上面的testAssertArrayEquals
assertEquals("failure - strings are not equal", "text", "text");
}
@Test
public void testAssertFalse() {
//assertFalse:需要参数2中传入应该会返回false的函数,否则打印参数1中的错误语句
assertFalse("failure - should be false", false);
}
@Test
public void testAssertNotNull() {
//assertNotNull:需要参数2必须非空,否则打印参数1中的错误语句
assertNotNull("should not be null", new Object());
}
@Test
public void testAssertNotSame() {
//assertNotSame:需要参数2,参数3必须是不同的对象,否则打印参数1中的错误语句
assertNotSame("should not be same Object", new Object(), new Object());
}
@Test
public void testAssertNull() {
//assertNull:需要参数2必须为空,否则打印参数1中的错误语句
assertNull("should be null", null);
}
@Test
public void testAssertSame() {
//assertNotSame:需要参数2,参数3必须是相同,否则打印参数1中的错误语句
Integer aNumber = Integer.valueOf(768);
assertSame("should be same", aNumber, aNumber);
}
/* JUnit Matchers assertThat
* assertThat的几种使用方式:
* -参数1中既包括x又包括y
* -列表1中有元素x,y...
* -列表1中的元素均包含字母x...
*/
@Test
public void testAssertThatBothContainsString() {
//assertThat:参数1中既包括x又包括y
assertThat("albumen", both(containsString("a")).and(containsString("b")));
}
@Test
public void testAssertThatHasItems() {
//assertThat:列表1中有元素x,y...
assertThat(Arrays.asList("one", "two", "three"), hasItems("one", "three"));
}
@Test
public void testAssertThatEveryItemContainsString() {
//assertThat:列表1中的元素均包含字母x...
assertThat(Arrays.asList(new String[] { "fun", "ban", "net" }), everyItem(containsString("n")));
}
// Core Hamcrest Matchers with assertThat
@Test
public void testAssertThatHamcrestCoreMatchers() {
assertThat("good", allOf(equalTo("good"), startsWith("good")));
assertThat("good", not(allOf(equalTo("bad"), equalTo("good"))));
assertThat("good", anyOf(equalTo("bad"), equalTo("good")));
assertThat(7, not(CombinableMatcher.<Integer> either(equalTo(3)).or(equalTo(4))));
assertThat(new Object(), not(sameInstance(new Object())));
}
@Test
public void testAssertTrue() {
//assertTrue:参数2必须为真,否则打印错误语句
assertTrue("failure - should be true", true);
}
代码覆盖度
函数覆盖、语句覆盖、分支覆盖、条件覆盖、路径覆盖
分支覆盖和条件覆盖:分支覆盖 a && b – true/false 条件覆盖:a True a False b True b False
语句覆盖:只需要让 a && b 语句执行一遍即可
条件覆盖和分支覆盖之间没有包含关系
测试效果:路径覆盖 > 分支覆盖 > 语句覆盖(测试难度也是这个顺序)
等价类划分(重点)
基于等价类划分的测试:将被测函数的输入域划分为等价类,从等价类中导出测试用例。
针对每个输入数据需要满足的约束条件,划分等价类
(如果一组对象间存在对称、传递和自反的关系,则认为是等价类。
每个等价类代表着对输入约束加以满足/违反的有效/无效数据的集合
BVA(Boundary Value Analysis)边界值分析:是对等价类划分方法的补充
在等价类划分时,将边界作为等价类之一加入考虑(等价类划分具体写法可参见习题课)
健壮性和正确性
可靠性 = 正确性 + 健壮性
健壮性:面向用户
正确性:面向开发者
private方法可只保证正确性,但面向用户的还需要保证健壮性
第三章 构造过程与配置管理
软件的过程模型
两种基本形式:Linear-线性过程 Iterative-迭代过程
五种模型:瀑布过程、增量过程、V字过程、原型过程、螺旋模型
- 瀑布过程(Waterfall)
即简单的线性过程,阶段划分清楚,整体推进,无迭代。虽然管理简单但无法适应需求增加/变化。 - 增量过程(Incremental)
是多个瀑布的串行。要求每一段增量都是可运行的,第二个增量不能影响第一个增量(即要求接口必须简单清晰)。较容易适应需求的增加。 - V字过程(V-Model)
是瀑布过程的扩展,主要强调每一个阶段都要进行测试。 - 原型过程(Prototyping)
在原型上持续不断地迭代,发现用户的需求变化。时间代价高,开发质量也高。
迭代:开发出来之后由用户试用/评审,发现问题反馈给开发者,开发者修改原有的实现,继续交给用户评审。
适用于用户需求不稳定的情况。 缺点:可能注重原型而忽略了系统的架构设计。 - 螺旋过程(Spiral)
多轮迭代基本遵循瀑布模式,每轮迭代有明确的目标,遵循“原型”过程,进行严格的风险分析,方可进入下一轮迭代。 适用于长周期、有风险的大程序。 - 敏捷开发(Agile development)
通过快速迭代和小规模的持续改进,快速适应变化。
要求:1. 强调交互 2. 不需要文档 3. 合作 4. 变化
适用于需求不稳定,快速开发(对高质量、高风险不适用)
SCM(软件配置管理)
软件配置管理:追踪和控制软件的变化。
软件配置项:软件中发生变化的基本单元
基线:软件持续变化过程中的“稳定时刻”(例如:对外发布的版本)
CMDB:配置管理数据库
存储软件的各配置项随时间发生变化的信息+基线
VCS(版本控制系统)
版本:为软件的任一特定时刻(Moment)的形态指派一个唯一的编号,作为“身份标识”
仓库 Repository:即SCM中的CMDB
工作拷贝 Working copy:在开发者本地机器上的一份项目拷贝
文件 File:一个独立的配置项
版本 Version:在某个特定时间点的所有文件的共同状态
变化 Change:即code churn,两个版本之间的差异
HEAD:程序员正在其上工作的版本
本地版本控制系统 Local VCS :仓库存储在开发者本地,无法共享和合作。
集中式版本控制系统 Centralized VCS:仓库存储于独立的服务器,支持多开发者之间协作。
分布式版本控制系统 Distributed VCS:仓库存储于独立的服务器 + 每个开发者的本地机器。(如Git)
Git(重点)
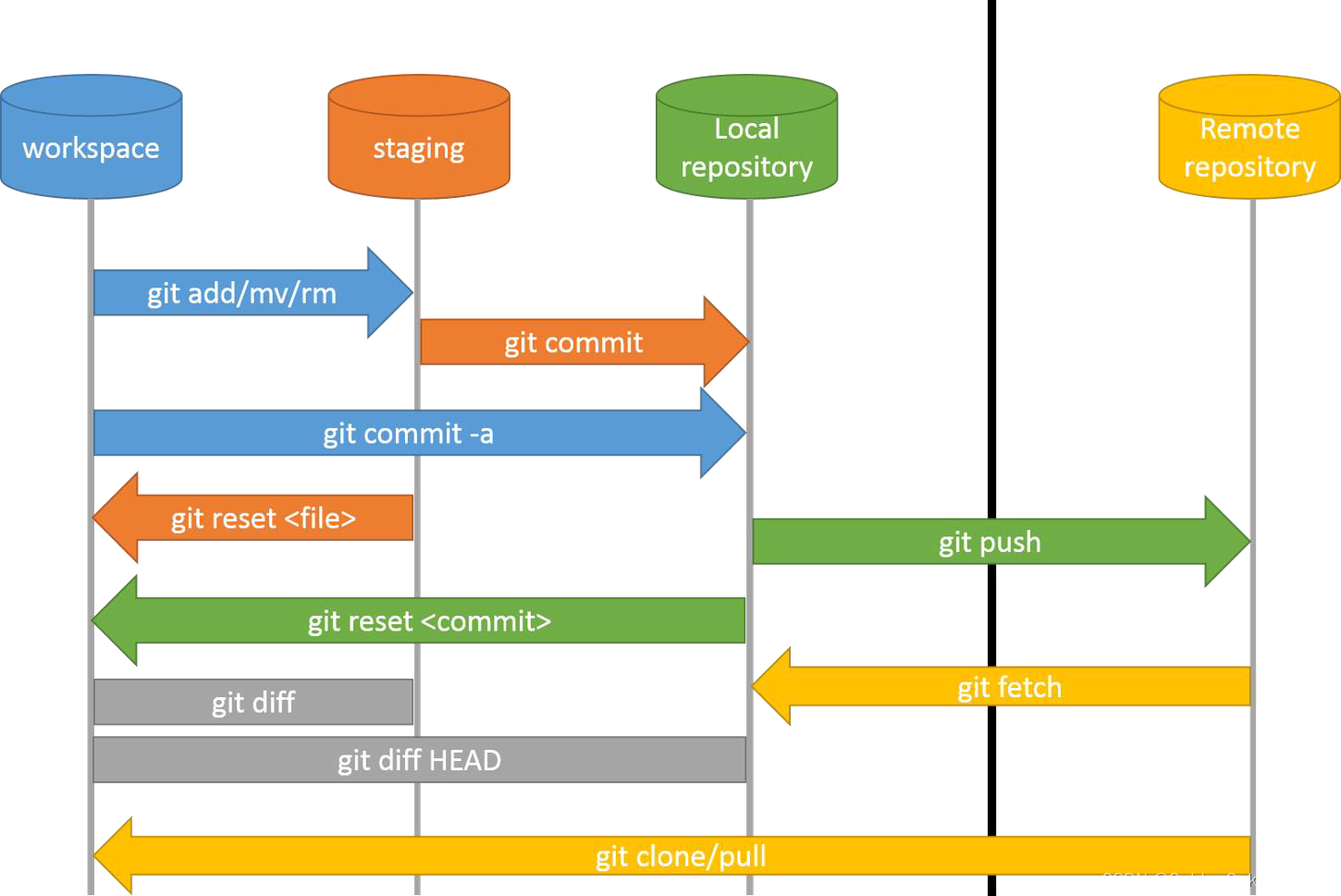
Git的四个工作区域
工作区workspace,即平时存放代码的地方。
暂存区staging,虚拟区域,无真实空间,用于临时存放改动。
本地仓库Local repository:安全存放数据的位置,里有提交到所有版本的数据
远程仓库remote repository:托管代码的服务器,如Github
需要掌握根据Git文件的状态来判断处于哪一目录/区域中。
一个Git repository有三个部分:
– .git directory (存储所有版本控制数据的存储库) 本地的CMDB
– Working directory 工作目录:本地文件系统
– Staging area (in memory) 暂存区:隔离工作目录和Git仓库
Object Graph
Git的所有操作都是在一个图数据结构(对象图)上进行
边 A -> B表示在版本B的基础上作变化形成了版本A(指向的对象是父对象)
除了最初的commit,每个commit都有一个指向父亲的指针
多个commit指向同一个父亲——分支
一个commit指向两个父亲——合并
Git中一个子对象只能有0,1,2个父对象,而一个父对象可以有多个子对象。
Git和传统版本控制工具的区别
Git存储的是变化后的文件,传统VCS存储版本之间的变化(行),很难创建分支。
文件未发生变化,则后续多个版本始终指向同一个文件
文件发生变化了,存储两份不同的文件,两个版本指向不同的文件
Git一个文件可以存在在不同的版本中。
Git命令
git commit -a :把所有的change先add然后再commit
git fetch :从远程获取最新版本到本地,不会自动merge
git checkout -b:创建并切换分支
git checkout -d:删除分支
git remote add origin … :与远程仓库关联















 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









