







 本文介绍了阿里巴巴2018KDD论文中的ID表示方法在盒马生鲜推荐系统中的应用,包括item ID, 属性ID和user ID的embedding学习,以及如何解决item和user的冷启动问题。盒马利用item相似度进行推荐,并通过淘宝用户数据进行迁移学习,以应对新用户和新品的推荐挑战。"
79314107,7369662,图的深度/广度优先遍历解析,"['数据结构', '图论', '算法', '遍历']
本文介绍了阿里巴巴2018KDD论文中的ID表示方法在盒马生鲜推荐系统中的应用,包括item ID, 属性ID和user ID的embedding学习,以及如何解决item和user的冷启动问题。盒马利用item相似度进行推荐,并通过淘宝用户数据进行迁移学习,以应对新用户和新品的推荐挑战。"
79314107,7369662,图的深度/广度优先遍历解析,"['数据结构', '图论', '算法', '遍历']
原文地址:盒马生鲜是根据什么进行推荐的?——IDs Representation in E-commerce(阿里2018KDD)
欢迎关注我的公众号,微信搜 algorithm_Tian 或者扫下面的二维码~
现在保持每周更新的频率,内容都是机器学习相关内容和读一些论文的笔记,欢迎一起讨论学习~

去年的时候介绍了很多embedding相关的方法和论文,这篇阿里在2018KDD的文章算是一个比较巧妙的对ID进行embedding的方法。
文章全称为:
Learning and Transferring IDs Representation in E-commerce
论文介绍的方法应用在了盒马生鲜app上,涉及推荐及解决冷启动问题。
本博文分以下几方面来介绍这篇论文:
-
背景知识(盒马的推荐系统、id之间的属性关系)
-
模型介绍(item id和属性id还有user id)
-
在盒马中的应用(item相似性推荐、item冷启动、不同平台user迁移学习、多任务)
-
总结
1. 背景知识
在线购物平台的数据里,有一些无序的离散特征,也就是ID,比如商品ID、商品的分类ID、用户ID、商户ID、品牌ID等等。不同的ID之间存在一定关系,所以把ID视作特征加入一些模型中是有一定意义的。但是传统的处理的id特征的方法存在两个问题:
(1)大部分ID是以one hot形式加入模型,高维稀疏
(2)不能反映ID之间的一些关系,无论是在同一空间(如品牌这一层次空间内部)还是不同空间(如品牌和商品这种不同空间)
于是作者就想到了NLP中,也是把离散的词语经过学习映射到低维的稠密空间中,并且在这个空间中,可以获取到这些词语语义上的关联。那么如果将这些离散的ID视作word2vec中的词语,构建一种输入形式,是不是就可以为每个ID学习出一个低维稠密向量?
于是文章提出了一种item2vec方法,以item id的embedding学习为基础,同时训练所有其他属性的embedding,最后再根据用户点击的item序列计算user id的embedding。
各类ID之间的关系如下图所示:
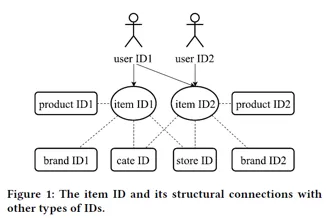
可以看到,一个user ID1,他可能点击了item ID1和item ID2,其中item ID1拥有属性product ID1、brand ID1、cate ID1和store ID1。
文章提出的方法会应用在盒马生鲜app中,盒马的页面如下所示,一般item其实就是具体的某个商品。
下面的介绍是文章中提到的盒马中的挑战和推荐流程,不太感兴趣的同学可以跳过不看,不影响模型方法的理解学习。
用户可以按照类别浏览商品或者在推荐列表中看到商品。在盒马的应用场景中,有几大挑战:
(1)盒马卖的是时令生鲜,所以商品更换很频繁,面临冷启
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









