







概述
Flume 除了主要的三大组件 Source、Channel和 Sink,还有一些其他灵活的组件,如拦截器、SourceRunner运行器、Channel选择器和Sink处理器等。
组件框架图
今天主要来看看拦截器,先看下组件框架流程图,熟悉了大致框架流程学习起来必然会更加轻松:
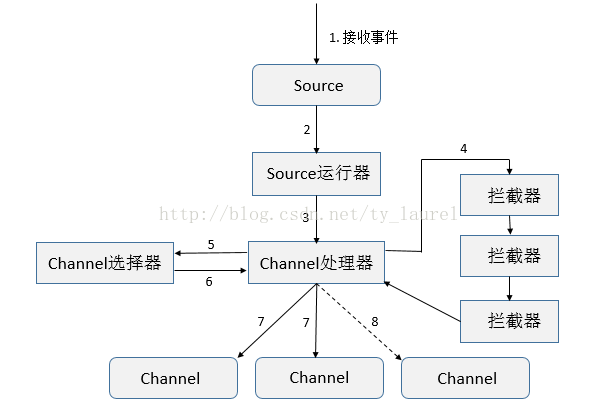
- 接收事件
- 根据配置选择对应的Source运行器(EventDrivenSourceRunner 和 PollableSourceRunner)
- 处理器处理事件(Load-Balancing Sink 和 Failover Sink 处理器)
- 将事件传递给拦截器链
- 将每个事件传递给Channel选择器
- 返回写入事件的Channel列表
- 将所有事件写入每个必需的Channel,只有一个事务被打开
- 可选Channel(配置可选Channel后不管其是否写入成功)
拦截器
拦截器(Interceptor)是简单插件式组件,设置在Source和Channel之间,Source接收到event在写入到对应的Channel之前,可以通过调用的拦截器转换或者删除过滤掉一部分event。通过拦截器后返回的event数不能大于原本的数量。在一个Flume 事件流程中,可以添加任意数量的拦截器转换或者删除从单个Source中来的事件,Source将同一个事务的所有事件event传递给Channel处理器,进而依次可以传递给多个拦截器,直至从最后一个拦截器中返回的最终事件event写入到对应的Channel中。
flume-1.7版本支持的拦截器:
编写自定义拦截器
自定义的拦截器编写,我们只需要实现一个Interceptor接口即可,该接口的定义如下:
public interface Interceptor {/* 任何需要拦截器初始化或者启动的操作就可以定义在此,无则为空即可 */public void initialize();/* 每次只处理一个Event */public Event intercept(Event event);/* 量处理Event */public List<Event> intercept(List<Event> events);/*需要拦截器执行的任何closing/shutdown操作,一般为空 */public void close();/* 获取配置文件中的信息,必须要有一个无参的构造方法 */public interface Builder extends Configurable {public Interceptor build();}}
接口中的几个方法或者内部接口含义代码中已经标注,需要留意的地方就是考虑到多线程运行Source时,需要保证编写的代码是线程安全的。这里就不展示自定义拦截器代码了,仿照已有的拦截器,可以很容易的编写一个简单功能的自定义拦截器的。
实际使用及问题
问题:
目前环境中使用的都是tailSource、hdfsSink,在sink时根据时间对日志分割成不同的目录,但是实际过程中存在一些延迟,导致sink写入hdfs时的时间和日志文件中记录的时间存在一些差异;并且不能保留原有的日志文件名。
需求:
- 根据日志中记录的时间对文件进行分目录存储
- 将source端读取的日志名字符串添加至hdfsSink写入hdfs的文件名中(在hdfs文件中可以根据文件名区分日志)
日志格式如下:
2017/01/13 13:30:00 ip:123.178.46.252 message:[{ "s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":2017/01/13 14:50:00 ip:123.178.46.252 message:[{ "s":"bbceif1484117100097","u":"354910072847819","id":"2x1kfBk63z","e":
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









