







1.简介
-
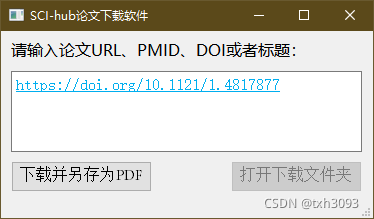
调用某-hub网站的资源,基于pyqt5实现了论文下载程序的设计。
-
通过网络爬虫获取网站的结果,并将其另存为PDF文件,另存完成后自动打开下载好的PDF。
-
使用时,优先使用DOI号或DIO地址进行搜索,成功率更高,URL和标题搜索的成功率次之。
-
本代码仅包含一个可用网址(可能随时失效),且只实现了单个文件的下载。需要通过网站实时更新可用网址或者有批量下载需求的可以联系我。
-
仅做编程交流,资源均来源于网络,如有侵权,联系删除。
2. 界面操作
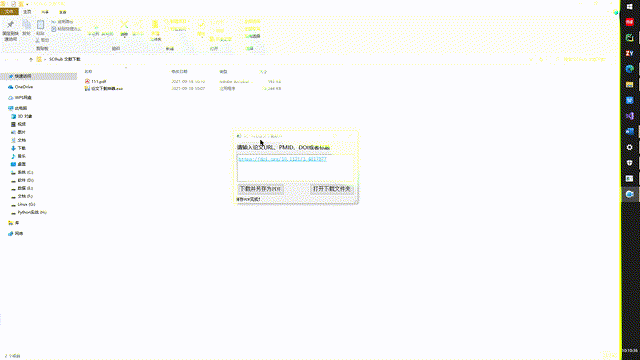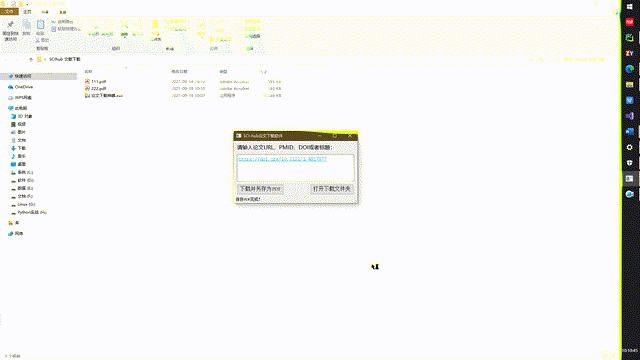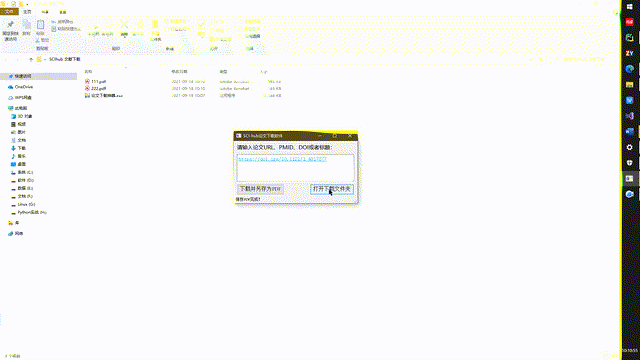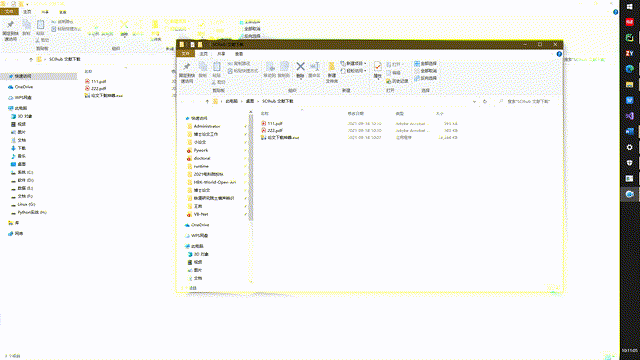
简单的操作指引如下:
3.主要代码
# _*_coding: UTF-8_*_
# 开发作者 :TXH
# 开发时间 :2021/9/17 21:06
# 文件名称 :Main.py
# 开发工具 :Python 3.7 + Pycharm IDE
import os
import sys,requests
from bs4 import BeautifulSoup
from PyQt5.QtWidgets import QApplication, QMainWindow,QFileDialog
from PyQt_Learning.SCIhub.scihub import Ui_MainWindow
from PyQt5 import QtCore,uic
from PyQt5.QtCore import QThread,pyqtSlot
class QmyWindow(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.statusBar().showMessage('Load UI...')
if 0:
self.ui = uic.loadUi('E:/Pywork/PyQt_Learning/SCI_hub/SCIhub/scihub.ui', self) #
else:
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
self.file_name = ''
self.showpdf=Openpdf()
self.ui.pushButton_2.setEnabled(False)
@pyqtSlot()
def on_pushButton_clicked(self):
artName = self.ui.textEdit.toPlainText()
try:
self.statusBar().showMessage('文件下载中...')
pdf = self.download_article(self.search_article(artName))
self.statusBar().showMessage('文件下载完成...')
self.file_name, filetype = QFileDialog.getSaveFileName(self, "另存为PDF", os.getcwd(), "PDF Files (*.pdf)")
if self.file_name == '':
self.statusBar().showMessage('请重新选择路径!')
else:
self.showpdf.filename = self.file_name
with open(self.file_name, 'wb') as f:
f.write(pdf)
self.statusBar().showMessage('保存PDF完成!')
self.showpdf.start()
self.ui.pushButton_2.setEnabled(True)
except:
self.statusBar().showMessage('当前文献下载失败!')
@pyqtSlot()
def on_pushButton_2_clicked(self): # 打开储存路径
filepath, tempfilename = os.path.split(self.file_name)
os.startfile(filepath)
def search_article(self,artName):
self.statusBar().showMessage('正在获取URL...')
url = 'https://www.sci-hub.ren/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': '123',
'Origin': 'https://www.sci-hub.ren',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'}
data = {'sci-hub-plugin-check': '',
'request': artName}
res = requests.post(url, headers=headers, data=data)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
iframe = soup.find(id='pdf')
if iframe == None: # 未找到相应文章
return ''
else:
downUrl = iframe['src']
if 'http' not in downUrl:
downUrl = 'https:' + downUrl
return downUrl
def download_article(self,downUrl):
self.statusBar().showMessage('正在下载中...')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'}
res = requests.get(downUrl, headers=headers)
return res.content
class Openpdf(QThread):
def __init__(self):
super().__init__()
self.filename = ''
@pyqtSlot()
def recv_filename(self,filename):
self.filename=filename
def run(self) -> None:
print(self.filename)
if self.filename != '':
os.startfile(self.filename)
app = QApplication(sys.argv) # 调用父类构造函数,创建窗体
form = QmyWindow() # 创建UI对象
form.show() #
sys.exit(app.exec()) #
4. 程序下载
注意:本程序仅供编程交流使用!
链接:https://pan.baidu.com/s/11-JyCK0v3Zdy5pKjLzcPuQ
提取码:vfo8
–来自百度网盘超级会员V5的分享


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











