







有表 life_unite_order 如图:
执行: select sum(unite_id),projname from life_unite_order where projname in ('凯旋大厦','双安商场') group by projname 结果为如下图:
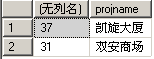
看懂没有?上面就是一个利用 group by 分组的实例 我问一下大家如果执行下面这条语句
select sum(unite_id),unite_id,projname from life_unite_order where projname in ('凯旋大厦','双安商场') group by projname,unite_id
会是什么结果呢? 呵呵! 其实会出现下面的结果如图:
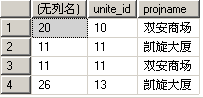
聪明的你看明白了吗? 下面介绍让人睡觉的 group by 分组理论
通过这个结果可以看出,所有的统计函数都是对查询出的每一行数据进行分类以后再进行统计计算。所以在结果集合中,对所进行分类的列的每一种数据都有一行统计结果值与之对应。
说明:GROUP BY子句中不支持对列分配的假名,也不支持任何使用了统计函数的集合列。另外,对SELECT后面每一列数据除了出现在统计函数中的列以外,都必须在GROUP BY子句中应用。
GROUP BY 子句用来为结果集中的每一行产生聚合值。如果聚合函数没有使用 GROUP BY 子句,则只为 SELECT 语句报告一个聚合值。
当 SELECT 语句中包含 GROUP BY 关键字时,对可以在选择列表中指定的项有一些限制。在该选择列表中所允许的项目是:
- 分组列。
- 为分组列中的每个值只返回一个值的表达式,例如将列名作为其中一个参数的聚合函数。这些函数称为矢量聚合。
大家睡着了吧?















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









